3.3 RETRIEVAL OF GENETIC INFORMATION STORED IN DNA: TRANSCRIPTION
Although the three-dimensional structure of DNA gave important clues about how DNA stores and transmits information, it left open many questions about how the genetic information in DNA is read out to control cellular processes. In 1953, when the double helix was discovered, virtually nothing was known about these processes. Within a few years, however, evidence was already accumulating that DNA carries the genetic information for proteins, and that proteins are synthesized on particles in the cytoplasm called ribosomes. But ribosomes contain no DNA! There must therefore be an intermediary molecule by which the genetic information is transferred from the DNA to the ribosome, and some researchers began to suspect that this intermediary was another type of nucleic acid called ribonucleic acid (RNA).
This hypothesis was supported by a clever experiment carried out in 1961 by Sydney Brenner, François Jacob, and Matthew Meselson. They used the virus T2, which infects cells of the bacterium Escherichia coli and hijacks the cellular machinery to produce viral proteins. The researchers showed that, shortly after infection and before viral proteins are made, the infected cells produce a burst of RNA molecules that correspond to the viral DNA. This finding and others suggested that RNA is used to retrieve the genetic information stored in DNA for use in protein synthesis. The transfer of genetic information from DNA to RNA constitutes the key step of transcription in the central dogma of molecular biology (see Fig. 3.2). In this section, we examine RNA and the process of transcription.
3.3.1 What was the first nucleic acid molecule, and how did it arise?
Case 1 The First Cell: Life's Origins
RNA is a remarkable molecule. Like DNA, it is able to store information in its sequence of nucleotides. In addition, some RNA molecules can actually act as enzymes that facilitate chemical reactions. Because RNA has properties of both DNA (information storage) and proteins (enzymes), many scientists think that RNA, not DNA, was the original information-storage molecule in the earliest forms of life on Earth. This idea, sometimes called the RNA world hypothesis, is supported by other evidence as well. Notably, as we will see, RNA is used in key cellular processes, including DNA replication, transcription, and translation. Many scientists believe that this involvement is a remnant of a time when RNA played a more central role in life’s fundamental processes.
3-11
In addition, ingenious experiments show how RNA could have evolved the ability to catalyze a simple reaction. A strand of RNA was synthesized in the laboratory and then replicated many times to produce a large population of identical RNA molecules. Next, the RNA was exposed to a chemical that induced random changes in the identity of some of the nucleotides in these molecules. These random changes were mutations that created a population of diverse RNA molecules, much in the way that mutation builds genetic variation in cells.
Next, all of these RNA molecules were placed into a container, and those RNA variants that successfully catalyzed a simple reaction—cleaving a strand of RNA, for example, or joining two strands together—were isolated, and the cycle was repeated. In each round of the experiment, the RNA molecules that functioned best were retained, replicated, subjected to treatments that induced additional mutations, and then tested for the ability to catalyze the same reaction. With each generation, the RNA catalyzed the reaction more efficiently, and after only a few dozen rounds of the procedure, very efficient RNA catalysts had evolved. Experiments such as this one suggest that RNA molecules can evolve over time and act as catalysts. Therefore, many scientists believe that RNA, with its dual functions of information storage and catalysis, was a key molecule in the very first forms of life.
If RNA played a key role in the origin of life, why do cells now use DNA for information storage and proteins to carry out other cellular processes? RNA is much less stable than DNA, and proteins are more versatile, so a plausible explanation is that life evolved from an RNA-based world to one in which DNA, RNA, and proteins are specialized for different functions.
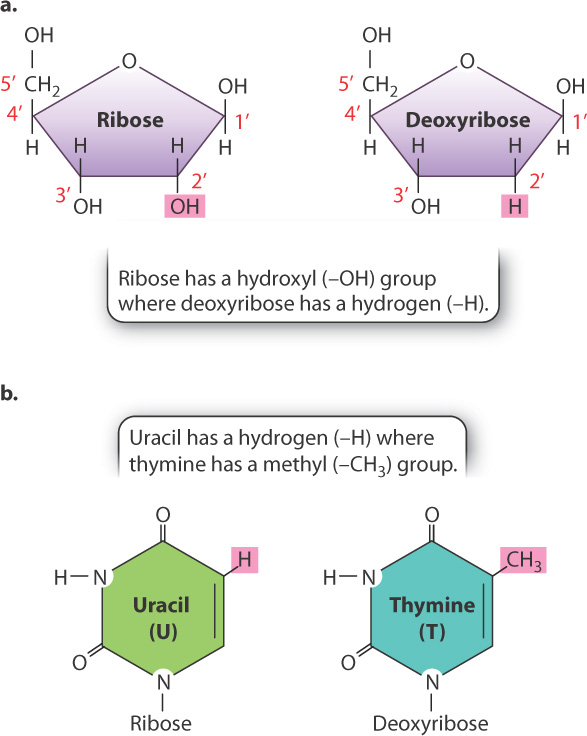
RNA is a polymer of nucleotides linked by phosphodiester bonds, similar to those in DNA (see Fig. 3.7). Each RNA strand therefore has a polarity determined by which end of the chain carries the 3′ hydroxyl (–OH) and which end carries the 5′ phosphate. There are a number of important differences that distinguish RNA from DNA, however (Fig. 3.14). First, the sugar in RNA is ribose, which carries a hydroxyl group on the 2′ carbon (Fig. 3.14a). Hydroxyls are reactive functional groups, so the additional hydroxyl group on ribose in part explains why RNA is a less stable molecule than DNA. Second, the base uracil found in RNA replaces thymine found in DNA (Fig. 3.14b). The groups that participate in hydrogen bonding (highlighted in pink in Fig. 3.14b) are identical so that uracil pairs with adenine (U–A) just as thymine pairs with adenine (T–A). Third, while the 5′ end of a DNA strand is typically a monophosphate, the 5′ end of an RNA molecule is typically a triphosphate.
Two other features that distinguish RNA from DNA are physical rather than chemical. One is that RNA molecules are usually much shorter than DNA molecules. A typical RNA molecule used in protein synthesis consists of a few thousand nucleotides, whereas a typical DNA molecule consists of millions or tens of millions of nucleotides. The other major distinction is that most RNA molecules in the cell are single stranded, whereas DNA molecules, as we saw, are double stranded. Single-stranded RNA molecules often form complex three-dimensional structures by folding back upon themselves, which enhances their stability.
3.3.2 In transcription, DNA is used as a template to make complementary RNA.
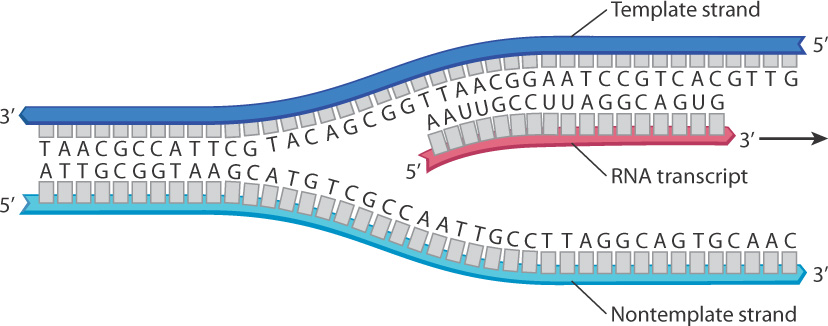
Conceptually, the process of transcription is straightforward. As a region of the DNA duplex unwinds, one strand is used as a template, or pattern, for the synthesis of an RNA transcript that is complementary in sequence to the template according to the base-pairing rules, except that the transcript contains U (uracil) where the template has an A (Fig. 3.15). The transcript is produced by polymerization of ribonucleoside triphosphates. The enzyme that carries out the polymerization is known as RNA polymerase, which acts by adding successive nucleotides to the 3′ end of the growing transcript (Fig. 3.15). Only the template strand of DNA is transcribed. Its partner, called the nontemplate strand, is not transcribed.
3-12
It is important to keep in mind the direction of growth of the RNA transcript and the direction that the DNA template is read. All nucleic acids are synthesized by addition of nucleotides to the 3′ end. That is, they grow in a 5′-to-3′ direction, also described simply as the 3′ direction. Because of the antiparallel nature of the DNA–RNA duplex, the DNA template that is being transcribed runs in the opposite direction, from 3′ to 5′ (Fig. 3.15).
Question Quick Check 2
T4XKO1nky+uFlmLVYK1JPGxjgKuojJCtofgBntDFsPVKL1v5EZM3qaz9/iV8nRzFx8z3OEFXW2R5pAnfrt8yMcMfWnSFTf7VnATt4RGqshDbNB9VdyreckeEBCITa3/Br3ixkD1StD+0hEYQJ8KIiBKqPEUErdEuZuTPODHNZcQcjW6QlSsaBwV/W/zcgRFoBjEpHe7G0cU2NUVhplmQkAMlVRwOX8c0pFsbiM3a2WDAX7hZ3.3.3 Transcription starts at a promoter and ends at a terminator.
A long DNA molecule typically contains thousands of genes, most of them coding for proteins or RNA molecules with specialized functions, and hence thousands of different transcripts are produced. For example, the DNA molecule in the bacterium E. coli has about 4 million base pairs and produces about 4000 transcripts, most of which code for proteins. A typical map of a small part of a long DNA molecule is shown in Fig. 3.16. Each green segment indicates the position where a transcription is initiated, and each purple segment indicates the position where it ends.
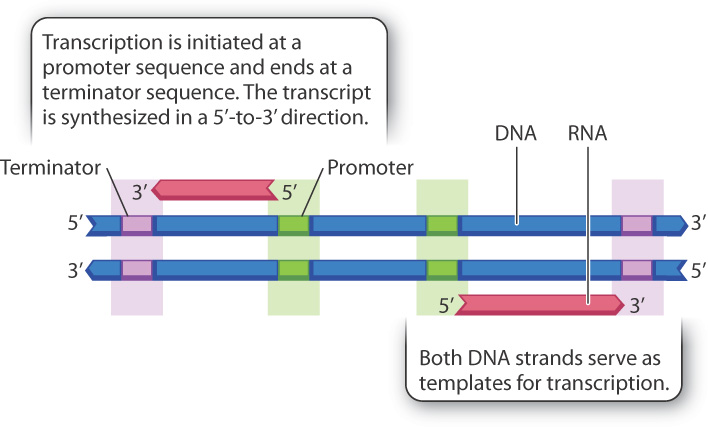
The green segments are promoters, regions of typically a few hundred base pairs where RNA polymerase and associated proteins bind to the DNA duplex. Many eukaryotic and archaeal promoters contain a sequence similar to 5′-TATAAA-3′, which is known as a TATA box because the TATA sequence is usually present. The first nucleotide to be transcribed is usually positioned about 25 base pairs from the TATA box, and transcription takes place as the RNA polymerase moves along the template strand in the 3′-to-5′ direction.
Transcription continues until the RNA polymerase encounters a sequence known as a terminator (shown in purple in Fig. 3.16). Transcription stops at the terminator, and the transcript is released. Transcripts from a DNA duplex may be produced from either strand, depending on the orientation of the promoter. As shown in Fig. 3.16, promoters oriented in one direction result in transcription from right to left (top strand), whereas those oriented in the reverse direction result in transcription from left to right (bottom strand). Orientation matters, as noted earlier, because transcription can proceed only by successive addition of nucleotides to the 3′ end of the transcript.
Transcription does not take place indiscriminately from promoters but is a regulated process. For genes called housekeeping genes, whose products are needed at all times in all cells, transcription takes place continually. But most genes are transcribed only at certain times, under certain conditions, or in certain cell types. In E. coli, for example, the genes that encode proteins needed to utilize the sugar lactose (milk sugar) are transcribed only when lactose is present in the environment. For such genes, regulation of transcription often depends on whether the RNA polymerase and associated proteins are able to bind with the promoter.
In bacteria, promoter recognition is mediated by a protein called sigma factor, which associates with RNA polymerase and facilitates its binding to specific promoters. One primary sigma factor is used for transcription of housekeeping genes and many others, but there are other sigma factors for genes whose expression is needed under special environmental conditions such as lack of nutrients or excess heat.
3-13
Promoter recognition in eukaryotes is considerably more complicated. Transcription requires the combined action of at least six proteins known as general transcription factors that assemble at the promoter of a gene. The general transcription factors attract, or recruit, the RNA polymerase and its associated proteins to the site (Fig. 3.17). Cells have several different types of RNA polymerase enzymes, but in both prokaryotes and eukaryotes all protein-coding genes are transcribed by just one of them. In eukaryotes, the RNA polymerase complex responsible for transcription of protein-coding genes is called Pol II.
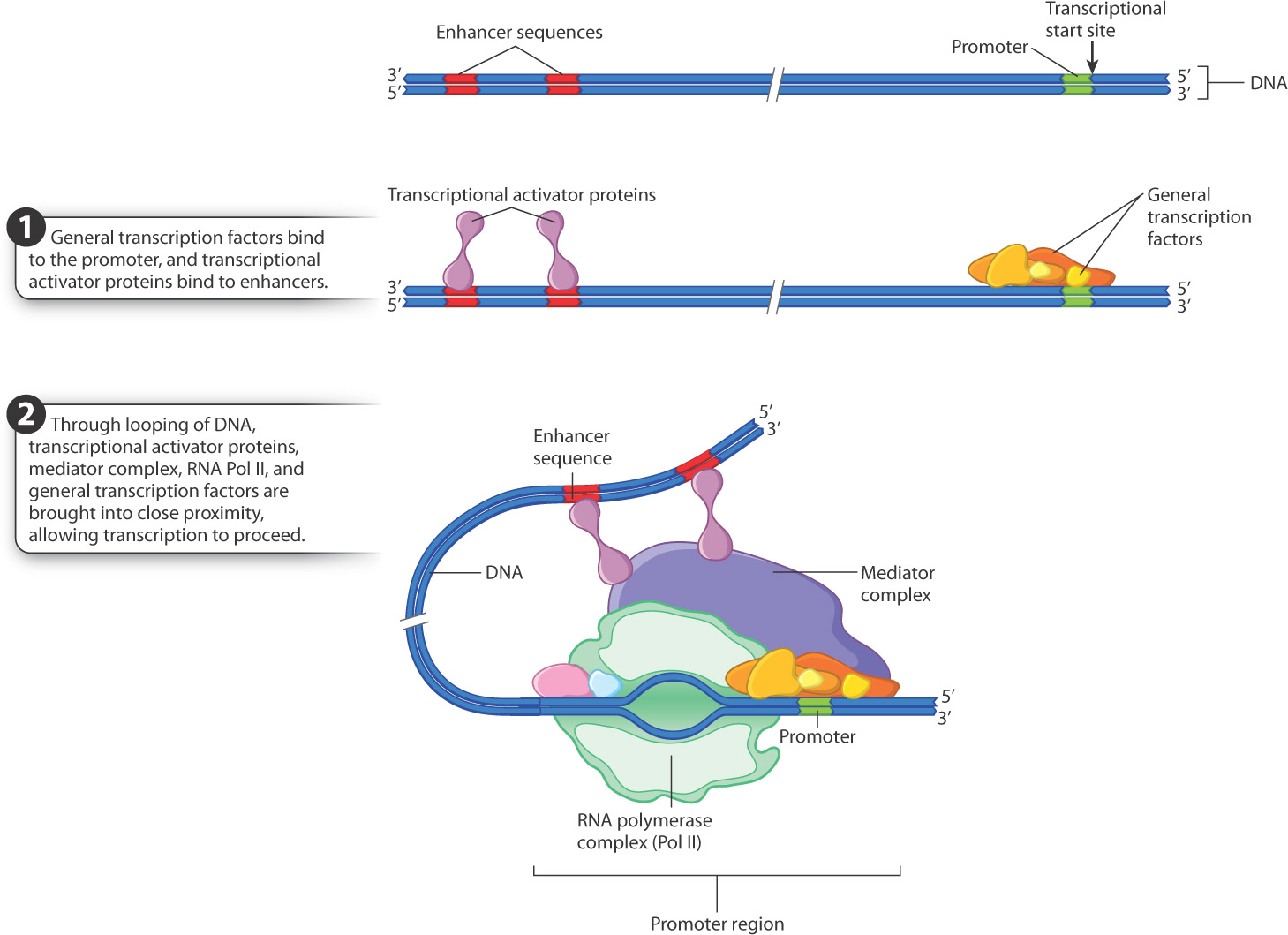
Assembly of the general transcription factors with the RNA polymerase complex is necessary for transcription to occur, but not sufficient. Also needed is the presence of one or more types of transcriptional activator protein, each of which binds to a specific DNA sequence known as an enhancer (Fig. 3.17). The transcriptional activator proteins recruit a mediator complex of proteins, which in turn interacts with the Pol II complex, and transcription begins. The initiation of transcription of any gene therefore depends on the availability of the transcriptional activator proteins that bind with the enhancers controlling the expression of the gene.
3.3.4 RNA polymerase adds successive nucleotides to the 3′ end of the transcript.
Transcription actually takes place in a sort of bubble in which the strands of the DNA duplex are separated and the growing end of the RNA transcript is paired with the template strand, creating an RNA–DNA duplex (Fig. 3.18). In bacteria, the total length of the transcription bubble is about 14 base pairs, and the length of the RNA–DNA duplex in the bubble is about 8 base pairs.
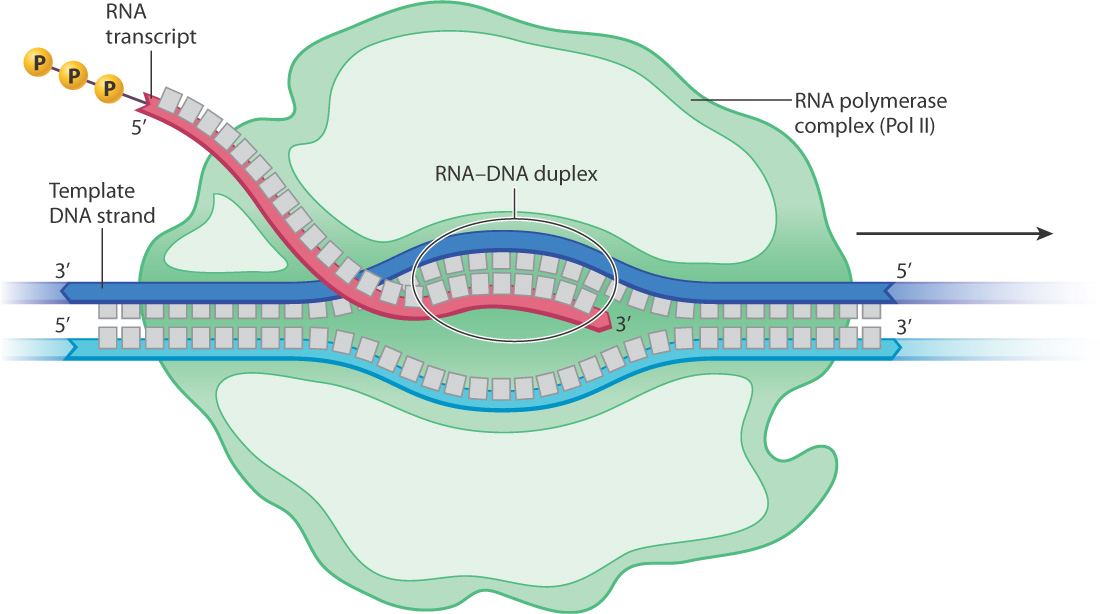
3-14
Details of the polymerization reaction are shown in Fig. 3.19. The incoming ribonucleoside triphosphate, shown at the bottom right, is accepted by the RNA polymerase only if it undergoes proper base pairing with the base in the template DNA strand. In Fig. 3.19, there is a proper match because U pairs with A. At this point, the RNA polymerase orients the oxygen in the hydroxyl group at the 3′ end of the growing strand into a position from which it can attack the innermost phosphate of the triphosphate, competing for the covalent bond. The bond connecting the innermost phosphate to the next is a high-energy phosphate bond, which when cleaved provides the energy to drive the reaction that creates the phosphodiester bond attaching the incoming nucleotide to the 3′ end of growing chain. The term “high-energy” here refers to the amount of energy released when the phosphate bond is broken that can be used to drive other chemical reactions.
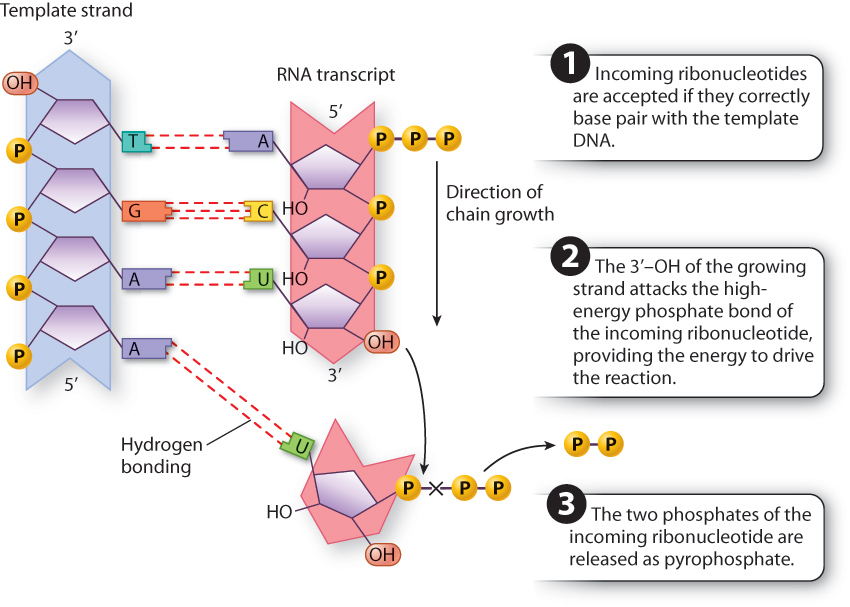
The polymerization reaction releases a phosphate–phosphate group (pyrophosphate), shown at the lower right in Fig. 3.19, which also has a high-energy phosphate bond that is cleaved by another enzyme. Cleavage of the pyrophosphate molecule makes the polymerization reaction irreversible, and the next ribonucleoside triphosphate that complements the template is brought into line.
Question Quick Check 3
uNJyROiZ3FTo7AUCFmLZhnevaEafYSQ5fR0NyWSHC/iTZMyOY7zcDPdjOnaiykzMqoeHQ450rRMilYv56vkN28YY/yAt16z09lii635KTXEtB7sOjopUCo/BY3QqHRZL9PYg6RQPh1iUraYlsavdJBub/9FrmNi9yAOTNeKGDh9/7EYzfmkj1+sEC1vcM2U26xlnTsWz/7qb03DrT502ODqnD4JGUlR0FX0mvqJm6XZgMOqP0VfVgWO+0C+Nn3Kdkxf7qZxsBCbbJPr93-15
3.3.5 The RNA polymerase complex is a molecular machine that opens, transcribes, and closes duplex DNA.
Transcription does not take place spontaneously. It requires template DNA, a supply of ribonucleoside triphosphates, and RNA polymerase, a large multiprotein complex in which transcription occurs. To illustrate RNA polymerase in action, we consider here bacterial RNA polymerase because of its relative simplicity.
The transcription bubble forms and transcription takes place in the polymerase (Fig. 3.20). RNA polymerase contains structural features that separate the DNA strands, allow an RNA–DNA duplex to form, elongate the transcript nucleotide by nucleotide, release the finished transcript, and restore the original DNA double helix. Fig. 3.20 shows how structure and function come together in the bacterial RNA polymerase.
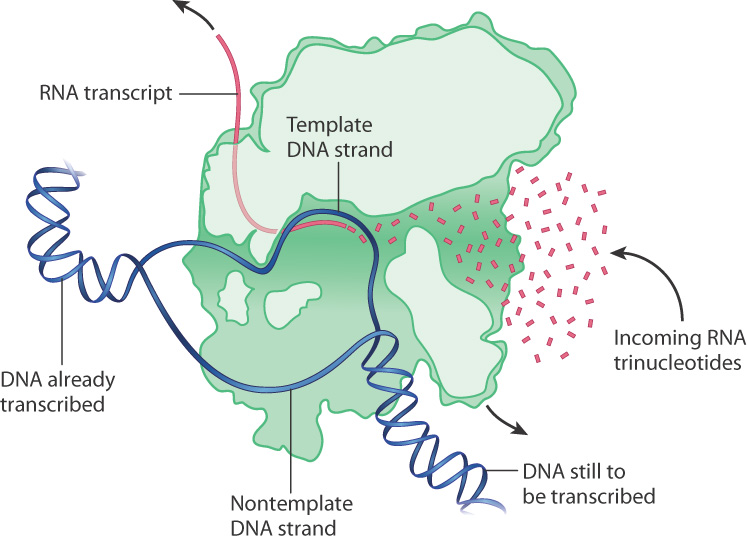
DNA enters the polymerase through a channel and is threaded out another channel via a structure that splits the strands apart, forming a bubble, so that ribonucleotides can assemble on the template strand. Another part of the enzyme forces the growing RNA out a different channel. As the DNA travels through the RNA polymerase, the RNA transcript is elongated at the active site of the enzyme as successive ribonucleotides are added to its 3′ end.
RNA polymerase is a remarkable molecular machine capable of adding thousands of nucleotides to a transcript before dissociating from the template. It is also very accurate, with only about 1 incorrect nucleotide incorporated per 10,000 nucleotides.