Nucleic acids encode genetic information in their nucleotide sequence.
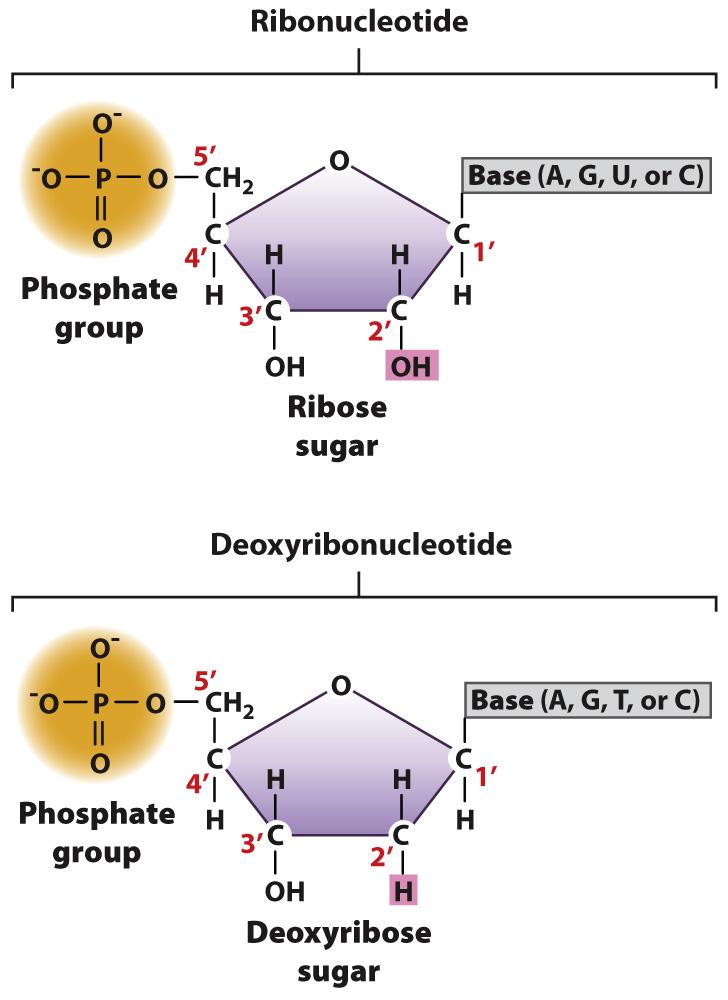
FIG. 2.18 A ribonucleotide and a deoxyribonucleotide, the units of RNA and DNA.
Nucleic acids are examples of informational molecules—that is, they are large molecules that carry information in the sequence of nucleotides that make them up. This molecular information is much like the information carried by the letters in an alphabet, but in the case of nucleic acids, the information is in chemical form.
The nucleic acid deoxyribonucleic acid (DNA) is the genetic material in all organisms. It is transmitted from parents to offspring, and it contains the information needed to specify the amino acid sequence of all the proteins synthesized in an organism. The nucleic acid ribonucleic acid (RNA) has multiple functions; it is a key player in protein synthesis and the regulation of gene expression.
DNA and RNA are long molecules consisting of nucleotides bonded covalently one to the next. Nucleotides, in turn, are composed of three components: a 5-carbon sugar, a nitrogen-containing compound called a base, and one or more phosphate groups (Fig. 2.18). The sugar in RNA is ribose, and the sugar in DNA is deoxyribose. The sugars differ in that ribose has a hydroxyl (OH) group on the second carbon (designated the 2′ carbon), whereas deoxyribose has a hydrogen atom at this position (hence, deoxyribose). (By convention, the carbons in the sugar are numbered with primes—1′, 2′, etc.—to distinguish them from carbons in the base—1, 2, etc.)
The bases are built from nitrogen-containing rings and are of two types. The pyrimidine bases (Fig. 2.19a) have a single ring and include cytosine (C), thymine (T), and uracil (U). The purine bases (Fig. 2.19b) have a double-ring structure and include guanine (G) and adenine (A). DNA contains the bases A, T, G, and C, and RNA contains the bases A, U, G, and C. Just as the order of amino acids provides the information carried in proteins, so, too, does the sequence of nucleotides determine the information in DNA and RNA molecules.
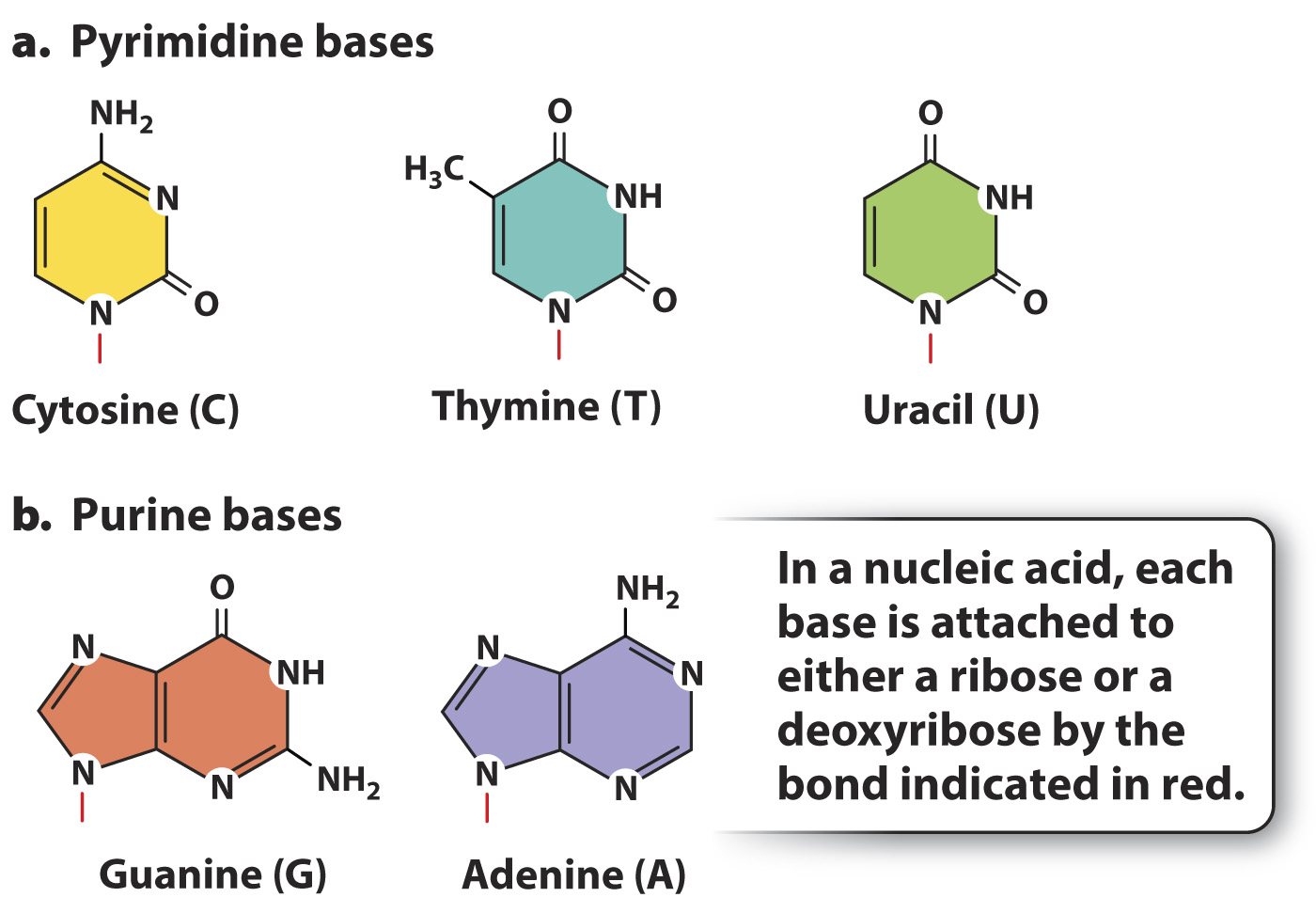
FIG. 2.19 Pyrimidine bases and purine bases. (a) Pyrimidines have a single-ring structure, and (b) purines have a double-ring structure.
In DNA and RNA, each adjacent pair of nucleotides is connected by a phosphodiester bond, which forms when a phosphate group in one nucleotide is covalently joined to the sugar unit in another nucleotide (Fig. 2.20). As in the formation of a peptide bond, the formation of a phosphodiester bond involves the loss of a water molecule.
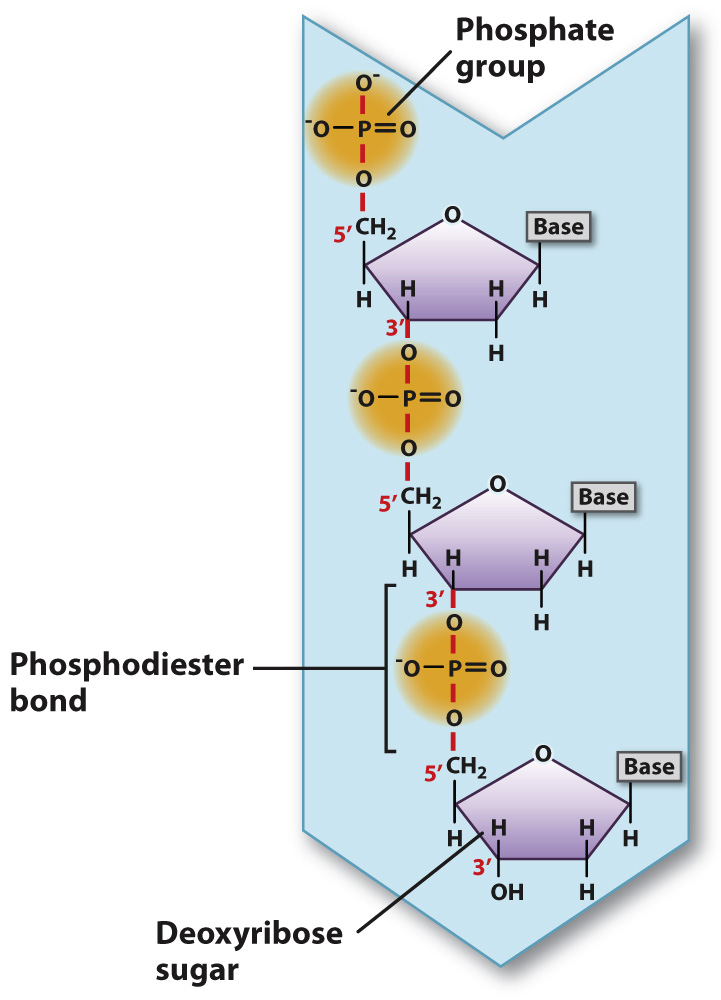
FIG. 2.20 The phosphodiester bond. Phosphodiester bonds link successive deoxyribonucleotides, forming the backbone of the DNA strand.
DNA in cells usually consists of two strands of nucleotides twisted around each other in the form of a double helix (Fig. 2.21a). The sugar–phosphate backbones of the strands wrap like a ribbon around the outside of the double helix, and the bases point inward. The bases form specific purine–pyrimidine pairs that are complementary: Where one strand carries an A, the other carries a T; and where one strand carries a G, the other carries a C (Fig. 2.21b). Base pairing results from hydrogen bonding between the bases (Fig. 2.21c).
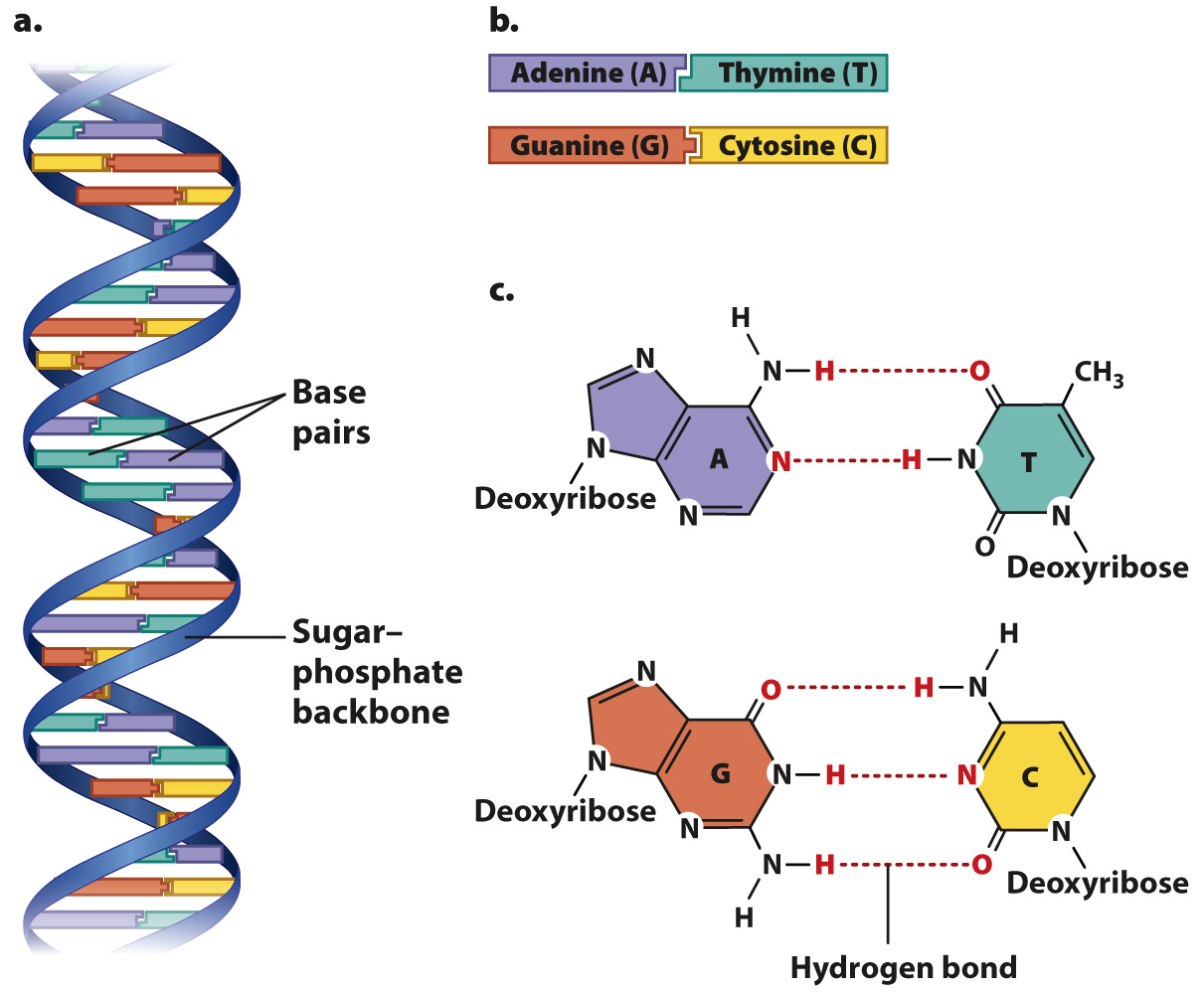
FIG. 2.21 The structure of DNA. (a) DNA is most commonly in the form of a double helix, with the sugar and phosphate groups forming the backbone and the bases oriented inward. (b) The bases are complementary, with A paired with T and G paired with C. (c) Base pairing results from hydrogen bonds.
Genetic information in DNA is contained in the sequence, or order, in which successive nucleotides occur along the molecule. Successive nucleotides along a DNA strand can occur in any order, and hence a long molecule could contain any of an immense number of possible nucleotide sequences. This is one reason why DNA is an efficient carrier of genetic information. In Chapter 3, we consider the structure and function of DNA and RNA in greater detail.