Most Eukaryotic Genes Contain Introns and Produce mRNAs Encoding Single Proteins
As discussed in Chapter 5, many bacterial mRNAs (e.g., the mRNA encoded by the trp operon) include the coding region for several proteins that function together in a biological process. Such mRNAs are said to be polycistronic. (A cistron is a genetic unit encoding a single polypeptide.) In contrast, most eukaryotic mRNAs are monocistronic; that is, each mRNA molecule encodes a single protein. This difference between polycistronic and monocistronic mRNAs correlates with a fundamental difference in their translation.
Within a bacterial polycistronic mRNA, a ribosome-binding site is located near the start site for each of the protein-coding regions, or cistrons, in the mRNA. Translation initiation can begin at any of these multiple internal sites, producing multiple proteins (see Figure 5-13a). In most eukaryotic mRNAs, however, the 5′ cap directs ribosome binding, and translation begins at the closest AUG start codon (see Figure 5-13b). As a result, translation begins only at this site. In many cases, the primary transcripts of eukaryotic protein-coding genes are processed into a single type of mRNA, which is translated to give a single type of polypeptide (see Figure 5-15).
Unlike bacterial and yeast genes, which generally lack introns, most genes in multicellular animals and plants contain introns, which are removed during RNA processing in the nucleus before the fully processed mRNA is exported to the cytosol for translation. In many cases, the introns in a gene are considerably longer than the exons. The median intron length in human genes is 3.3 kb. Some, however, are much longer: the longest known human intron is 17,106 bp and lies within the titin gene, which encodes a structural protein in muscle cells. In comparison, most human exons contain only 50–200 bp. The typical human gene encoding an average-sized protein is about 50,000 bp long, but more than 95 percent of that sequence consists of introns and flanking noncoding 5′ and 3′ regions.
Many large proteins in higher organisms that have repeated domains are encoded by genes consisting of repeats of similar exons separated by introns of variable length. An example is fibronectin, a component of the extracellular matrix. The fibronectin gene contains multiple copies of five types of exons (see Figure 5-16). Such genes evolved by tandem duplication of the DNA encoding the repeated exon, probably by unequal crossing over during meiosis, as shown in Figure 8-2a.
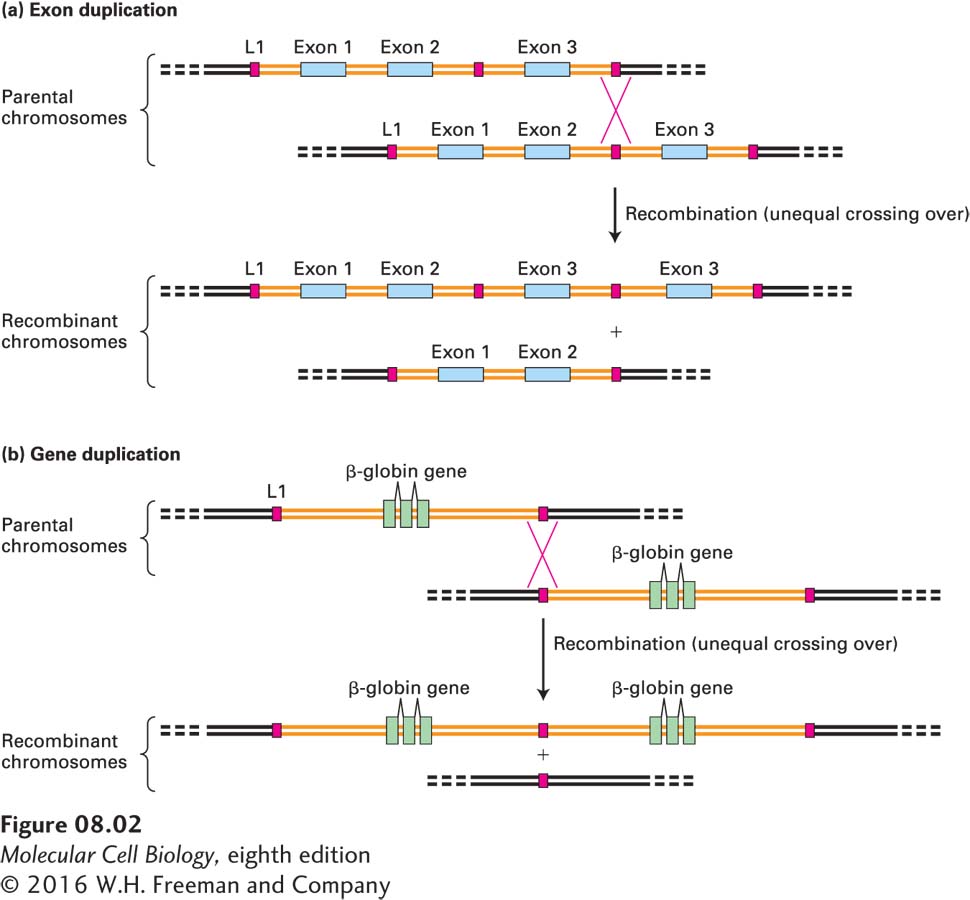
FIGURE 8-2 Exon and gene duplication. (a) Exon duplication results from unequal crossing over during meiosis. Each parental chromosome (top) contains one ancestral gene containing three exons (blue) and two introns (orange). Homologous noncoding sequences called L1 long interspersed elements lie 5′ and 3′ of the gene as well as in the intron between exons 2 and 3. As we will see later in the chapter, L1 elements have been repeatedly transposed to new sites in the genome over the course of human evolution, so that all chromosomes are peppered with them. The parental chromosomes are shown displaced relative to each other, so that the L1 elements are aligned. Homologous recombination between these L1 elements as shown would generate one recombinant chromosome in which the gene now has four exons (two copies of exon 3) and one chromosome in which the gene is missing exon 3. (b) The same process can generate duplications of entire genes. Each parental chromosome (top) contains one ancestral β-globin gene. After unequal recombination between L1 elements, subsequent independent mutations in the resulting duplicated genes could lead to slight changes in sequence that might result in slightly different functional properties of the encoded proteins. Unequal crossing over can also result from rare recombinations between unrelated sequences. See D. H. A. Fitch et al., 1991, Proc. Natl. Acad. Sci. USA 88:7396.