9.1 Protein Structure
When a primary transcript has been fully processed into a mature mRNA molecule, translation into protein can take place. Before considering how proteins are made, we need to understand protein structure. Proteins are the main determinants of biological form and function. These molecules heavily influence the shape, color, size, behavior, and physiology of organisms. Because genes function by encoding proteins, understanding the nature of proteins is essential to understanding gene action.
A protein is a polymer composed of monomers called amino acids. In other words, a protein is a chain of amino acids. Because amino acids were once called peptides, the chain is sometimes referred to as a polypeptide. Amino acids all have the general formula
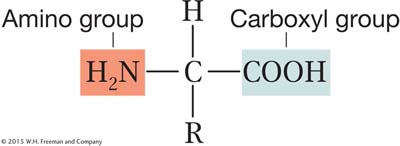
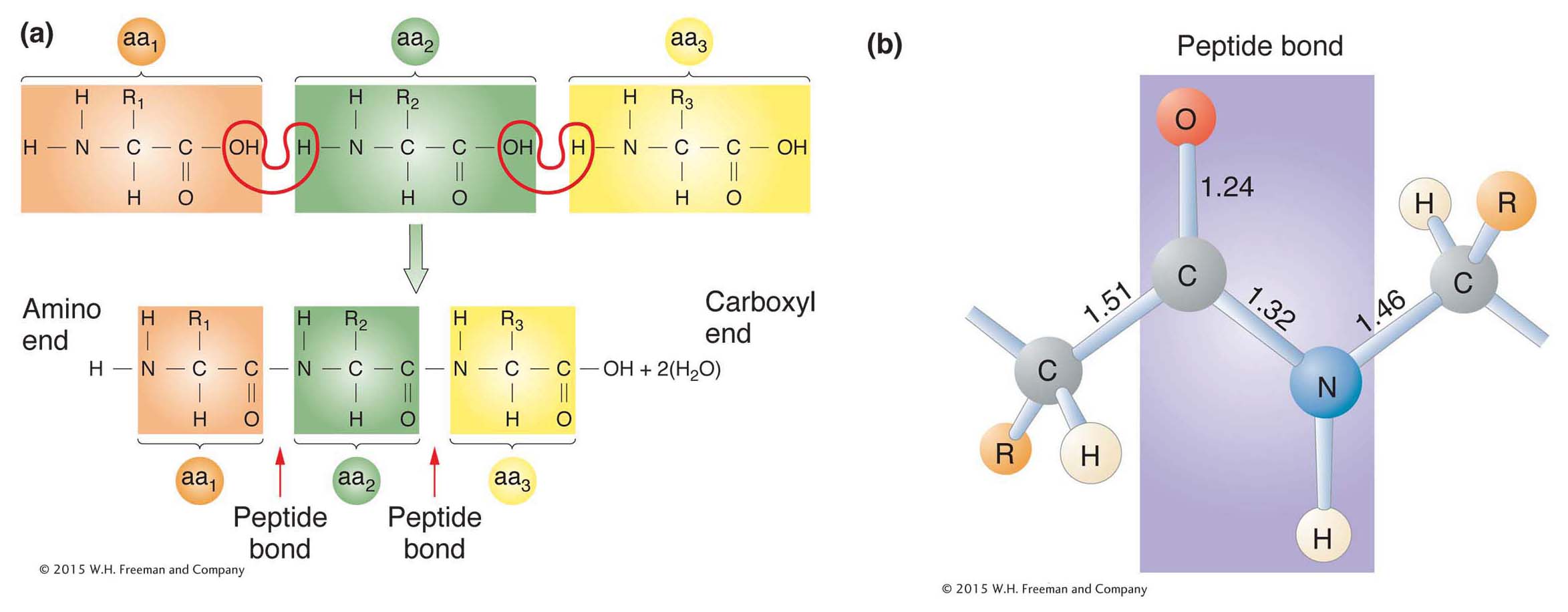
All amino acids have two functional groups (the carboxyl and amino, shown above) bonded to the same carbon atom (called the α carbon). Also attached to the α carbon are an H atom and a side chain, or R (reactive) group. There are 20 amino acids known to exist in proteins, each having a different R group that gives the amino acid its unique properties. The side chain can be anything from a hydrogen atom (as in the amino acid glycine) to a complex ring (as in the amino acid tryptophan). In proteins, the amino acids are linked together by covalent bonds called peptide bonds. A peptide bond is formed by the linkage of the amino end (NH2) of one amino acid with the carboxyl end (COOH) of another amino acid (Figure 9-2). One water molecule is removed during the reaction. Because of the way in which the peptide bond forms, a polypeptide chain always has an amino end (NH2) and a carboxyl end (COOH), as shown in Figure 9-2a.
ANIMATED ART: Translation: peptide-
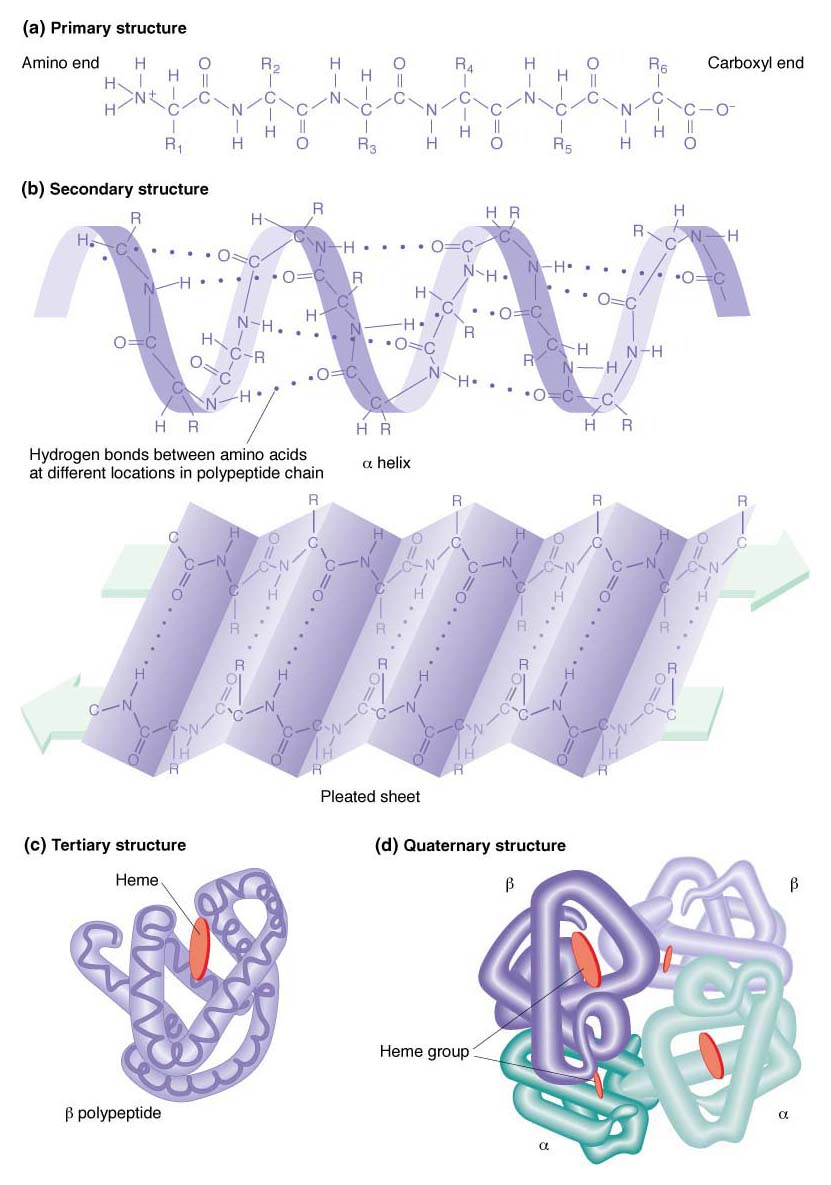
Proteins have a complex structure that has four levels of organization, illustrated in Figure 9-3. The linear sequence of the amino acids in a polypeptide chain con stitutes the primary structure of the protein. Local regions of the polypeptide chain fold into specific shapes, called the protein’s secondary structure. Each shape arises from the bonding forces between amino acids that are close together in the linear sequence. These forces include several types of weak bonds, notably hydrogen bonds, electrostatic forces, and van der Waals forces. The most common secondary structures are the α helix and the β-pleated sheet. Different proteins show either one or the other or sometimes both within their structures. Tertiary structure is produced by the folding of the secondary structure. Some proteins have quaternary structure: such a protein is composed of two or more separate folded polypeptides, also called subunits, joined by weak bonds. The quaternary association can be between different types of polypeptides (resulting in a heterodimer if there are two subunits) or between identical polypeptides (making a homodimer). Hemoglobin is an example of a heterotetramer, a four-
323
324
Many proteins are compact structures; they are called globular proteins. Enzymes and antibodies are among the best-
Shape is all-
At present, the rules by which primary structure is converted into higher-