Exercises
Clarifying the Concepts
Question 4.1
| 4.1 |
Define the three measures of central tendency: mean, median, and mode. |
Question 4.2
| 4.2 |
The mean can be assessed visually and arithmetically. Describe each method. |
Question 4.3
| 4.3 |
Explain how the mean mathematically balances the distribution. |
Question 4.4
| 4.4 |
Explain what is meant by unimodal, bimodal, and multimodal distributions. |
Question 4.5
| 4.5 |
Explain why the mean might not be useful for a bimodal or multimodal distribution. |
Question 4.6
| 4.6 |
What is an outlier? |
Question 4.7
| 4.7 |
How do outliers affect the mean and median? |
Question 4.8
| 4.8 |
In which situations is the mode typically used? |
Question 4.9
| 4.9 |
Explain the concept of standard deviation in your own words. |
Question 4.10
| 4.10 |
Define the symbols used in the equation for variance: 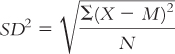
|
Question 4.11
| 4.11 |
Why is the standard deviation typically reported, rather than the variance? |
Question 4.12
| 4.12 |
Find the incorrectly used symbol or symbols in each of the following statements or formulas. For each statement or formula, (1) state which symbol(s) is/are used incorrectly, (2) explain why the symbol(s) in the original statement is/are incorrect, and (3) state which symbol(s) should be used.
|
Calculating the Statistics
Question 4.13
| 4.13 |
Use the following data for this exercise: 15 34 32 46 22 36 34 28 52 28
|
Question 4.14
| 4.14 |
Use the following salary data for this exercise: $44,751 $52,000 $41,500 $38,862 $51,380 $61,774
|
Question 4.15
| 4.15 |
The Mount Washington Observatory (MWO) in New Hampshire claims to have the world’s worst weather. On the next page are some data on the weather extremes recorded at the MWO. 95
|
Question 4.16
| 4.16 |
Here are recent U.S. News & World Report data on acceptance rates at the top 70 national universities. These are the percentages of accepted students out of all students who applied.
|
Applying the Concepts
Question 4.17
| 4.17 |
Mean versus median for salary data: In Exercises 4.13 and 4.14, we saw how the mean and median changed when an outlier was included in the computations. If you were reporting the “average” salary at a company, how might the mean and median give different impressions to potential applicants? |
Question 4.18
| 4.18 |
Mean versus median for temperature data: For the data in Exercise 4.15, the “normal” daily maximum and minimum temperatures recorded at the Mount Washington Observatory are presented for each month. These are likely to be measures of central tendency for each month over time. Explain why these “normal” temperatures might be calculated as means or medians. What would be the reasoning for using one type of statistic over the other? |
Question 4.19
| 4.19 |
Mean versus median for depression scores: A depression research unit recently assessed seven participants chosen at random from the university population. Is the mean or the median a better indicator of the central tendency of these seven participants? Explain your answer. |
Question 4.20
| 4.20 |
Measures of central tendency for weather data: The “normal” weather data from the Mount Washington Observatory are broken down by month. Why might you not want to average across all months in a year? How else could you summarize the year? |
Question 4.21
| 4.21 |
Outliers, central tendency, and data on wind gusts: There appears to be an outlier in the data for peak wind gust recorded on top of Mount Washington (see the data in Exercise 4.15). Where do you see an outlier and how does excluding this data point affect the different calculations of central tendency? |
Question 4.22
| 4.22 |
Measures of central tendency for measures of baseball performance: Here are winning percentages for 11 baseball players for their best 4- 0.755 0.721 0.708 0.773 0.782 0.747 0.477 0.817 0.617 0.650 0.651
|
96
Question 4.23
| 4.23 |
Mean versus median in “real life”: Briefly describe a real- |
Question 4.24
| 4.24 |
Descriptive statistics in the media: Find an advertisement for an anti-
|
Question 4.25
| 4.25 |
Descriptive statistics in the media: When there is an ad on TV for a body-
|
Question 4.26
| 4.26 |
Range of data for Canadian TV ratings: Numeris (formerly BBM Canada) collects Canadian television ratings data (http:/
|
Question 4.27
| 4.27 |
Descriptive statistics for data from the National Survey of Student Engagement: Every year, the National Survey of Student Engagement (NSSE) asks university students how many 20-
|
Question 4.28
| 4.28 |
Statistics versus parameters: For each of the following situations, state whether the mean would be a statistic or a parameter. Explain your answer.
|
Question 4.29
| 4.29 |
Central tendency and the shapes of distributions: Consider the many possible distributions of grades on a quiz in a statistics class; imagine that the grades could range from 0 to 100. For each of the following situations, give a hypothetical mean and median (that is, make up a mean and a median that might occur with a distribution that has this shape). Explain your answer.
|
Question 4.30
| 4.30 |
Shapes of distributions: For each of the following, state whether the distribution is more likely to be unimodal or bimodal. Explain your answer.
|
Question 4.31
| 4.31 |
Outliers, Hurricane Sandy, and a rat infestation: In a New York Times article, reporter Cara Buckley described the influx of rats inland from the New York City shoreline following the flooding caused by Hurricane Sandy (2013). Buckley interviewed pest-
|
Question 4.32
| 4.32 |
Outliers, H&M, and designer collaborations: The relatively low- |
Question 4.33
| 4.33 |
Central tendency and outliers from growth- |
Question 4.34
| 4.34 |
Measures of central tendency for percentages of advanced degrees: The U.S. Census Bureau collects and analyzes data on numerous aspects of American life by state, including the percentage of people with high school degrees, bachelor’s degrees, and advanced degrees. If you wanted to calculate the “average” percentage of people with advanced degrees across all states, would you report a mean, a median, or a mode? Explain your answer clearly. |
Question 4.35
| 4.35 |
Mean versus median for age at first marriage: The mean age at first marriage was 31.1 for men and 29.1 for women in Canada in 2008 (http:/ |
Question 4.36
| 4.36 |
Median ages and technology companies: In an article titled “Technology Workers Are Young (Really Young),” the New York Times reported median ages for a number of companies (Hardy, 2013). The reporter wrote: “The seven companies with the youngest workers, ranked from youngest to highest in median age, were Epic Games (26); Facebook (28); Zynga (28); Google (29); and AOL, Blizzard Entertainment, InfoSys, and Monster.com (all 30). According to the Bureau of Labor Statistics, only shoe stores and restaurants have workers with a median age less than 30.”
|
Question 4.37
| 4.37 |
Standard deviation and a texting intervention for parents of preschoolers: Researchers investigated READY4K, a program in which parents received text messages over an 8-
|
Question 4.38
| 4.38 |
Range, world records, and a long chain of friendship bracelets: Guinness World Records reported that, as part of an anti- |
98
Putting It All Together
Question 4.39
| 4.39 |
Descriptive statistics and basketball wins: Here are the numbers of wins for the 30 National Basketball Association teams in the 2012–
|
Question 4.40
| 4.40 |
Central tendency and outliers for data on traffic deaths: Below are estimated numbers of annual road traffic deaths for 12 countries based on data from the World Health Organization (http:/
|