12.1 DNA REPLICATION
You may recall from Chapter 3 that double-stranded DNA consists of a pair of deoxyribonucleotide polymers wound around each other in antiparallel helical coils in such a way that, across the center of the double helix, a purine base (A or G) in one strand is paired with a pyrimidine base (T or C, respectively) in the other strand. To say that the strands are antiparallel means that the 3′ hydroxyl of any deoxyribose sugar in the backbone of one strand is opposite the 5′ phosphate group of the corresponding deoxyribose sugar in the backbone across the way. These key elements of DNA structure are the only essential pieces of information needed to understand the mechanism of DNA replication.
12-2
12.1.1 During DNA replication, the parental strands separate and new partners are made.
When Watson and Crick published their paper describing the structure of DNA, they also coyly laid claim to another discovery: “It has not escaped our notice that the specific pairing we have postulated [A with T, and G with C] immediately suggests a copying mechanism for the genetic material.” The copying mechanism they had in mind is exquisitely simple. The two strands of the parental duplex molecule separate (Fig. 12.1), and each individual parental strand serves as a model, or template strand, for the synthesis of a daughter strand. As each daughter strand is synthesized, the order of the bases in the template strand determines the order of the complementary bases added to the daughter strand. For example, the sequence 5′-ATGC-3′ in the template strand specifies the sequence 3′-TACG-5′ in the daughter strand because A pairs with T and G pairs with C. (The designations 3′ and 5′ convey the antiparallel orientation of the strands.)
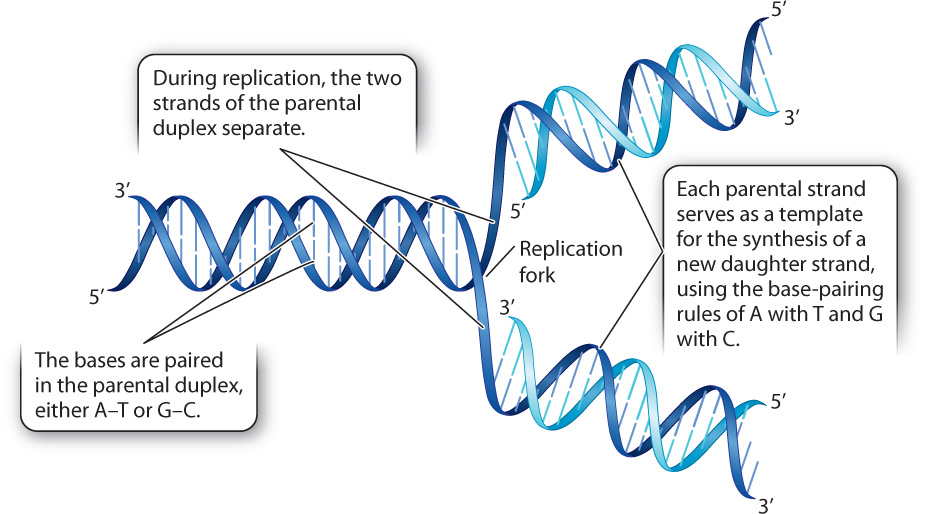
A key prediction of the model shown in Fig. 12.1 is semiconservative replication. That is, after replication, each new DNA duplex will consist of one strand that was originally present in the parental duplex and one newly synthesized strand. An alternative model is conservative replication, which proposes that the original DNA duplex remains intact and the daughter DNA duplex is completely new. The correct model cannot be determined without knowing just how DNA is replicated. If there were a way to distinguish newly synthesized daughter DNA strands (“new strands”) from previously synthesized parental strands (“old strands”), the products of replication could be observed and the mode of replication determined.
The American molecular biologists Matthew S. Meselson and Franklin W. Stahl carried out an experiment to determine how DNA replicates. This experiment, described in Fig. 12.2, has been called “the most beautiful experiment in biology” because it so elegantly demonstrated the scientific method (Chapter 1) of hypothesis, prediction, and experimental test. They distinguished “old” from “new” DNA strands by labeling them with different isotopes of nitrogen, either the normal form of nitrogen 14N or a heavier form with an extra neutron, denoted 15N.
FIG. 12.2: How is DNA replicated?
BACKGROUND Watson and Crick’s discovery of the structure of DNA in 1953 suggested a mechanism by which DNA is replicated. Experimental evidence came with research by American molecular biologists Matthew Meselson and Franklin Stahl in 1958.
HYPOTHESIS DNA replicates in a semiconservative manner, meaning that each new DNA molecule consists of one parental strand and one newly synthesized strand.
ALTERNATIVE HYPOTHESIS DNA replicates in a conservative manner, meaning that one DNA molecule consists of two parental strands, and the other consists of two newly synthesized strands.
METHOD Meselson and Stahl distinguished parental strands (“old”) from newly synthesized strands (“new”) using two isotopes of nitrogen atoms. Old strands were labeled with a heavy form of nitrogen with an extra neutron (15N), and new strands were labeled with the normal, lighter form of nitrogen (14N).
EXPERIMENT The researchers first grew bacterial cells on medium containing only the heavy 15N form of nitrogen. As the cells grew, 15N was incorporated into the DNA bases, resulting, after several generations, in DNA containing only 15N. They then transferred the cells into medium containing only light 14N nitrogen. After one round of replication in this medium, cell replication was halted. The researchers could not observe the DNA directly, but instead they measured the density of the DNA by spinning it in a high-speed centrifuge in tubes containing a solution of cesium chloride.
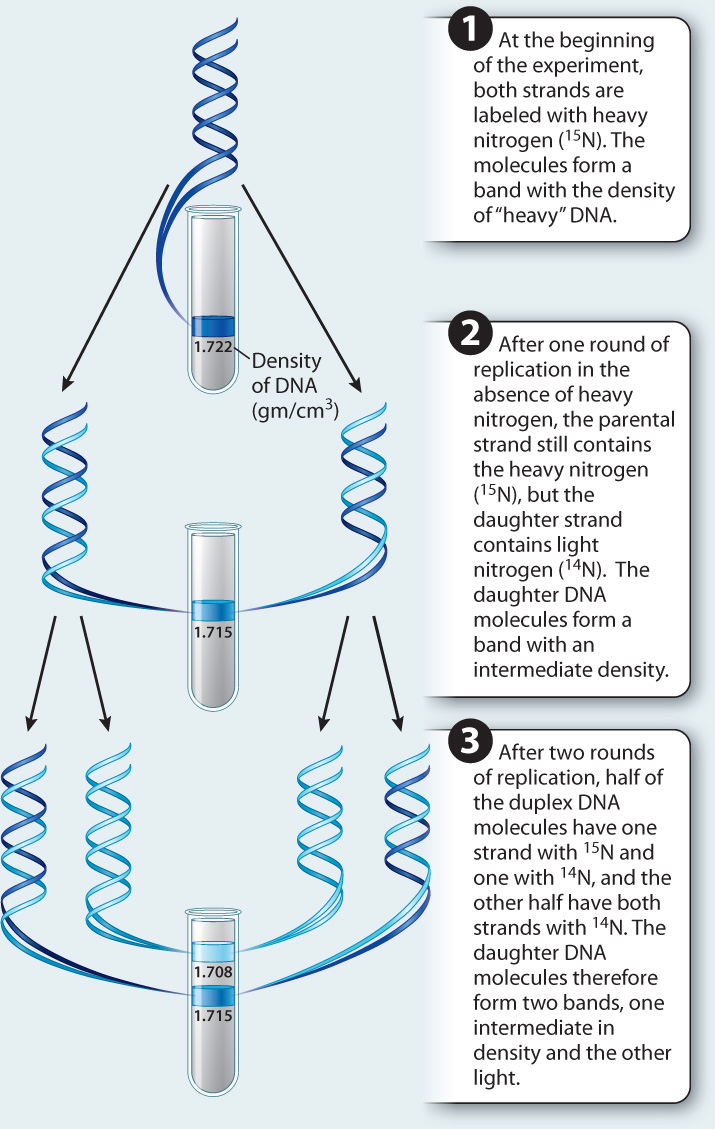
PREDICTION If DNA replicated conservatively, half of the DNA in the cells should be composed of two heavy parental strands containing 15N, and half should be composed of two light daughter strands containing 14N. If DNA replicated semiconservatively, the daughter DNA molecules should each consist of one heavy strand and one light strand.
RESULTS When the fully 15N-labeled parental DNA was spun, it concentrated in a single heavy band with a density of 1.722 gm/cm3. After one round of replication, the DNA formed a band at a density of 1.715 gm/cm3, which is the density expected of a duplex molecule containing one heavy (15N-labeled) strand and one light (14N-labeled) strand. DNA composed only of 14N would have a density of 1.708 gm/cm3. After two rounds of replication, half the molecules exhibited a density of 1.715 gm/cm3, indicating a duplex molecule with one heavy strand and one light strand, and the other half exhibited a density of 1.708 gm/cm3, indicating a duplex molecule containing two light strands.
CONCLUSION DNA replicates semiconservatively, supporting the first hypothesis.
SOURCE Meselson, M., and F. W. Stahl. 1958. “The Replication of DNA in Escherichia coli.” PNAS 44:671–82.
Meselson and Stahl’s finding that DNA replicates semiconservatively (Fig. 12.2) also predicted the results when cells are allowed to undergo two rounds of replication in a medium containing only light 14N nitrogen. The heavy strand and light strand each serve as templates for a new light daughter strand. The result is that half of the DNA molecules will have one heavy old strand and one light new strand and an intermediate density, and half of the DNA molecules will have one light old strand and one light new strand and a low density. This is precisely what they observed (Fig. 12.2).
12-3
Question Quick Check 1
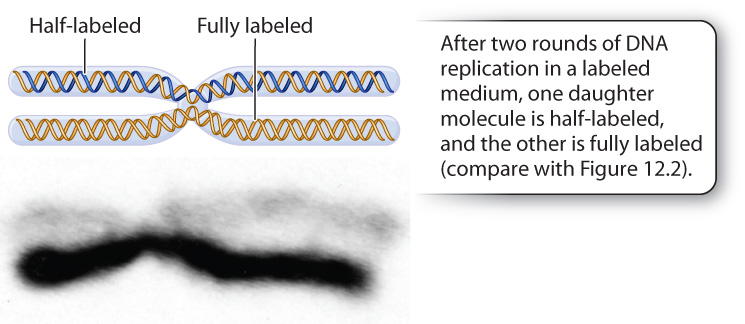
DbtLUyUpEC9duRQZt+ep4LWygwP+IFbPXoQCn4oa/eDn1Ao8qEsaOnEg1frfEFgP6PDYTuCM0/ATzStWHqfAIORk4d2RhUjlmR6TSlgVDQeNJB00Tgn6N1NIWk2z78Oh5jXCascQZY3OwGnoqZ80RBn7fKzTNzyZYNVXhBWWsOVtqW5PWNALoN9naD/HtEtZ2Gns2OVTRlOQxgWidcJtDDsjxT7dFJvaDyyUtuZQGkdbNNyJ6YsqHHQWIi0kdn73eyZB2/MTkgx+7umpc2QrasolFltwYt6SE+ktq+frOcC8gw0hgbVCQybUe4Ksk9YmzRGnK4x8Nu7I40YIAkcPXGPk93zz7JD13YEJYbX/pe+eIt0LAoD4+06lDHRPyYdx02vM3BQtTOohG07ilhlVpCE2e6EI8qWeImportant as it was in demonstrating semiconservative replication in bacteria, the Meselson–Stahl experiment left open the possibility that DNA replication in eukaryotes might be different. It was only some years after the Meselson–Stahl experiment that methods for labeling DNA with fluorescent nucleotides were developed. These methods allowed researchers to visualize entire strands of eukaryotic DNA and follow each strand through replication. Fig. 12.3 shows a human chromosome with unlabeled DNA that subsequently underwent two rounds of replication in medium containing a fluorescent nucleotide. The chromosome was photographed at metaphase of mitosis, after chromosome duplication but before the separation of the chromatids into the daughter cells. Notice that one chromatid contains hybrid DNA with one labeled strand and one unlabeled strand, which fluoresces faintly (light); the other chromatid contains two strands of labeled DNA, which fluoresces strongly (dark). This result is conceptually the same as what was seen by Meselson and Stahl after two rounds of replication and exactly as predicted by the semiconservative replication model. The result also demonstrates that each eukaryotic chromosome contains a single DNA molecule that runs continuously all along its length.
12-4
12.1.2 New DNA strands grow by the addition of nucleotides to the 3′ end.
Although replication is semiconservative, as predicted by the model in Fig. 12.1, the model alone does not tell us the details of replication. For example, the model implies that both daughter strands should grow in length by the addition of nucleotides near the site where the parental strands separate, a site called the replication fork. As more and more parental DNA is unwound and the replication fork moves forward (to the left in Fig. 12.1), both new strands would also grow in the direction of replication fork movement. But it turns out that this scenario is impossible.
We have seen that the two DNA strands in a double helix run in an antiparallel fashion: One of the template strands (the bottom one in Fig. 12.1) has a left-to-right 5′-to-3′ orientation, whereas the other template strand (the top one in Fig. 12.1) has a left-to-right 3′-to-5′ orientation. Therefore, the new daughter strands will also have opposite orientations, so that near the replication fork the daughter strand in the bottom duplex terminates in a 3′ hydroxyl, whereas that in the top duplex terminates in a 5′ phosphate. There’s the rub: The strand that terminates in the 5′ phosphate cannot grow in the direction of the replication fork because new DNA strands can grow only by the addition of successive nucleotides to the 3′ end. That is, DNA always grows in the 5′-to-3′ direction.
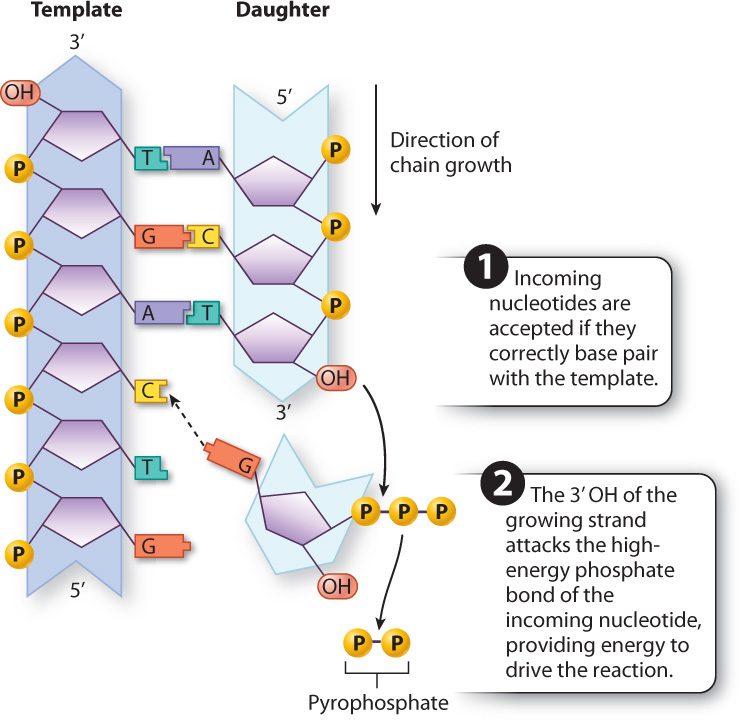
DNA polymerization occurs only in the 5′-to-3′ direction because of the chemistry of DNA synthesis, discussed in Chapter 3. The building blocks of DNA (Chapter 2) are nucleotides, each consisting of a deoxyribose sugar with three phosphate groups attached to the 5′ carbon, a nitrogenous base (A, T, G, or C) attached to the 1′ carbon, and a free hydroxyl (OH) group attached to the 3′ carbon. DNA polymerization occurs when the 3′ hydroxyl at the growing end of the polynucleotide chain attacks the triphosphate at the 5′ end of an incoming nucleotide (Fig. 12.4). Each of these incoming nucleotides is a triphosphate (three phosphate groups attached to the 5′ carbon of the deoxyribose). When the incoming nucleotide triphosphate is added to the growing DNA strand, the outermost two phosphates (called pyrophosphate) are cleaved off and diffuse away. The energy released by cleaving off the pyrophosphate is what drives the polymerization reaction that attaches the incoming nucleotide to the growing strand.
The polymerization reaction is catalyzed by DNA polymerase, an enzyme that is a critical component of a large protein complex that carries out DNA replication. DNA polymerases exist in all organisms and are highly conserved, meaning that they vary little from one species to another because they carry out an essential function. A cell typically contains several different DNA polymerase enzymes, each specialized for a particular situation. But all DNA polymerases share the same basic function in that they synthesize a new DNA strand from an existing template. Most, but not all, also correct mistakes in replication, as we will see. DNA polymerases have many practical applications in the laboratory, which we will discuss later in this chapter.
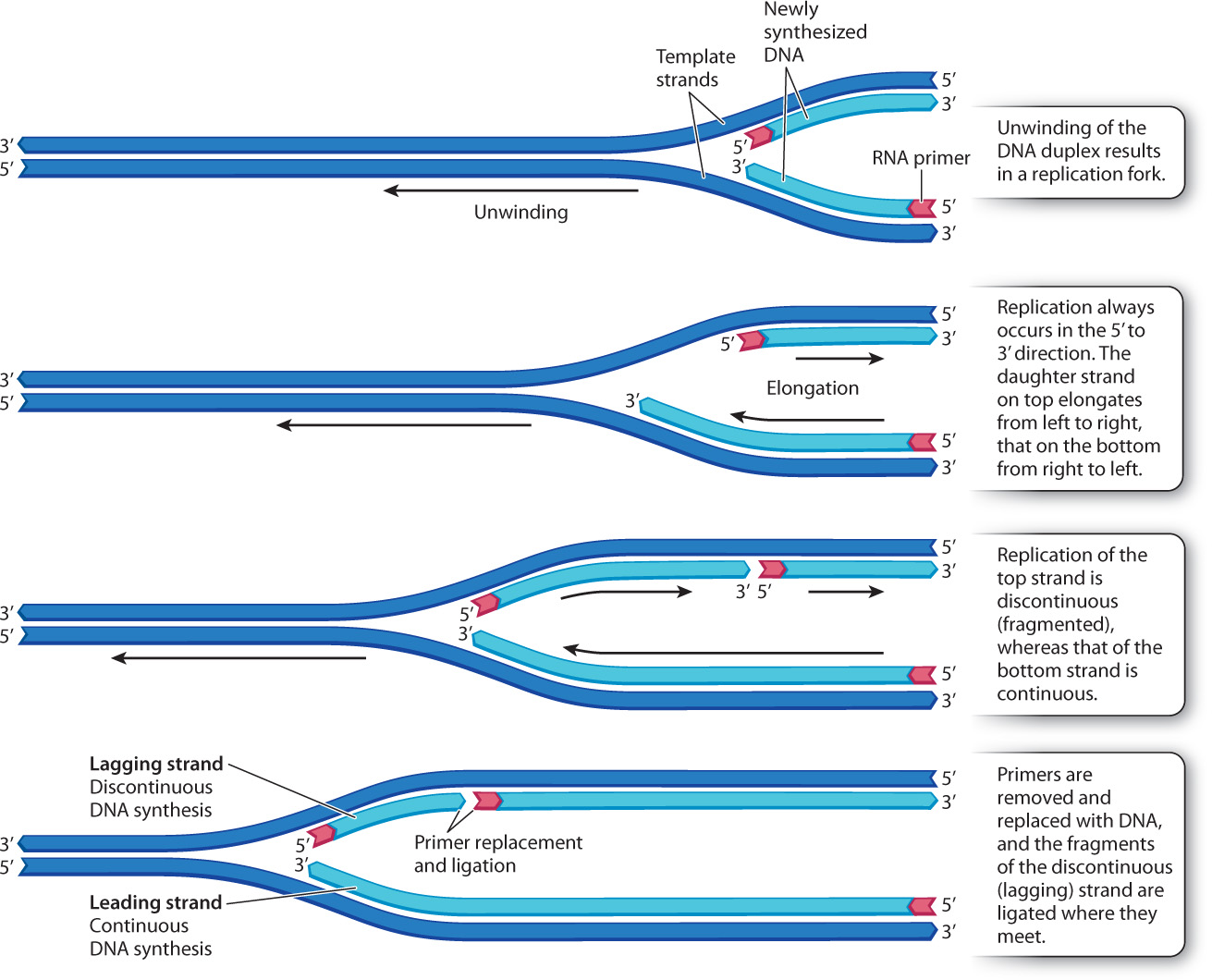
12.1.3 In replicating DNA, one daughter strand is synthesized continuously and the other in a series of short pieces.
Because a new DNA strand can be elongated only at the 3′ end, the two daughter strands are synthesized in quite different ways (Fig. 12.5). The daughter strand shown at the bottom of Fig. 12.5 has its 3′ end pointed toward the replication fork, so that as the parental double helix unwinds, this daughter strand can be synthesized as one long, continuous polymer. This daughter strand is called the leading strand.
12-5
The situation is different for the daughter strand shown at the top in Fig. 12.5. Its 5′ end is pointed toward the replication fork, but the strand cannot grow in that direction. Instead, as the replication fork unwinds, it forms a stretch of single-stranded DNA of a few hundred to a few thousand nucleotides, depending on the species. Then a new daughter strand is initiated with its 5′ end near the replication fork, and this strand is elongated at the 3′ end as usual. The result is that the daughter strand shown at the top in Fig. 12.5 is actually synthesized in short, discontinuous pieces. As the parental double helix unwinds, a new piece is initiated at intervals, and each new piece is elongated at its 3′ end until it reaches the piece in front of it. This daughter strand is called the lagging strand. The short pieces in the lagging strand are sometimes called Okazaki fragments after their discoverer, Japanese molecular biologist Reiji Okazaki.
The presence of leading and lagging strands during DNA replication is a consequence of the antiparallel nature of the two strands in a DNA double helix, and the fact that DNA polymerase can synthesize DNA in only one direction.
12.1.4 A small stretch of RNA is needed to begin synthesis of a new DNA strand.
Each new DNA strand must begin with a short stretch of RNA that serves as a primer, or starter, for DNA synthesis. The primer is needed because the DNA polymerase complex cannot begin a new strand on its own; it can only elongate the end of an existing piece of DNA or RNA. The primer is made by an RNA polymerase called RNA primase, which synthesizes a short piece of RNA complementary to the DNA template and does not require a primer. Once the primer has been synthesized, the DNA polymerase takes over and elongates the primer, adding successive DNA nucleotides to the 3′ end of the growing strand.
12-6
Because the DNA polymerase complex extends an RNA primer, all new DNA strands have a short stretch of RNA at their 5′ end. For the lagging strand, there are many such primers, one for each of the discontinuous fragments of newly synthesized DNA. As each of these fragments is elongated by DNA polymerase, it grows toward the primer of the fragment in front of it. When the growing fragment comes into contact with the primer, a different DNA polymerase complex takes over, removing the RNA primer, and replacing it with DNA nucleotides. When the replacement is completed, the adjacent fragments are joined, or ligated, by an enzyme called DNA ligase. This process is illustrated in Fig. 12.6.

12.1.5 DNA polymerase is self-correcting because of its proofreading function.
Most DNA polymerases can correct their own errors in a process called proofreading, which is a separate enzymatic activity from strand-elongation (synthesis) (Fig. 12.7).
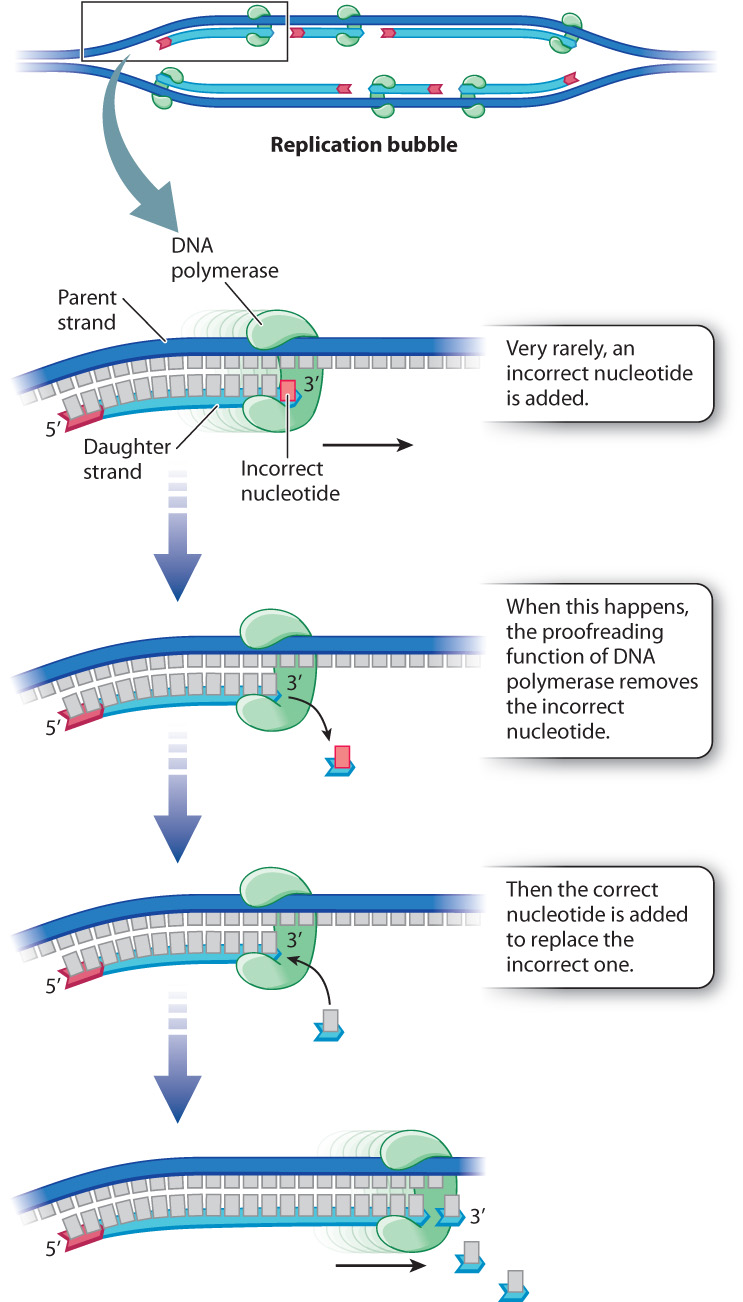
When each new nucleotide comes into line in preparation for attachment to the growing DNA strand, the nucleotide is temporarily held in place by hydrogen bonds that form between the base in the new nucleotide and the base across the way in the template strand. The strand being synthesized and the template strand therefore have complementary bases—A paired with T, or G paired with C. However, on rare occasions, improper hydrogen bonds form, with the result that an incorrect nucleotide is attached to the new DNA strand. DNA polymerase can correct errors because it detects mispairing between the template and the most recently added nucleotide. Mispairing between a base in the parental strand and a newly added base in the daughter strand activates a DNA-cleavage function of DNA polymerase that removes the incorrect nucleotide, and inserts the correct one in its place.
12-7
Mutations resulting from errors in nucleotide incorporation still occur, but proofreading reduces their number. In the bacterium E. coli, for example, about 99% of the incorrect nucleotides that are incorporated during replication are removed and repaired by the proofreading function of DNA polymerase. Those that slip past proofreading and other repair systems (Chapter 14) lead to mutations, which are then faithfully copied and passed on to daughter cells. Some of these mutations may be harmful, but others are neutral and a rare few may be beneficial. These mutations are the ultimate source of genetic variation that we see among individuals of the same species and among species, as we explore in Chapter 15.
12.1.6 Many proteins participate in DNA replication.
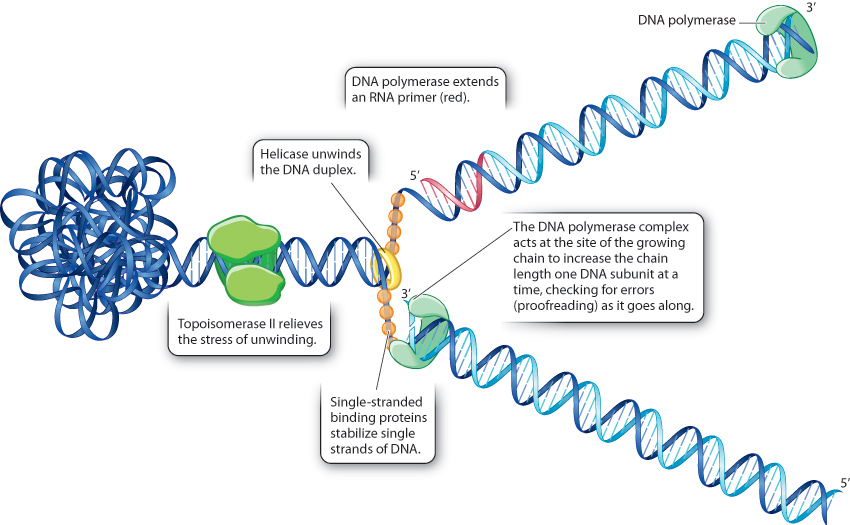
We have seen that DNA replication requires the DNA polymerase complex that elongates each strand at the 3′ end, the RNA primase that makes the primer, the DNA polymerase complex that replaces the RNA primer with DNA, and the DNA ligase that joins the DNA fragments in the lagging strand. Many other proteins are also involved (Fig. 12.8). One of these, helicase, unwinds the parental double helix at the replication fork. Single-stranded binding proteins then bind the resulting single-stranded regions of DNA to prevent the template strands from coming back together. Topoisomerase II works upstream from the replication fork to relieve the stress on the double helix that results from its unwinding at the replication fork.
Although many evolutionarily conserved proteins are required for DNA replication, the underlying process is quite simple and the same in all organisms. The two strands of the parental DNA duplex separate, and each serves as a template for the synthesis of a daughter strand according to the base-pairing rules of A–T and G–C, with each successive nucleotide being added to the 3′ end of the growing strand.
12-8