Concept 10.3: The Genetic Code in RNA Is Translated into the Amino Acid Sequences of Proteins
The translation of the nucleotide sequence of an mRNA into the amino acid sequence of a polypeptide occurs at the ribosome. In prokaryotes, transcription and translation are coupled: there is no nucleus, and ribosomes often bind to an mRNA as it is being transcribed in the cytoplasm. In eukaryotes, the nuclear envelope separates the locations of mRNA production and translation, the latter occurring at ribosomes in the cytoplasm. In both cases, the key event is the decoding of one chemical “language” (the nucleotide sequence) into another (the amino acid sequence).
The information for protein synthesis lies in the genetic code
The genetic information in an mRNA molecule is a series of sequential, nonoverlapping three-letter “words” called codons. Each codon specifies a particular amino acid. The “letters” are three adjacent nucleotide bases in the mRNA polynucleotide chain. Each codon in the mRNA is complementary to the corresponding triplet of bases in the template strand of the DNA molecule from which it was transcribed. The genetic code relates codons to their specific amino acids.
Characteristics of the Genetic Code
Molecular biologists “broke” the genetic code in the early 1960s. The problem they addressed was perplexing: how could 20 different amino acids be specified using only four nucleotide bases (A, U, G, and C)? A triplet code with three-letter codons was considered likely because it was the shortest sequence with enough possible variations to encode all 20 amino acids. With four available bases, a triplet codon has 4 × 4 × 4 = 64 variations.
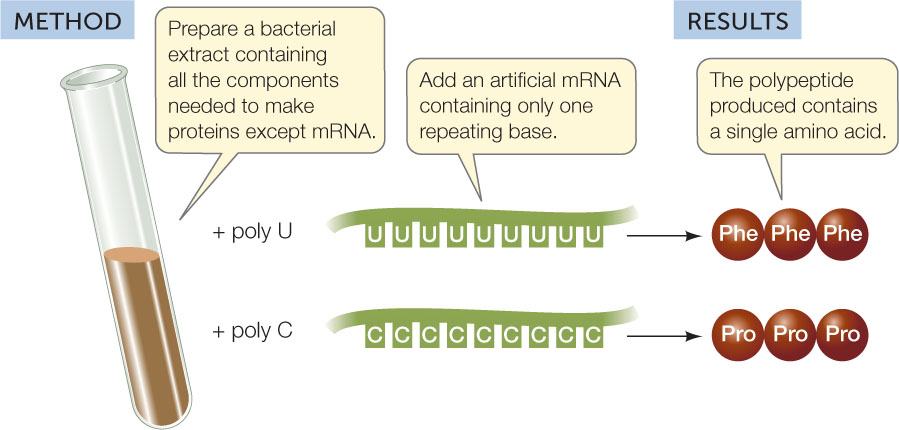
Marshall Nirenberg and Heinrich Matthaei, at the U.S. National Institutes of Health, made the first decoding breakthrough in 1961 when they realized they could use a simple artificial polynucleotide instead of a complex natural mRNA as a template for polypeptide synthesis in a test tube. They could then identify the poly-peptide the artificial messenger encoded. This led to the identification of the first two codons, as described in FIGURE 10.10.
Investigation
HYPOTHESIS
An artificial mRNA containing only one repeating base will direct the synthesis of a protein containing only one repeating amino acid.
CONCLUSION
Poly U contains codons for phenylalanine only.
Poly C contains codons for proline only.
ANALYZE THE DATA
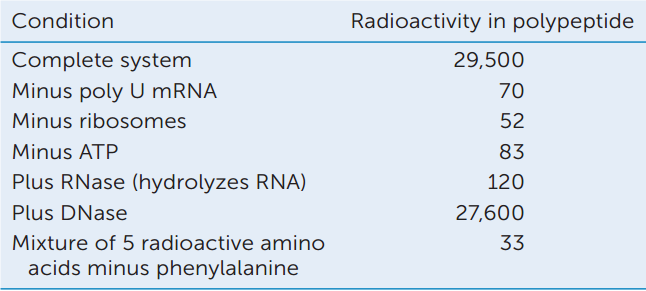
Poly U, an artificial mRNA, was added to a test tube with all other components for protein synthesis (“Complete system”). Other test tubes differed from the complete system as indicated in the table. Samples were tested for radioactive phenylalanine incorporation with the results shown in the table. Explain the results for each of the conditions.
Go to LaunchPad for discussion and relevant links for all INVESTIGATION figures.
a M. W. Nirenberg and J. H. Matthaei. 1961. Proceedings of the National Academy of Sciences USA 47: 1588-1602.

Go to ANIMATED TUTORIAL 10.3 Deciphering the Genetic Code
PoL2e.com/at10.3
Other scientists later found that an artificial mRNA only three nucleotides long—amounting to one codon—could bind to a ribosome, and that the resulting complex could bind to a corresponding tRNA carrying a specific amino acid. Thus, for example, a simple UUU mRNA caused the tRNA carrying phenylalanine to bind to the ribosome. After this discovery, the complete deciphering of the genetic code was relatively simple.
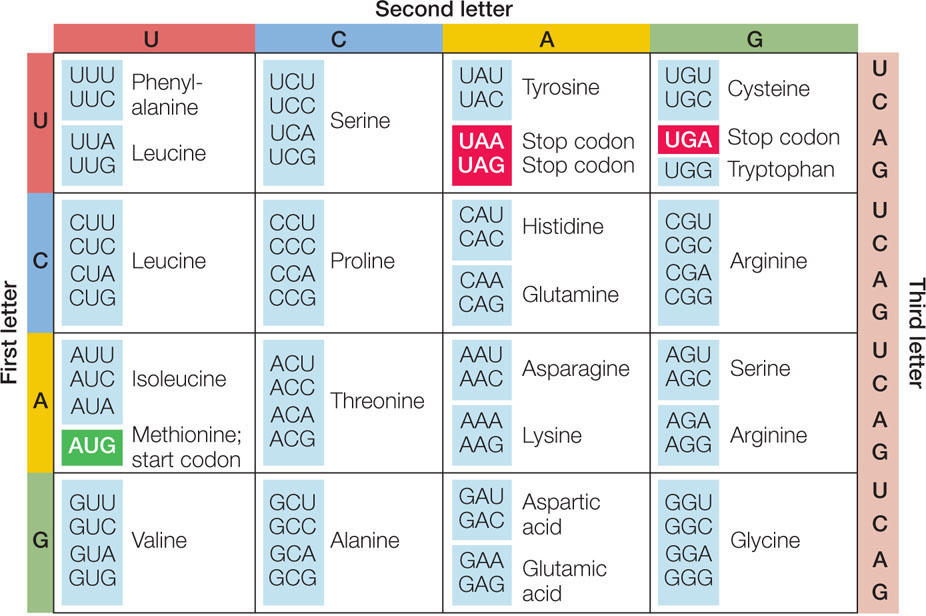
The complete genetic code is shown in FIGURE 10.11. Notice that there are many more codons than there are different amino acids in proteins. All possible combinations of the four available bases give 64 (43) different three-letter codons, yet these codons determine only 20 amino acids. AUG, which codes for methionine, is also the start codon, the initiation signal for translation. The AUG codon is somewhat like the capitalized first word of a sentence, indicating how the sequence of words should be read. Three of the codons (UAA, UAG, and UGA) are stop codons, or termination signals for translation. When the translation machinery reaches one of these codons, translation stops and the polypeptide is released.
Go to ACTIVITY 10.2 The Genetic Code
PoL2e.com/ac10.2
204
The Genetic Code is Redundant But Not Ambiguous
The 60 codons that are not start or stop codons are far more than enough to code for the other 19 amino acids—and indeed, there is more than one codon for almost all the amino acids. Thus we say that the genetic code contains redundancies. For example, leucine is represented by six different codons (see Figure 10.11). Only methionine and tryptophan are represented by just one codon each.
A redundant code should not be confused with an ambiguous code. If the code were ambiguous, a single codon could specify two (or more) different amino acids, and there would be doubt about which amino acid should be incorporated into a growing polypeptide chain. The genetic code is not ambiguous: a given amino acid may be encoded by more than one codon, but each codon encodes only one amino acid.
The Genetic Code Is (Nearly) Universal
The same genetic code is used by all the species on our planet. Thus the code must be an ancient one that has been maintained intact throughout the evolution of living organisms. Exceptions are known: within mitochondria and chloroplasts, the code differs slightly from that in prokaryotes and in the nuclei of eukaryotic cells; and in one group of protists, the codons UAA and UAG encode glutamine rather than functioning as stop codons. The significance of these differences is not yet clear. What is clear is that the exceptions are few.
The common genetic code unifies life, and indicates that all life came ultimately from a common ancestor. The genetic code probably originated early in the evolution of life. The common code also has profound implications for genetic engineering, as we will see in Chapter 13, since it means that the code for a human gene is the same as that for a bacterial gene. It is therefore impressive, but not surprising, that a human gene can be expressed in Escherichia coli via laboratory manipulations, since these cells speak the same “molecular language.”
The codons shown in Figure 10.11 are for mRNA. The base sequence of the template DNA strand is complementary and antiparallel to these codons. Thus, for example, 3′-ACC-5′ in the template DNA strand corresponds to tryptophan (which is encoded by the mRNA codon 5′-UGG-3′). However, the coding DNA strand has the same sequence as the mRNA (but with T’s instead of U’s). By convention, gene sequences are usually shown as the sequence of the coding strand, beginning at the 5′ end.
APPLY THE CONCEPT: The genetic code in RNA is translated into the amino acid sequences of proteins
The double-stranded DNA sequence for the coding region of a short peptide is:
5′-A T G T T T T C G A C G T G C G A T T G A -3′
3′-T A C A A A A G C T G C A C G C T A A C T -5′
1 5 10 15 20
- Which strand of DNA (top or bottom) is transcribed into mRNA? Explain.
- What is the amino acid sequence of the peptide coded for by the DNA?
- A mutant strain has a C-G base pair at position 5 instead of the T-A pair shown here. What is the amino acid sequence of the peptide? Explain.
- A mutation at base pair 15 results in a peptide that is not full length. What point mutation would cause this? Explain.
205
Point mutations confirm the genetic code
Strong support for the assignment of codons in the genetic code comes from point mutations (changes in single nucleotides within a sequence). These have been studied in a wide variety of organisms. When point mutations within the coding region of a gene are compared with the amino acid sequences in the encoded polypeptide, they are consistent with the genetic code.
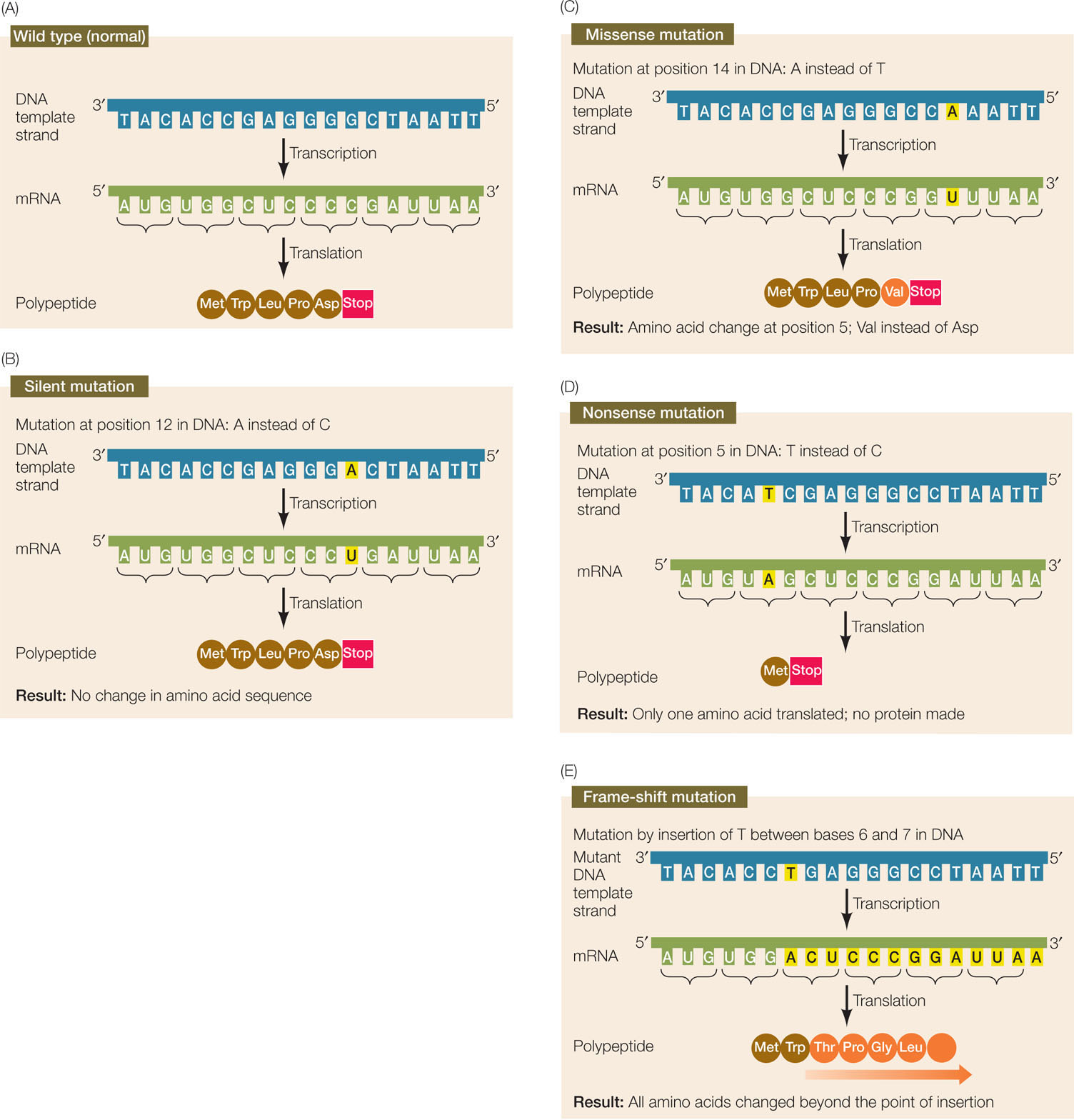
In Concept 9.3 we discussed mutations in terms of their effects on phenotypes. We can now define types of mutations in terms of their effects on polypeptide sequences (FIGURE 10.12):
- Silent mutations can occur because of the redundancy of the genetic code. For example, the codons CCG and CCU are both translated from mRNA as proline (Pro). So a change in the template strand of the DNA from 3′-GGC to 3′-GGA (a mutation from C to A) will not cause any change in amino acid sequence.
- Missense mutations result in a change in the amino acid sequence. For example, GAU in mRNA is translated as aspartic acid (Asp), whereas a mutation that results in GUU is translated as valine (Val).
- Nonsense mutations result in a premature stop codon. For example, the codon UGG is translated as the amino acid tryptophan (Trp). A DNA point mutation could convert this to the stop codon UAG, which acts as a translation termination signal. If this occurred, the polypeptide chain would end at the amino acid translated just before the stop codon.
- Frame-shift mutations result from the insertion or deletion of one or more base pairs within the coding sequence. Since the genetic code is read as sequential, nonoverlapping triplets, this can cause new triplets to be read, and an altered sequence of amino acids in the resulting polypeptide.

Go to ANIMATED TUTORIAL 10.4 Genetic Mutations Simulation
PoL2e.com/at10.4
CHECKpoint CONCEPT 10.3
- What are the characteristics of the genetic code?
- If the artificial mRNA UAUAUAUAUA… is used in a test tube protein synthesis system, what would be the amino acid sequence of the resulting polypeptide chain? Note that in this system translation can begin anywhere on the mRNA.
- A deletion of two consecutive base pairs in the coding region of DNA causes a frame-shift mutation. But a deletion of three consecutive base pairs causes the deletion of only one amino acid, with the rest of the polypeptide chain intact. Explain.
The mRNA with its coding information is translated into an amino acid sequence at the ribosome. We will now consider this process.