Inference for a two-
We often gather data and arrange them in a two-
EXAMPLE 3 Treating cocaine addiction
Cocaine addicts need the drug to feel pleasure. Perhaps giving them a medication that fights depression will help them resist cocaine. A three-
| Group | Treatment | Subjects | Successes | Percent |
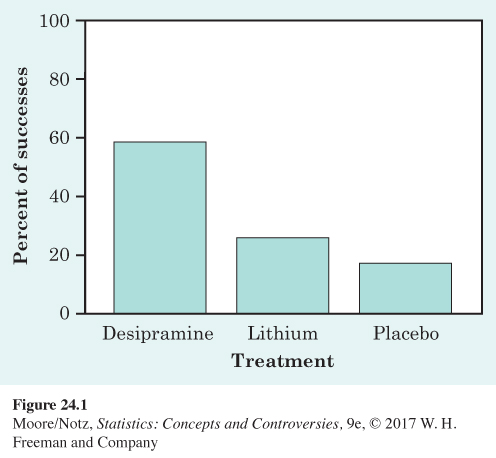
| 1 | Desipramine | 24 | 14 | 58.3 |
| 2 | Lithium | 24 | 6 | 25.0 |
| 3 | Placebo | 24 | 4 | 16.7 |
The sample proportions of subjects who did not use cocaine are quite different. In particular, the percentage of subjects in the desipramine group who did not use cocaine was much higher than for the lithium or placebo group. The bar graph in Figure 24.1 compares the results visually. Are these data good evidence that there is a relationship between treatment and outcome in the population of all cocaine addicts?
The test that answers this question starts with a two-
| Success | Failure | Total | |
|---|---|---|---|
| Desipramine | 14 | 10 | 24 |
| Lithium | 6 | 18 | 24 |
| Placebo | 4 | 20 | 24 |
| Total | 24 | 48 | 72 |
575
Our null hypothesis, as usual, says that the treatments have no effect. That is, addicts do equally well on any of the three treatments. The differences in the sample are just the result of chance. Our null hypothesis is
H0: There is no association between the treatment an addict receives and whether or not there is success in not using cocaine in the population of all cocaine addicts.
Expressing this hypothesis in terms of population parameters can be a bit complicated, so we will be content with the verbal statement. The alternative hypothesis just says, “Yes, there is some association between the treatment an addict receives and whether or not he succeeds in staying off cocaine.” The alternative doesn’t specify the nature of the relationship. It doesn’t say, for example, “Addicts who take desipramine are more likely to succeed than addicts given lithium or a placebo.”
To test H0, we compare the observed counts in a two-
576
Expected counts
The expected count in any cell of a two-
Try it. For example, the expected count of successes in the desipramine group is
If the null hypothesis of no treatment differences is true, we expect eight of the 24 desipramine subjects to succeed. That’s just what we guessed.
NOW IT’S YOUR TURN
Question 24.1
24.1 Video-
| Grade Average | |||
| A’s and B’s | C’s | D’s and F’s | |
| Played games | 736 | 450 | 193 |
| Never played games | 205 | 144 | 80 |
Find the expected count of students with average grades of A’s and B’s who have played computer, video, online, or virtual reality games under the null hypothesis that there is no association between grades and game playing in the population of students. Assume that the sample was a random sample of students in Connecticut high schools.
577