The genetic code specifies which amino acids will be included in the polypeptide
295
The genetic code is the informational key by which a sequence of mRNA nucleotides corresponding to a gene is translated into the sequence of amino acids composing the protein expressed by that gene. That is, the genetic code specifies which amino acids will be used to build a protein. You can think of the code as consisting of a series of sequential, non-
296
CHARACTERISTICS OF THE CODE Molecular biologists “broke” the genetic code in the early 1960s. The problem they addressed was perplexing: how could more than 20 “code words” be written with an “alphabet” consisting of only four “letters”? In other words, how could four bases (A, U, G, and C) code for 20 different amino acids?
A triplet code, based on three-
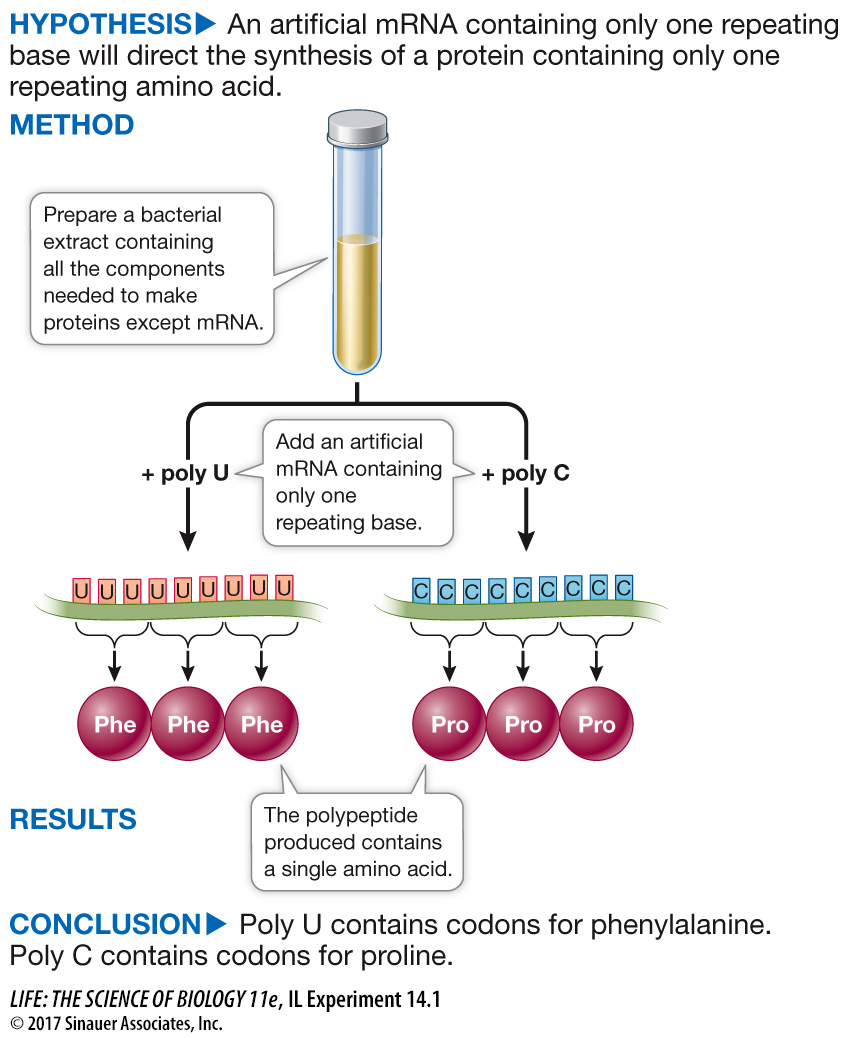
Marshall W. Nirenberg and J. H. Matthaei, at the U.S. National Institutes of Health, made the first decoding breakthrough in 1961 when they realized that the code would be easier to break if they were working with a very simple, known mRNA sequence rather than with a complex natural mRNA molecule. They set out to synthesize mRNA molecules consisting of just one type of nucleotide base; poly U mRNA, for example, consisted of just uracil nucleotides. Nirenberg and Matthaei’s goal was to then identify, through a translation process conducted in a test tube, the polypeptide that the artificial messenger encoded. Their experiment, which is laid out in Investigating Life: Deciphering the Genetic Code, led to the identification of the first codons. Other scientists soon identified the rest of the code. This was a major achievement, linking the information in DNA (the gene) to its expression in a protein (the phenotype). The understanding that the amino acids for each protein are spelled out via codons not only led to our understanding of the fundamentals of genetics and mutation, but to investigations into the genetic underpinnings of disease, such as the development of resistance in MRSA described in the opening of this chapter.
investigatinglife
Deciphering the Genetic Code
experiment
Original Paper: Nirenberg, M. and H. Matthaei. 1961. The dependence of cell-
Nirenberg and Matthaei used a test tube protein synthesis system to determine the amino acids specified by synthetic mRNAs of known compositions.
work with the data
After the relationship between DNA and proteins was established, genetic evidence pointed to triplets of nucleotides on RNA specifying each amino acid. The race was on to identify which triplet coded for which amino acid. Test tube systems were developed in which cell extracts were made and protein synthesis occurred. It was detected by supplying all 20 amino acids, with one of them being radioactive. Marshall Nirenberg, a scientist at the U.S. National Institutes of Health, and Heinrich Matthaei, a postdoctoral fellow from Germany, made a synthetic RNA consisting of the base uracil only (called poly U, codon UUU) and tested it in 20 tubes. Each test tube was supplied with all 20 amino acids, but in each one a different amino acid was tagged with a radioactive marker. In only one of them was a polypeptide made: a protein consisting of the amino acid phenylalanine bonded repeatedly to itself.
QUESTIONS
Question 1
Poly U, an artificial mRNA, was added to a test tube with all the other components for protein synthesis (“complete system”). Other test tubes differed from the complete system as indicated in the table. Samples were tested for radioactive phenylalanine incorporation, with the results in Table A. Explain the results for each of the conditions.
Minus poly U mRNA: Charged tRNA does not bind to the codon at the ribosome, so no polypeptide can be made.
Minus ribosomes: There are no locations for adjacent charged tRNAs to bind and also no peptidyl synthetase to catalyze peptide bond formation.
Minus ATP: tRNA cannot get charged with amino acids, and mRNA cannot translocate along the ribosome. No polypeptides are made.
Plus RNase: mRNA is destroyed. See Minus poly U mRNA, above.
Plus DNase: All the components for polypeptide synthesis are present.
Radioactive glycine instead of phenylalanine: Charged glycine tRNA binds to mRNA codon GGU, GGA, GGG, or GGC. These codons are not present in the poly U mRNA, so no radioactive polypeptides are made.
Mixture of 19 radioactive amino acids minus phenylalanine: Charged tRNAs are made, but their codons are not present, so no polypeptides are made.
| Condition | Counts/minute (units of radioactivity) |
|---|---|
| Complete system | 29,500 |
| Minus poly U mRNA | 70 |
| Minus ribosomes | 52 |
| Minus ATP | 83 |
| Plus RNase (hydrolyzes RNA) | 120 |
| Plus DNase (hydrolyzes DNA) | 27,600 |
| Radioactive glycine instead of phenylalanine | 33 |
| Mixture of 19 radioactive amino acids minus phenylalanine | 276 |
Question 2
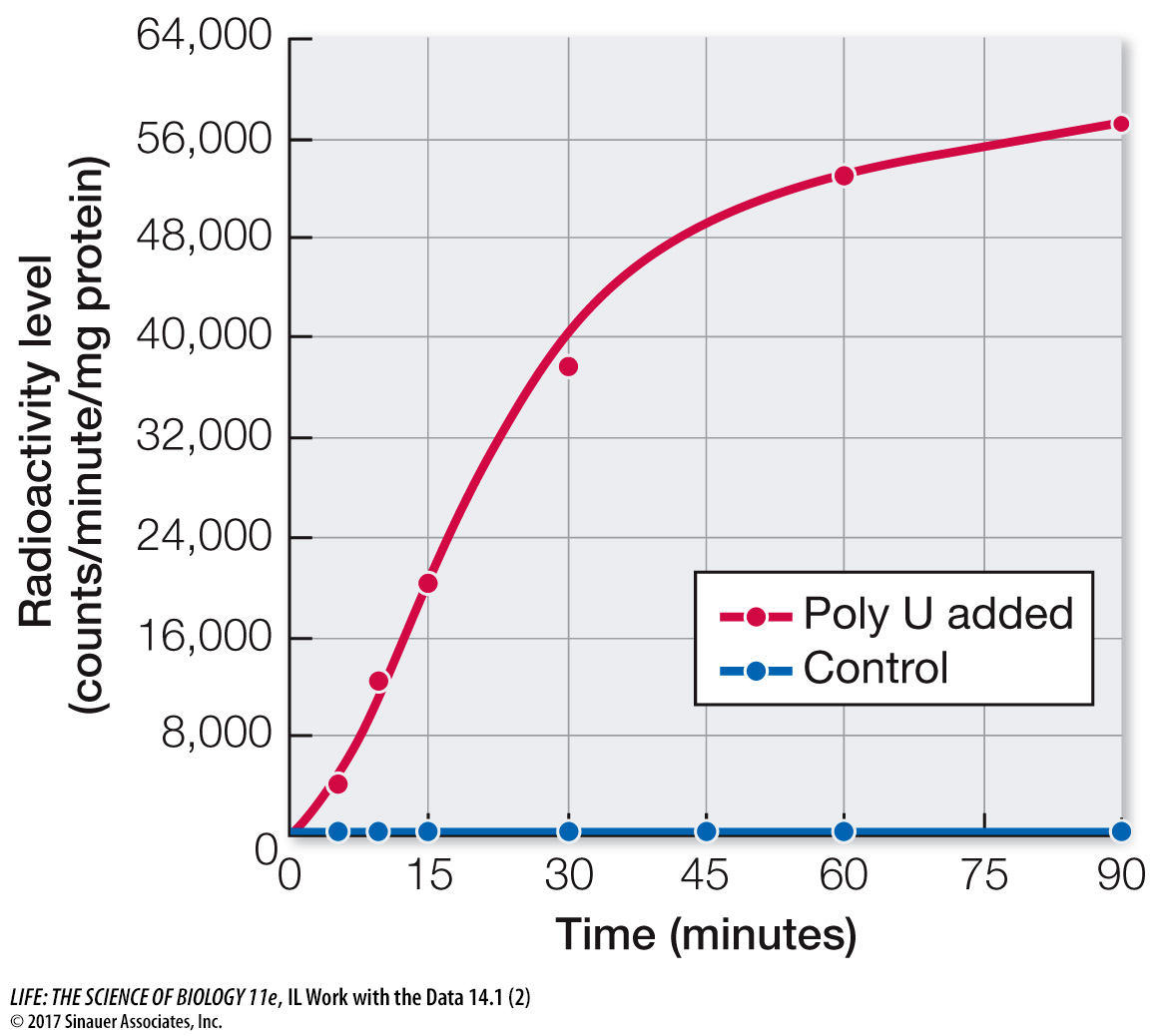
Poly U (red dots) was added to the test tubes at various intervals. Samples were tested for protein synthesis by radioactive amino acid incorporation after various times (and were compared with results of a control run, in which no RNA was added, indicated by blue dots). The results are shown in the figure below. What do these data show about the dependence of protein synthesis on added RNA?
The data show that RNA (poly U) was essential for protein synthesis, since its absence resulted in no protein synthesis.
Question 3
The experiment described in Question 2 was repeated with different amino acids; the results are in Table B. Explain these results in terms of the codon specificity of poly U.
According to the genetic code (see Figure 14.5), UUU is the codon for phenylalanine. The other amino acids were not added to protein in the poly U experiment because only the UUU codon was present.
| Radioactive amino acid | Counts/minute/mg protein (radioactivity level) |
|---|---|
| Phenylalanine | 38,300 |
| Glycine, alanine, serine, aspartic acid, glutamic acid | 33 |
| Leucine, isoleucine, threonine, methionine, arginine, histidine, valine, lysine, tyrosine, proline, tryptophan | 276 |
| Cysteine | 113 |
A similar work with the data exercise may be assigned in LaunchPad.
Animation 14.2 Deciphering the Genetic Code
www.life11e.com/
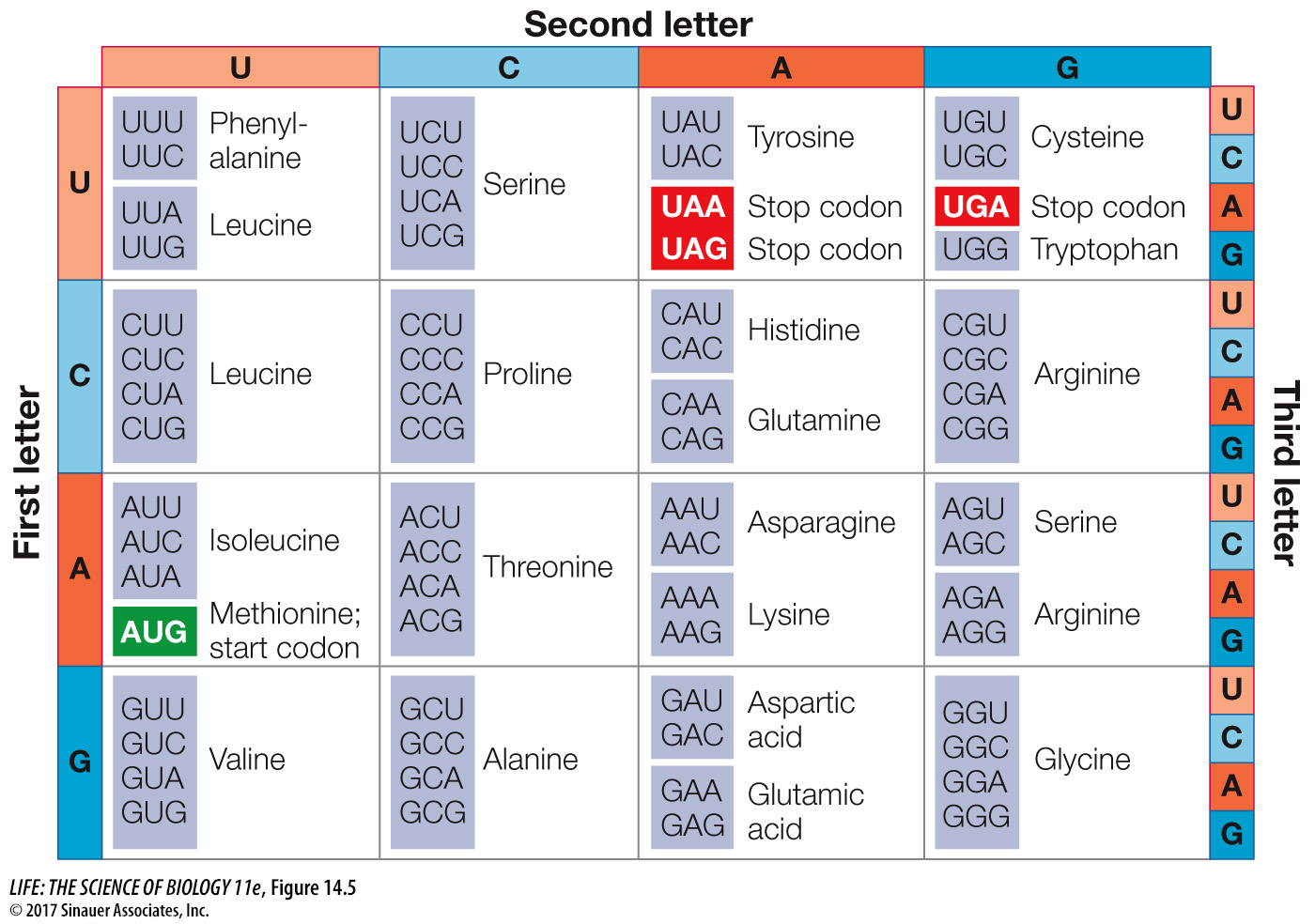
The complete genetic code is shown in Figure 14.5. Notice that there are many more codons than there are different amino acids in proteins. Proteins are built from just 20 amino acids, but all possible combinations of the four available “letters” (the bases) give 64 (43) different three-
Activity 14.2 The Genetic Code
www.life11e.com/
Don’t confuse a redundant code with an ambiguous code. If the code were ambiguous, a single codon could specify two (or more) different amino acids, and there would be doubt about which amino acid should be incorporated into a growing polypeptide chain. Redundancy in the code simply means there is more than one clear way to say “Put leucine here.” The genetic code is not ambiguous: a given amino acid may be encoded by more than one codon, but a codon can code for only one amino acid.
THE GENETIC CODE IS (NEARLY) UNIVERSAL The same basic genetic code is used by all the species on our planet. Thus the code must be an ancient one that has been maintained intact throughout the evolution of living organisms. Exceptions are known: for example, the code for *mitochondrial DNA and chloroplast DNA differs slightly from that used by prokaryotes and for the nuclear DNA of eukaryotic cells; and in one group of protists, UAA and UAG code for glutamine rather than for stop codons. The significance of these differences is not yet clear. What is clear is that the exceptions are few.
297
*connect the concepts As discussed in Key Concept 12.5, some cytoplasmic organelles, notably the mitochondria and chloroplasts, contain small numbers of genes that are remnants of the genomes of the prokaryotes that eventually gave rise to these organelles. The evolutionary process of endosymbiosis that is responsible for the assimilation of these organelles into eukaryotic cells is discussed in Key Concept 27.1.
A common genetic code provides a common language for evolution. Natural selection acts on phenotypic variations that result from genetic variation. The genetic code probably originated early in the evolution of life. As we saw in Chapter 4, simulation experiments indicate the plausibility of individual nucleotides and nucleotide polymers arising spontaneously on primeval Earth. The common code also has profound implications for genetic engineering, as we will see in Chapter 18, since it means that the code for a human gene is the same as that for a bacterial gene. It is therefore impressive, but not surprising, that a human gene can be expressed in E. coli via laboratory manipulations, since these cells speak the same “molecular language.”
The codons illustrated in the Nirenberg and Matthaei experiment in Investigating Life: Deciphering the Genetic Code are mRNA codons. The base sequence of the DNA strand that is transcribed to produce the mRNA is complementary and antiparallel to these codons. Thus, for example, 3′-AAA-
3′-ACC-
5′ in the template DNA corresponds to tryptophan (which is encoded by the mRNA codon 5′-UGG- 3′).
298
The non-
You might be thinking that in a long DNA molecule with many protein-