Promoter Sequences Alter the Strength and Frequency of Transcription
In E. coli, RNA polymerase binds to DNA within a 100 bp region stretching from about 70 bp before the transcription start site to about 30 bp beyond it. By convention, the DNA base pairs corresponding to the beginning of an RNA molecule are given positive numbers (+1 is the transcription start site), and those preceding the RNA start site are given negative numbers. The promoter region in E. coli thus extends between positions −70 and +30.
As mentioned previously, the most common sigma factor in E. coli is σ70. Analyses and comparisons of the bacterial promoters recognized by a σ70-containing RNA polymerase holoenzyme have revealed similarities in two short sequences centered about positions −10 and −35 (Figure 15-10). These sequences are important interaction sites for σ70. Although the sequences are not identical for all bacterial promoters in this class, certain nucleotides that are particularly common at each position form a consensus sequence. The consensus sequence centering at the −10 region is 5′-TATAAT-3′; the consensus sequence at the −35 region is 5′-TTGACA-3′. A third AT-rich recognition element, the upstream promoter (UP) element, occurs between positions −40 and −60 in the promoters of certain highly expressed genes. The UP element is bound by one of the α subunits of RNA polymerase. The efficiency with which an RNA polymerase binds to a promoter and initiates transcription is determined in large measure by the −10, −35, and UP sequences, the spacing between −10/−35 and the UP element, and the distance of the UP element from the transcription start site.
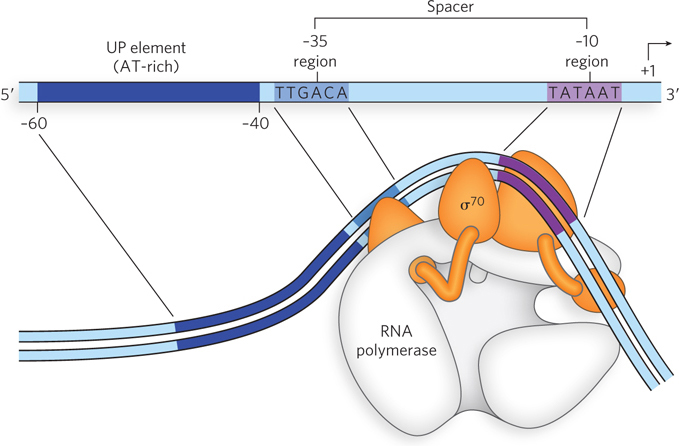
Figure 15-10: Features of bacterial promoters recognized by σ70. Different sigma factors recognize distinct promoter elements. The σ70 factor recognizes the −10 and −35 sequences, shown here. Promoters recognized by other sigma factors have other consensus sequences in the promoter region. The right-angle arrow at the +1 position indicates the transcription start site.
Many independent lines of evidence attest to the functional importance of the sequences in the −10 and −35 regions. Mutations that affect the function of a given promoter often involve a single base-pair change in these regions. Variations in the consensus sequence also affect the efficiency of RNA polymerase binding and transcription initiation. A change in just one base pair can decrease the rate of binding by several orders of magnitude. The promoter sequence thus establishes a basal level of transcription that can vary greatly from one E. coli gene to the next.
Experiments with the Lac promoter in E. coli demonstrated the importance of promoter sequence to gene expression (Figure 15-11). The Lac promoter drives the expression of genes in the lac operon, which encodes proteins that metabolize the sugar lactose. In fact, the classic experiments that first revealed transcription to be a regulated event were performed on the lac operon (explored in Chapter 20). The Lac promoter sequence is close to, but not exactly the same as, the bacterial consensus promoter sequence for σ70-containing RNA polymerase holoenzymes. In the experiment shown in Figure 15-11, mutations were introduced into the Lac promoter to make it conform to the consensus, and the mutated promoters were used to drive the expression of the enzyme β-galactosidase (β-gal, one of the lac operon proteins). Promoter activity was evaluated by a reaction in which β-gal converts a colorless substrate into a chemical with blue color: the more β-gal expressed, the deeper the blue color produced. The results showed that the mutations bringing the promoter into consensus tended to confer greater levels of protein expression.
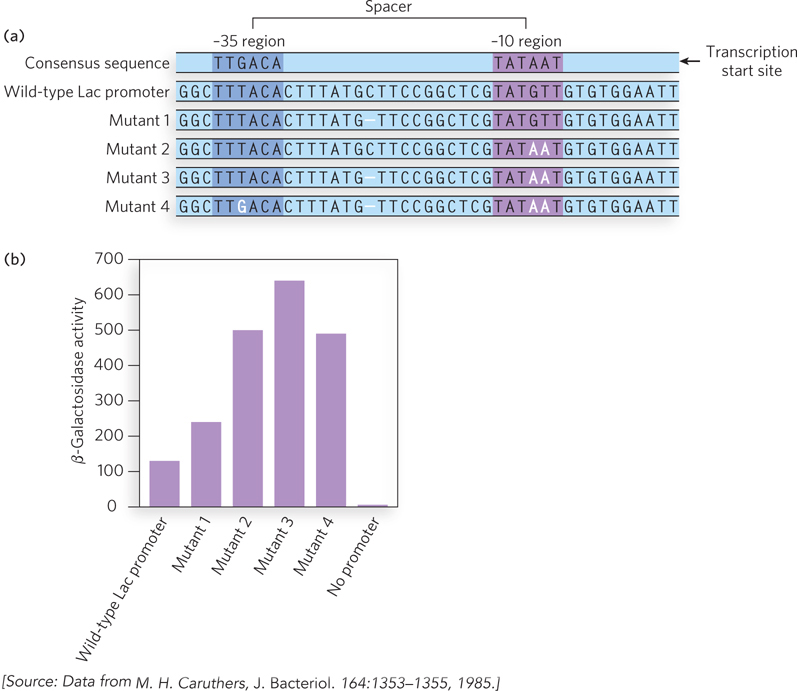
Figure 15-11: Mutational analysis of a bacterial promoter. The Lac promoter, driving the lac operon, has a sequence close to the σ70 consensus sequence. (a) Mutations are created that make the promoter conform to the consensus; red dashes indicate lack of a nucleotide at that position. The spacer length matters because it governs the helical orientation of the two consensus sites. (b) Mutation results in increased expression and activity of β-galactosidase.
Sigma Factors Specify Polymerase Binding to Particular Promoters
Escherichia coli has at least seven different kinds of sigma factors (Table 15-2); the number varies for other bacteria. Each RNA polymerase molecule contains only one σ subunit, which directs the polymerase enzyme to bind a specific type of promoter sequence. The σ70 factor binds reversibly to RNA polymerase and is essential for general transcription in exponentially growing cells. However, it can be replaced by alternative sigma factors that trigger the transcription of genes involved in diverse functions, including stress responses, changes in cell shape, and nitrogen uptake. A sigma factor associates with the RNA polymerase core only transiently, separating from it after transcription initiation.
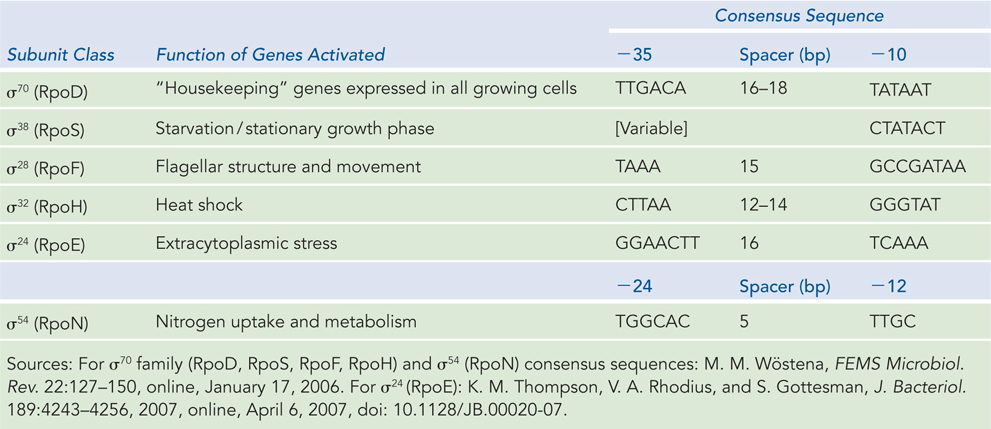
Figure 15-2: Some E. coli Sigma Factors
Through their interactions with specific promoter classes, sigma factors direct RNA polymerase holoenzymes to the transcription start sites of genes associated with particular promoters, depending on the needs of the cell. All sigma factors recognize specific variants of the −10 and −35 regions of the promoter—except for σ54, which binds to sequences in the −12 and −24 regions. For example, when cells experience a sudden temperature increase or other environmental stress, RNA polymerase containing a σ32 (Mr 32,000) subunit binds to so-called heat shock promoters and enhances the transcription of heat shock genes. By using different σ subunits, the cell can coordinate the expression of sets of genes, permitting major changes in cell physiology.

Carol Gross
Because different sigma factor proteins are similarly organized, researchers can exchange bits of sequence between them to examine the effect on promoter recognition and transcription activation. Carol Gross and her colleagues at the University of California, San Francisco, used this approach to dissect the mechanisms that distinguish between “housekeeping” sigma factors (σ70 class) and specialized sigma factors such as σ32. Gross’s work showed that σ32, and other specialized sigma factors, have an altered 17 amino acid segment that reduces binding affinity for the promoter. As a result, these sigma factors require the exact consensus sequences at the −10 and −35 regions. In other words, σ70 is rather permissive in the promoters it will bind to—more deviations from the σ70 consensus are allowed—but σ32 is much more selective, binding only to promoters that have the exact σ32 consensus sequence. Since many promoters deviate from the consensus, specialized sigma factors bind only to the much smaller subset of promoters that contain the optimal consensus upstream sequences. Gross and colleagues found that converting the σ32 amino acid sequence to be the same as that found in housekeeping sigma factors such as σ70 decreased the requirement for −10 and −35 promoter conservation and increased transcription initiation at nonoptimal promoters.
Some sigma factors, such as σ38, direct RNA polymerase to genes that respond to cellular stresses, including osmotic shock, temperature changes, and starvation; an example is the gene osmY. The process can be monitored using a combination of DNA “footprinting” and an assay for mRNA levels (Figure 15-12a). DNA footprint analysis can identify a region of DNA bound by a protein, such as a sigma factor or transcription factor (see this chapter’s Moment of Discovery). In this kind of experiment, DNA thought to contain sequences recognized by a DNA-binding protein is isolated and radiolabeled at one end (see Figure 15-12a, step 1). A DNA-binding protein is added to a sample of the DNA (step 2; in this case, σ38 and σ70 are the test DNA-binding proteins), and chemical or enzymatic reagents are used to cleave the DNA randomly in the samples with and without the DNA-binding protein (step 3), averaging one cut per molecule. When the sets of cleavage products are compared side by side after separation by gel electrophoresis (step 4), a relatively uniform ladder of fragments appears for the sample not treated with the DNA-binding protein. A gap, or “footprint,” in the ladder of DNA fragments in the protein-containing sample identifies the region of DNA that is bound by the protein and thus protected from cleavage. In the case of osmY, the promoter DNA can be bound by RNA polymerase with σ38, but not σ70. Monitoring of the transcription of the osmY gene reveals that as the osmotic strength of the culture medium is increased, the promoter for the osmY gene is activated to allow transcription, whereas a control promoter that uses σ70 (the lacUV5 promoter) is not activated (Figure 15-12b). DNA footprinting is a valuable tool for mapping the binding sites of transcription factors and other DNA-binding proteins (see the How We Know section at the end of this chapter).
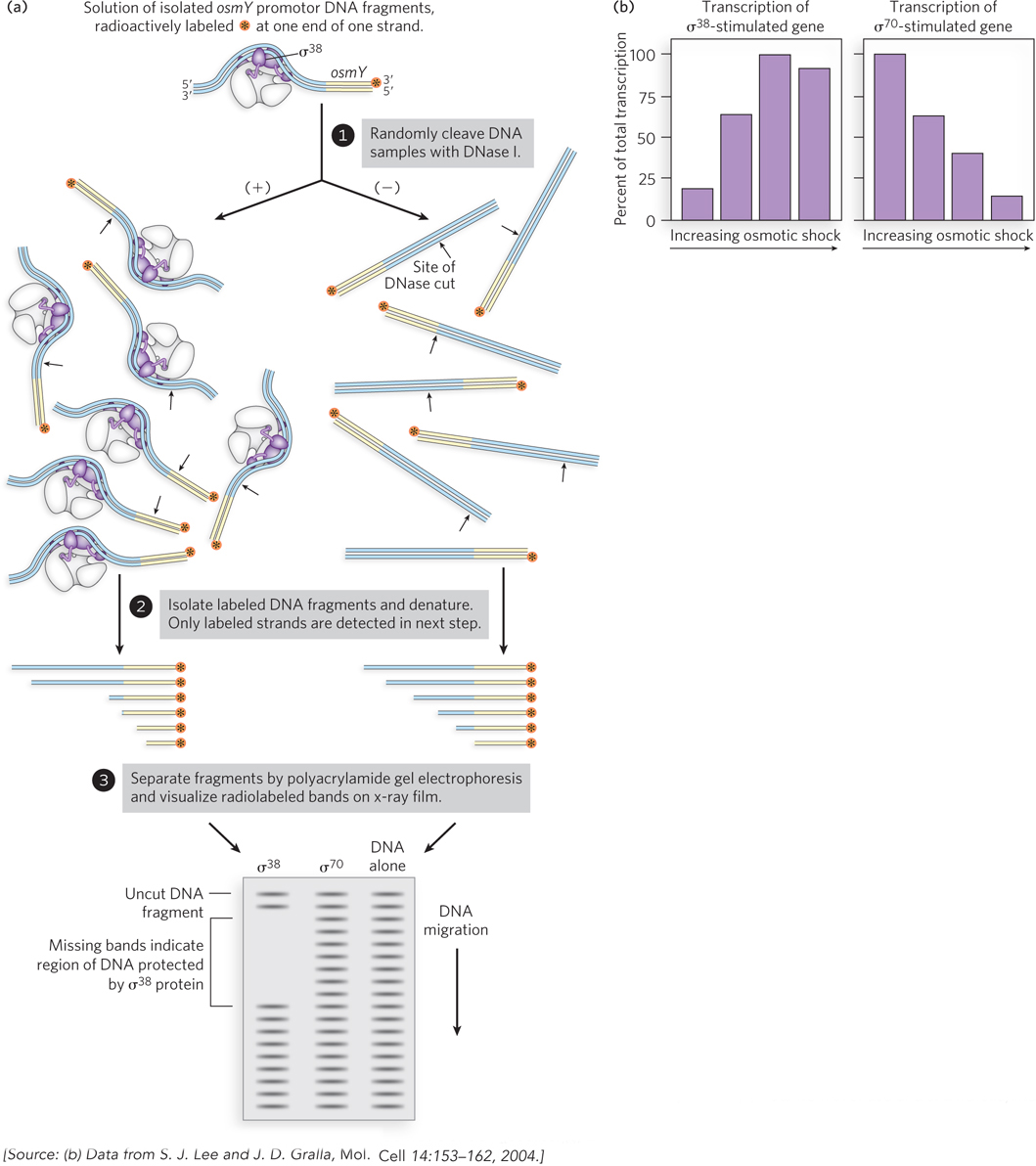
Figure 15-12: DNA footprinting shows which sigma factor binds to a promoter in response to osmotic shock. The promoter for the osmY gene is recognized by σ38, a sigma factor that regulates gene expression in response to osmotic shock. (Other σ38-targeted genes behave similarly.) (a) Footprinting analysis shows that the promoter is bound by σ38. (b) When cells are subjected to osmotic shock, transcription of osmY increases. The graphs show the fraction of total transcripts that derive from either σ38 or σ70 promoters as a function of increasing osmotic shock.
Structural Changes Lead to Formation of the Transcription-Competent Open Complex
The major type of bacterial RNA polymerase holoenzyme, as we have seen, contains a sigma factor of the σ70 class. The most common variant of the holoenzyme contains an unrelated sigma factor, σ54, which is the sole representative of the σ54 class. The process of transcription initiation by σ70-containing versus σ54-containing polymerase holoenzymes is mechanistically distinct. In both cases, the holoenzyme binds to its promoter to form what is initially a closed complex, with the DNA maintaining its double-stranded structure; formation of this closed complex is readily reversible. In complexes with the σ70-class factor, the closed complex can spontaneously convert to a transcription-competent open complex, in a process of isomerization (Figure 15-13a). In contrast, σ54-containing holoenzymes require specialized activator proteins of the AAA+ family (see Chapters 5 and 11) to catalyze conversion to the open complex, with concomitant ATP hydrolysis (Figure 15-13b). Upstream activator sequences (UASs) are brought in contact with promoter-bound σ54-RNA polymerase through DNA looping, a step that is often facilitated by auxiliary DNA-binding and bending proteins such as integration host factor (IHF). In both cases, energetically favorable conformational changes in the RNA polymerase accompany an opening of the DNA duplex, exposing the template and coding strands in the −11 to +3 region. In contrast to the σ70 open complex, formation of the σ54 open complex is irreversible and ensures that transcription will initiate.
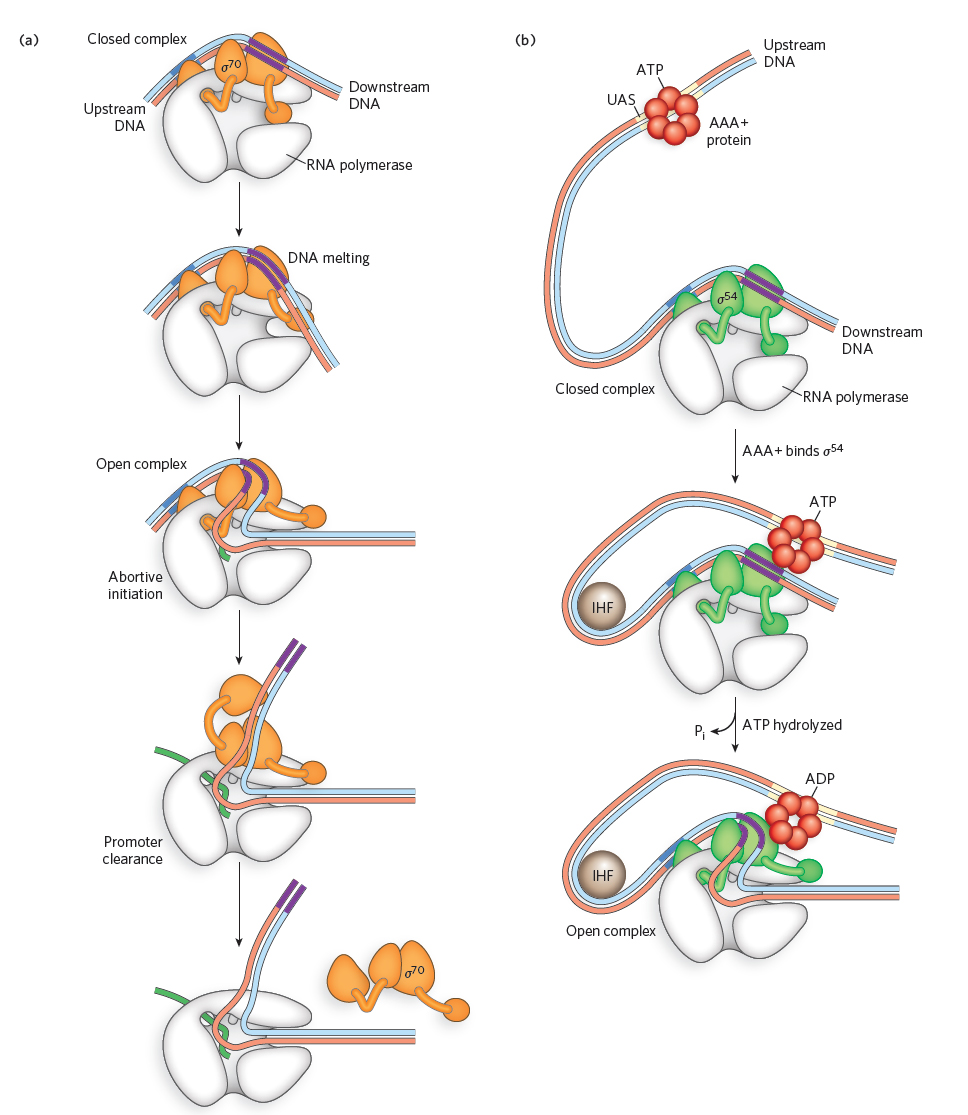
Figure 15-13: Conversion of the closed complex to the open complex by sigma factors. (a) σ70 induces strand opening and formation of the open complex, without the need for ATP or other factors. All other sigma factors except σ54 function in the same way. (b) σ54 requires an AAA+ protein to form the open complex at a promoter. The AAA+ protein is a hexamer that binds an upstream activator sequence (UAS), then also binds σ54 in the closed complex, creating a DNA loop. Such DNA looping is often facilitated by auxiliary DNA-binding and bending proteins such as integration host factor (IHF). AAA+ hydrolyzes a bound ATP, using the favorable energetics of this reaction to drive opening of the complex.
To understand the structural basis for closed-to-open complex isomerization, it is helpful to examine the molecular structure of the RNA polymerase holoenzyme. In the open complex, several channels provide access to the core of the enzyme (Figure 15-14). One channel enables rNTPs to enter the catalytic site, and another allows the growing RNA polynucleotide to exit the enzyme during the elongation phase of transcription. A third channel provides space for DNA to enter the catalytic center in double-stranded form, between the two pincers of the claw-shaped complex. The two strands separate and are held apart by a cleft, or pin, in the polymerase structure that helps keep the transcription bubble open within the enzyme. But by the time the DNA exits the RNA polymerase, it is duplex DNA again.
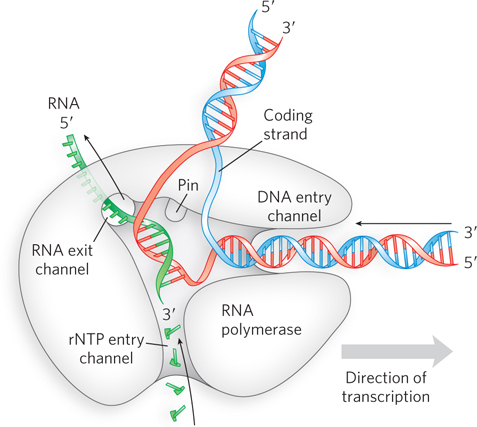
Figure 15-14: RNA polymerase channels. Distinct channels in RNA polymerase allow the DNA to enter as double-stranded DNA and to peel apart within the polymerase so that 8 bp form between the template strand and the growing RNA transcript. Two other channels provide entry for rNTPs and an exit for the transcript.
Two significant structural changes result from the conversion of the closed to the open complex. First, the pincers close around the DNA downstream from the transcription start site. Second, the negatively charged N-terminus of the sigma factor moves from the active-site cleft of the polymerase (where the chemical reaction occurs) to an exterior position 50 Å away, allowing the DNA template strand to take its place. In the open position, the RNA polymerase is ready to begin RNA synthesis.
Initiation Is Primer-Independent and Produces Short, Abortive Transcripts
In contrast to DNA polymerases, which require an oligonucleotide base-paired with the template strand in order to prime DNA synthesis, RNA polymerases can begin transcription with a single nucleotide—they do not depend on a preexisting strand from which to extend new RNA. RNA polymerases must therefore bind and hold two nucleotides in place on the DNA template for long enough, and in the correct orientation, to catalyze phosphodiester bond formation between them. Once this occurs, and for the first 8 to 10 phosphodiester bonds formed, there is a high probability that the polymerase will release the transcript from the template without extending it further. If this happens, the assembled polymerase holoenzyme begins RNA synthesis again on the same template. This process is called abortive initiation (Figure 15-15). Occasionally, the polymerase holds on to the transcript long enough to extend it beyond 10 nucleotides, at which point the RNA becomes stable. After a successful initiation, transcription enters the elongation phase and continues along the DNA template until it reaches a termination signal.
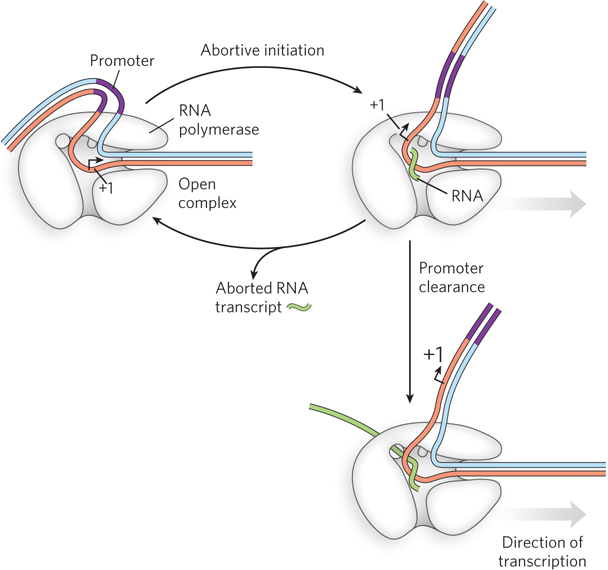
Figure 15-15: Abortive initiation. RNA polymerase undergoes a cycle of abortive initiation in which short RNA transcripts are synthesized and released, until the promoter site is cleared. The nascent transcript is then in position in the RNA exit channel, and initiation is successfully completed.
Interestingly, these two properties—beginning without a primer and initially producing abortive transcripts—are universal characteristics of DNA-dependent RNA polymerases. Even the single-subunit bacteriophage polymerases exhibit these properties. The molecular structures of the phage T7 RNA polymerase and the bacterial RNA polymerase suggest explanations for both of these characteristics. Abortive initiation seems to occur because, early in initiation, the RNA exit channel (see Figure 15-14) is blocked—either by part of the polymerase itself, in the case of T7 polymerase, or by part of the sigma factor. For a transcript to extend beyond about 10 nucleotides, a structural transition must take place to unblock the RNA exit channel, a process that occurs only occasionally during the initial stage of transcription. In bacteria, this process may weaken the affinity of the sigma factor within the polymerase complex, explaining why the σ subunit often falls off the complex during elongation of the transcript.
Transcription Elongation Is Continuous until Termination
Once RNA polymerase enters the elongation phase, the enzyme does not release the DNA template until it encounters a termination sequence. In this mode the polymerase is said to be processive, moving smoothly along the template, synthesizing the complementary RNA strand and dissociating only when the transcript is complete. During transcript elongation, the DNA moves through the polymerase active site, as observed in the polymerase open complex (see Figure 15-14). The strands of the DNA double helix separate just before the site of catalysis, held apart by a structural protrusion within the polymerase, then re-form as a double helix on exiting the polymerase interior. At any given time during elongation, 8 to 9 nucleotides of the RNA transcript remain base-paired with the DNA template, while the rest of the transcript is stripped off and directed out through the RNA exit channel.
During elongation, the polymerase attempts to ensure the accuracy of transcription by pyrophosphorolysis, in which the catalytic reaction runs in reverse whenever the polymerase stalls along the DNA. This process, known as kinetic proofreading, works because the polymerase tends to stall after incorporating a mismatched base into the growing RNA chain, thus enabling pyrophosphorolysis to remove the incorrect base (Figure 15-16a). Pyrophosphorolysis is also used in proofreading during DNA synthesis (see Chapter 11).
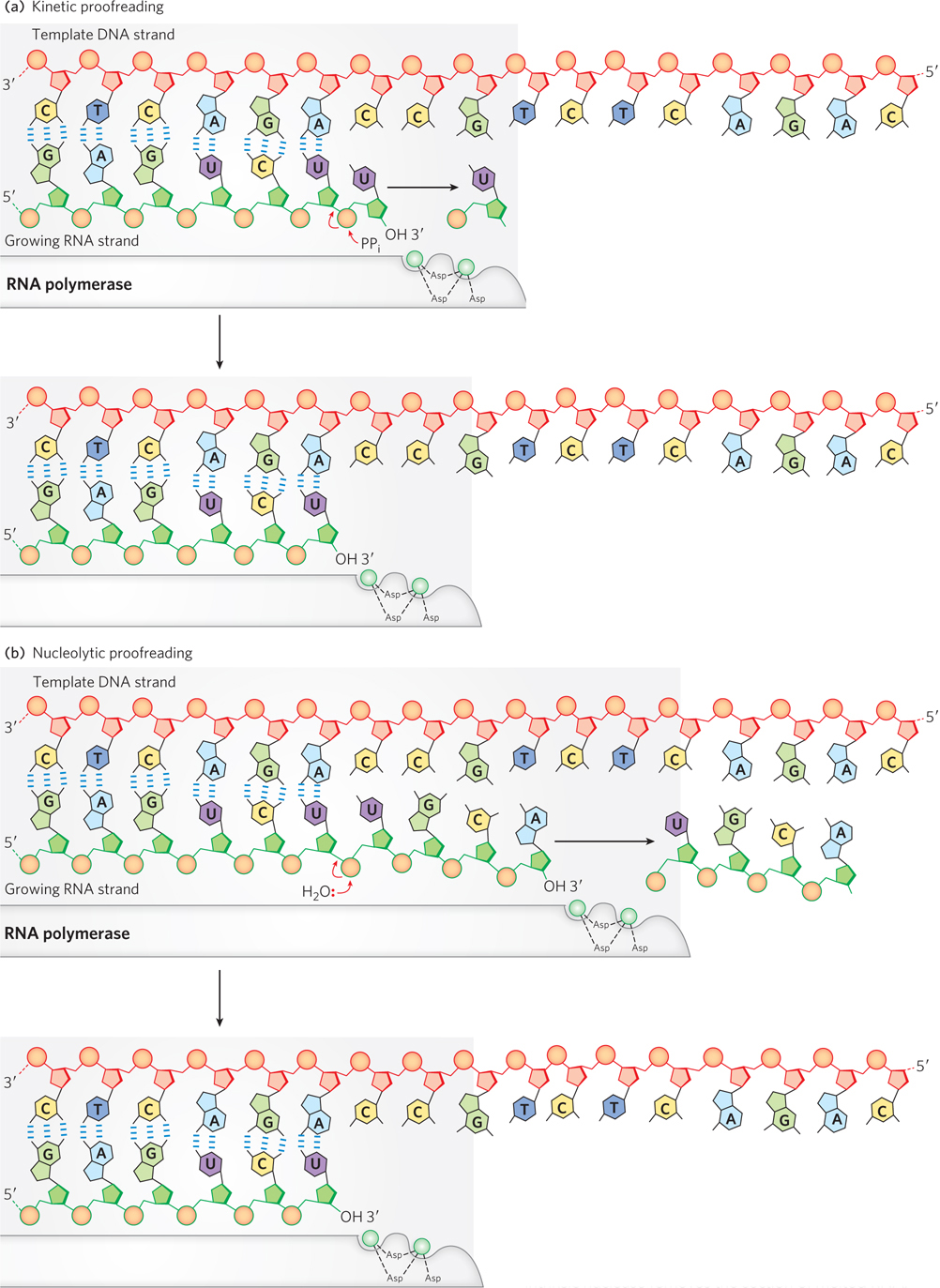
Figure 15-16: Proofreading by RNA polymerase. (a) In kinetic proofreading, the polymerase stalls after incorporating a mismatched base into the growing RNA chain, enabling pyrophosphorolysis to remove the incorrect base. (b) In nucleolytic proofreading, the polymerase backtracks on the DNA, melting several nucleotides of the RNA (i.e., breaking the DNA-RNA base pairs), then an intrinsic nuclease removes the section of melted RNA.
RNA polymerase contains an inherent nuclease activity, providing another means of correcting newly synthesized transcripts by hydrolysis. In this process, known as nucleolytic proofreading, the polymerase reverses direction by one or a few nucleotides and breaks the RNA phosphodiester bond upstream from a mismatched base, removing the error-containing strand (Figure 15-16b).
Despite these proofreading mechanisms, RNA polymerases are generally less accurate than DNA polymerases. Whereas, on average, DNA polymerase makes an error only once per 106 nucleotides incorporated, RNA polymerase makes an error about once per 104 to 105 nucleotides added. This can be tolerated because most transcripts are made in many copies, and one or two error-containing transcripts will be vastly outnumbered by correct transcripts in the cell. In RNA viruses, error-prone transcription can be a survival advantage, enabling the emergence of mutants that can escape detection by host cell immunity.
Bacterial RNA polymerase can synthesize RNA at a rate of 50 to 90 nucleotides per second. Rather than transcribing DNA at a constant pace, however, the enzyme pauses at times throughout the process. Pausing can be detected using single-molecule methods (see the How We Know section at the end of this chapter). Backtracking is a mechanism of pausing in which the RNA polymerase moves backward and peels the 3′ end of the RNA off the DNA template by inserting the end into the rNTP entry channel. This temporarily blocks further movement of the polymerase. Transcription restarts when the enzyme cleaves the peeled-back 3′ end of the transcript, using its intrinsic nuclease activity. This process differs from nucleolytic processing in that there is a time lag, or pause, between the peeling-back process and the cleavage of the RNA strand to restart transcription. Pausing has several possible functions, including providing time for the RNA transcript to fold properly and to be translated synchronously with transcription.
Specific Sequences in the Template Strand Stop Transcription
Transcription stops when the RNA polymerase transcribes through certain sequences in the DNA template. At this point, the RNA polymerase releases the finished transcript and dissociates from the DNA template. E. coli DNA has at least two classes of such termination sequences, one class that relies primarily on structures that form in the RNA transcript and another that requires an accessory protein factor called rho (ρ).
Most ρ-independent termination sequences have two distinguishing features. The first is a region that produces an RNA transcript with self-complementary sequences, permitting the formation of a hairpin structure centered 15 to 20 nucleotides before the projected end of the RNA strand, as shown in Figure 15-17a. (Note that these regions occur only once, at the end of the transcript, whereas the pause sites described above occur at multiple places within the transcript.) The second feature is a highly conserved segment of three A residues in the template strand that are transcribed into U residues near the 3′ end of the hairpin. When a polymerase arrives at such a termination sequence, it stalls. Formation of the hairpin in the newly transcribed RNA disrupts several A=U base pairs in the RNA-DNA hybrid segment and may disturb important interactions between RNA and RNA polymerase, leading to dissociation of the transcript.
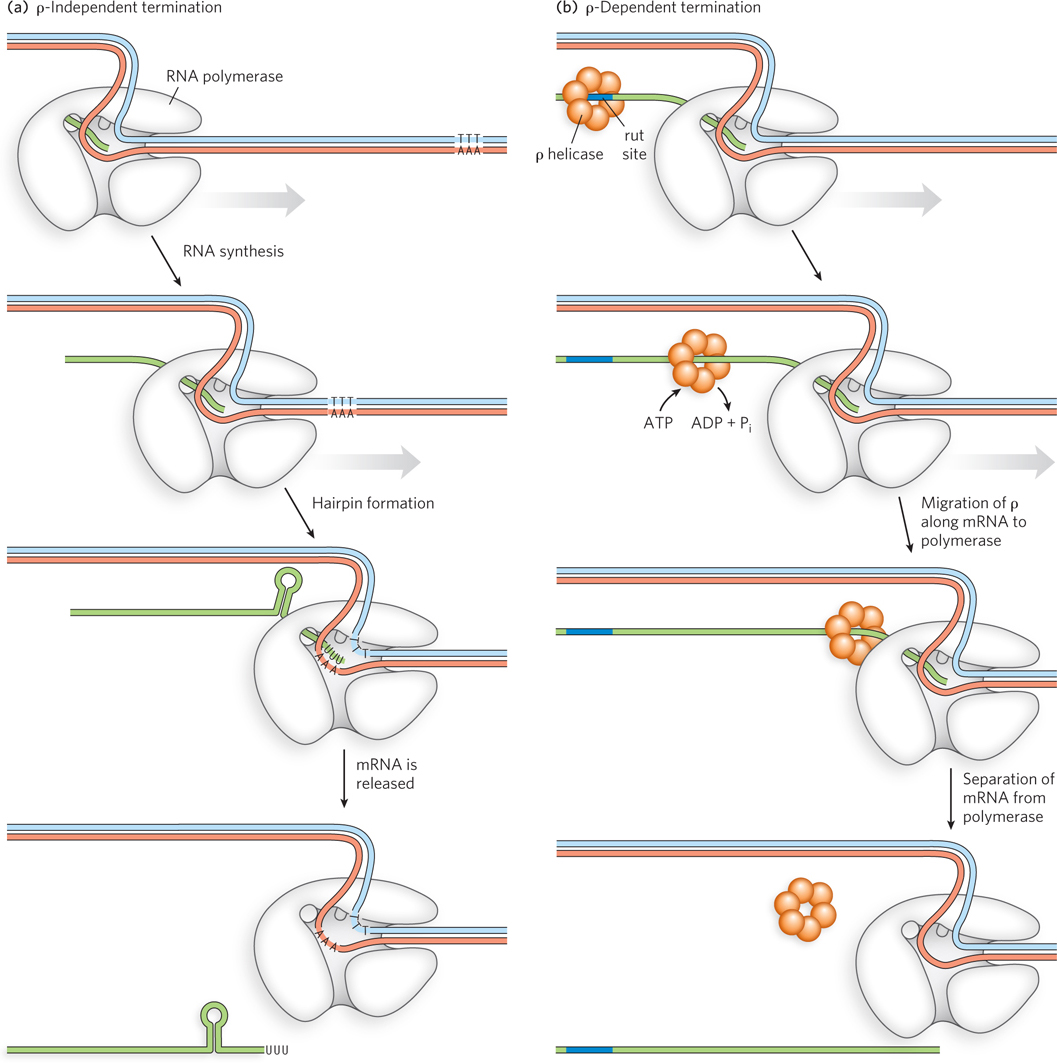
Figure 15-17: Termination of transcription. (a) In ρ-independent termination, an mRNA sequence forms a hairpin, which is followed by three U residues, stalling the polymerase and separating it from the mRNA. (b) RNAs that include a rut site (purple) recruit the ρ helicase, which migrates in the 5′→3′ direction along the mRNA and separates it from the polymerase.
The ρ-dependent terminators lack the sequence of repeated A residues in the template strand but typically include a CA-rich sequence called a rut (rho utilization) site. The ρ factor, a hexameric helicase, binds to RNA polymerase very early in the transcription process. Its ATP-hydrolyzing activity is used to feed the mRNA through the pore in the center of the rho complex during transcription until a rut site is encountered (Figure 15-17b). Here, it contributes to release of the RNA transcript from both the DNA template and the polymerase.
SECTION 15.2 SUMMARY
Transcription begins at specific promoter sequences upstream from the coding sequence in the DNA template. A sigma factor, of which there are several classes in bacteria, binds to the polymerase holoenzyme and recruits it to a particular type of promoter, enabling transcription at subsets of genes in response to environmental stimuli and the needs of the cell.
RNA polymerase first forms a closed complex on promoter DNA, a readily reversible state that is not yet capable of transcription.
On conversion of the closed complex to a transcription-competent open complex, either through spontaneous isomerization or by ATP-dependent conformational change, RNA polymerase begins RNA synthesis without requiring a primer.
Transcription initiation requires promoter clearance, in which the RNA polymerase moves beyond the promoter region of the DNA to begin rapid elongation of the transcript.
During elongation, the RNA polymerase is highly processive, synthesizing transcripts without dissociating from the DNA template.
RNA polymerase corrects errors in newly synthesized transcripts in one of two ways. In kinetic proofreading, stalling of polymerase after a mismatched base is incorporated into the growing RNA chain enables pyrophosphorolysis to remove the incorrect base. In nucleolytic proofreading, the polymerase reverses direction by one or a few nucleotides and hydrolyzes the RNA phosphodiester bond upstream of a mismatched base, removing the error-containing strand.
Termination occurs when the polymerase transcribes through certain DNA sequences, in a process that sometimes requires an accessory factor called rho (ρ).