The three-
The double helix is a good example of how chemical structure and biological function come together. The structure of the molecule itself immediately suggested how genetic information is stored in DNA. One of the most important features of DNA structure is that there is no restriction on the sequence of bases along a DNA strand. Any A, for example, can be followed by another A or a T, C or G. The lack of sequence constraint suggested that the genetic information in DNA could be encoded in the sequence of bases along the DNA, much as textual information in a book is stored in a sequence of letters of the alphabet. With any of four possible bases at each nucleotide site, the information-
57
Watson and Crick’s model still left many questions unanswered in regard to how the information is read out and what it does, but in the years following it became clear that the major processes in the readout of genetic information were transcription and translation (see Fig. 3.3).
The sequence of bases along either strand completely determines that of the other because wherever one strand carries an A, the other must carry a T, and wherever one carries a G, the other must carry a C. The complementary base sequences of the strands means that, in any double-
Quick Check 1 The letter R is conventionally used to represent any purine base (A or G) and Y to represent any pyrimidine base (T or C). In double-
Quick Check 1 Answer
Because R = A or G, then %R = %A + %G; and because %A = %T and %G = %C, we can write %R = %A + %G = %T + %C. But T or C = Y, and so %T + %C = %Y. It follows that %R = %Y.
The complementary, double-
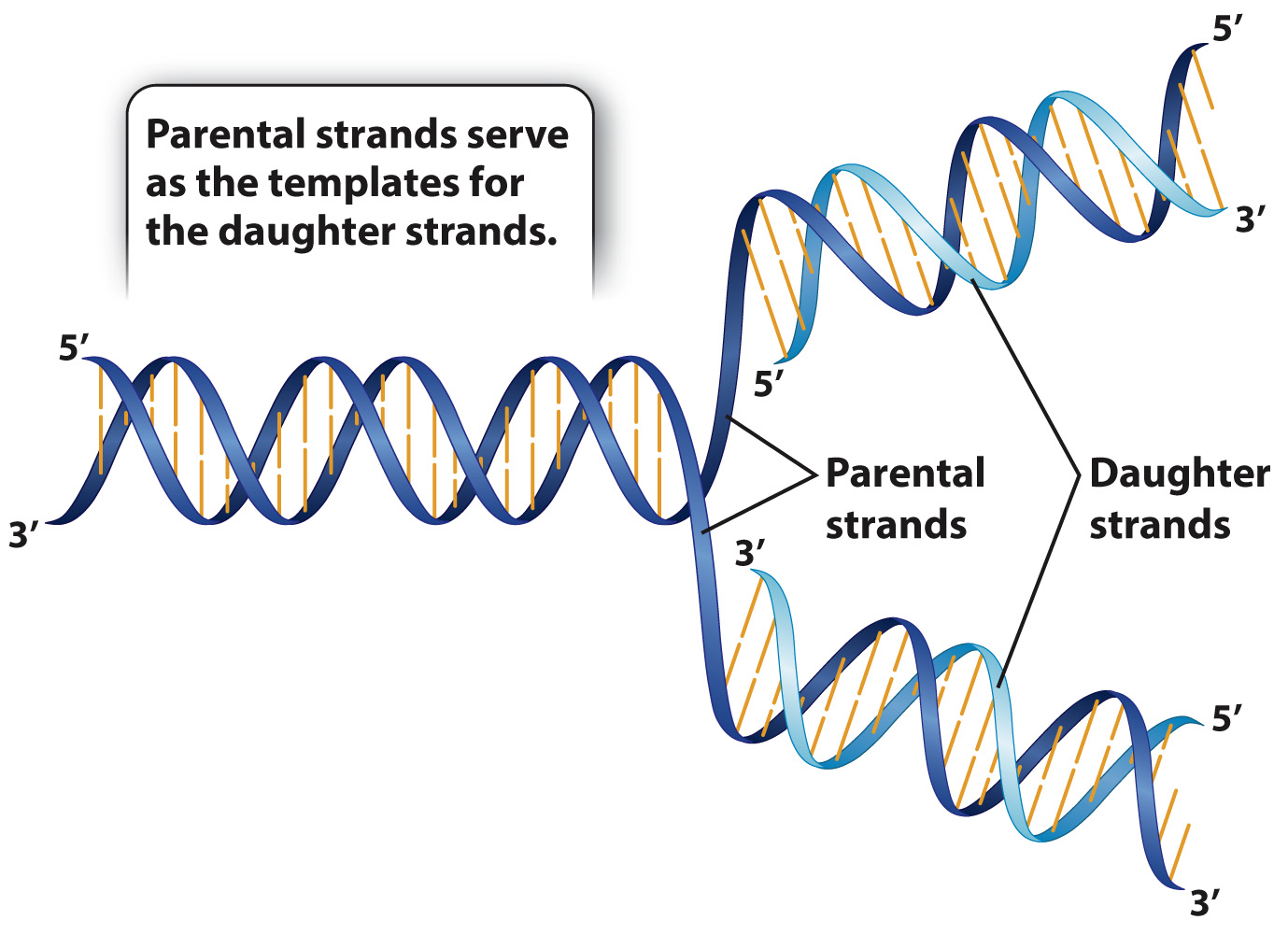
A simplified outline of DNA replication is shown in Fig. 3.11. In brief, the two strands of a parental double helix unwind, and as they do each of the parental strands serves as a template for the synthesis of a complementary daughter strand. When the process is complete, there are two molecules, each of which is identical in sequence to the original molecule, except possibly for rare errors (mutations) that cause one base pair to be replaced with another. Although the process of replication as depicted in Fig. 3.11 looks exceedingly simple and straightforward, there are technical details that make the actual process more complex. These are discussed in Chapter 12.
58