DNA polymerase is self-
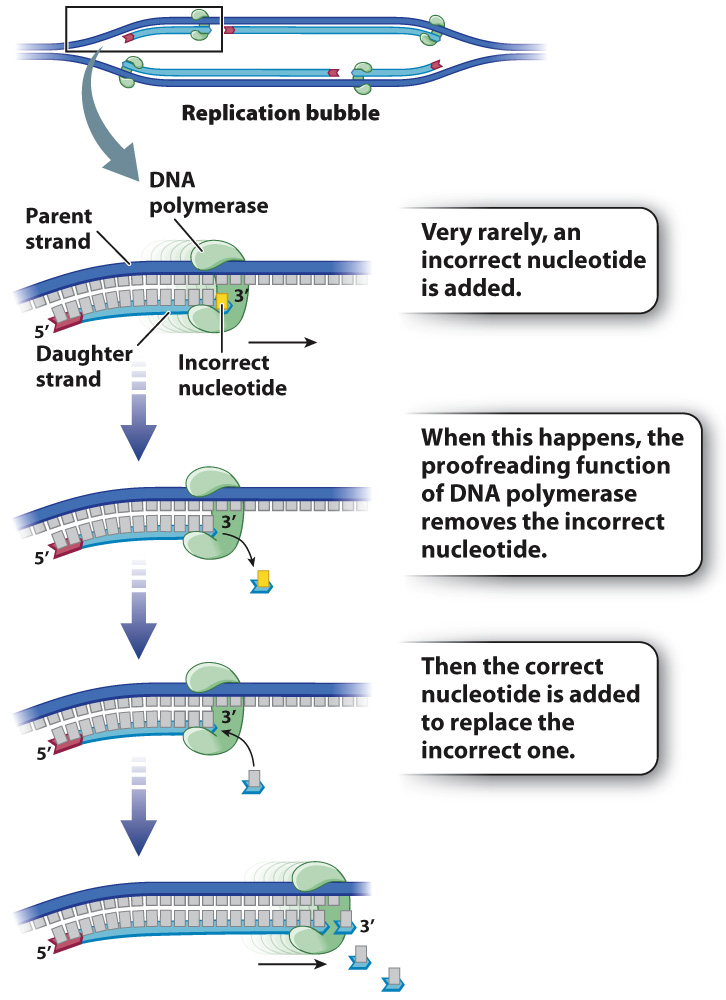
Most DNA polymerases can correct their own errors in a process called proofreading, which is a separate enzymatic activity from strand elongation (synthesis) (Fig. 12.8).
When each new nucleotide comes into line in preparation for attachment to the growing DNA strand, the nucleotide is temporarily held in place by hydrogen bonds that form between the base in the new nucleotide and the base across the way in the template strand. The strand being synthesized and the template strand therefore have complementary bases—
Mutations resulting from errors in nucleotide incorporation still occur, but proofreading reduces their number. In the bacterium E. coli, for example, about 99% of the incorrect nucleotides that are incorporated during replication are removed and repaired by the proofreading function of DNA polymerase. Those that slip past proofreading and other repair systems (Chapter 14) lead to mutations, which are then faithfully copied and passed on to daughter cells. Some of these mutations may be harmful, but others are neutral and a rare few may be beneficial. These mutations are the ultimate source of genetic variation that we see among individuals of the same species and among species, as we explore further in Chapter 15.