7.7 7.6 Experiments Versus Observational Studies
The first randomized comparative experiment was published in 1948—a British study of the effectiveness of streptomycin in treating tuberculosis. Randomized comparative experiments quickly became common tools of industrial, academic, and medical research. For example, federal regulations require that the safety and effectiveness of new drugs be demonstrated by randomized comparative experiments. Let’s look at a medical experiment as an example.
EXAMPLE 11![]() St. John’s Wort—Treatment for Depression?
St. John’s Wort—Treatment for Depression?
Although prescription drugs must pass the test of randomized comparative experiments before being sold, herbs and other “natural remedies” are exempt. Because these treatments are so popular, some are now being studied more carefully. Fans of natural remedies often use extracts of the herb St. John’s wort to treat depression. is the herb safe? Does it work? The Journal of the American Medical Association reported a “randomized, double-blind, placebo-controlled clinical trial” in which 200 patients with major depression were assigned at random to take either herb extract or a dummy pill that looked and tasted the same. Results: The herb is safe, but “[i]n this study, St. John’s wort was not effective for treatment of major depression.”
If you read accounts of medical studies, you will often see language like “randomized, double-blind, placebo-controlled clinical trial.” A clinical trial is a medical experiment with actual patients as subjects. Randomized and controlled tell us that this was a randomized comparative experiment (that’s good). A placebo looks like a real treatment but is actually a fake pill that has no medication in it and should not actually have an effect in this study. Here, we encounter a new idea: the importance of the placebo effect, a special kind of confounding.
Placebo Effect DEFINITION
The placebo effect is the tendency of patients to respond favorably to any apparent treatment (even one that is in reality a “fake treatment”) because of their expectations about the treatment.
If depressed patients given St. John’s wort are compared with patients who receive no treatment, the first group gets the benefit of both the herb and the placebo effect. Any beneficial effect that St. John’s wort may have is confounded with the placebo effect. To prevent confounding, it is important that some treatment be given to all subjects in any medical experiment.
Neither the subjects nor the experimenters who worked with them knew which treatment any specific subject received. Subjects might react differently if they knew they were getting “only a placebo.” Knowing that a particular subject was getting “only a placebo” also could influence the health workers who interviewed and examined the subjects. Only the study’s statistician knew which treatment each subject received. Because both the subjects and the health workers were “blind” to this information, this study was considered a double-blind experiment.
Double-Blind Experiment DEFINITION
A double-blind experiment is an experiment in which neither the experimental subjects nor the persons who interact with them know which treatment each subject received.
The difference between the St. John’s wort groups and placebo groups was not statistically significant; that is, the difference was no larger than would be expected when we divide 200 depressed patients at random into two groups and do nothing else. Larger numbers of subjects would give more precise results. It’s unlikely that there is exactly no difference between St. John’s wort and a placebo. If the clinical trial had used 2000 patients rather than 200, it might have picked up a small effect (in either direction). The researchers believed that a group of 200 patients was sufficient to pick up any effect large enough to be medically important.
The logic of experimentation, the statistical design of experiments, and the laws that govern chance behavior combine to give compelling evidence of cause and effect. Only experimentation can produce the most convincing evidence of causation.
By way of contrast, in Example 12, we consider historical statistical evidence linking cigarette smoking to lung cancer. We can’t ethically assign groups of people to smoke or not, so a direct experiment isn’t possible.
EXAMPLE 12![]() Smoking and Health
Smoking and Health
One of the earliest studies linking smoking and lung cancer was conducted by Ernst Wynder and Evarts Graham. This study compared people with and without lung cancer, looking for differences in their backgrounds or habits. The one habit that stood out was smoking. While lung cancer was rare in nonsmokers, among patients with lung cancer, cigarette use was high. The results of Wynder and Graham’s study were reported in a 1950 article in the Journal of the American Medical Association.
One potential problem with Wynder and Graham’s study was that it relied on self-reported smoking habits of people who already had lung cancer and those who did not. People who knew they had lung cancer might be more likely to overestimate how much they smoked, whereas people who did not have lung cancer might be more likely to underestimate how much they smoked.
In January 1952, E. Cuyler Hammond and Daniel Horn, scientists working for the American Cancer Society, designed a different style of study to avoid the potential problem discussed in the previous paragraph. They recruited about 188,000 men between the ages of 50 and 69. Participants completed questionnaires, which asked if they smoked cigarettes, and if so, how often and how many (along with other questions). in November 1952, Doctors Hammond and Horn collected the first follow-up set of data. These data classified participants as alive or dead (or unknown status). For those who had died, the cause of death listed on the official death certificate was recorded.
Hammond and Horn reported their preliminary findings in a 1954 article published in the Journal of the American Medical Association. They found: “The death rate from lung cancer was much higher among men with a history of regular cigarette smoking than among men who never smoked regularly.” They concluded their article stating that it was their opinion that a cause-and-effect relationship existed between regular smoking and lung cancer.
Look back at the two studies described in Example 12. The researchers could not impose treatments of smoking or not smoking on the participants in their studies. Instead, they recorded participants’ smoking status and then observed associations between smoking and other data they collected from the participants. These studies are examples of observational studies.
Observational Study DEFINITION
An observational study does not try to manipulate the environment (such as by assigning treatments to people); it simply observes the measurements of variables of interest that result from people’s free choices. This kind of study is generally done when assignment of a treatment to a person is unethical (e.g., smoking while pregnant) or impossible (e.g., ethnicity).
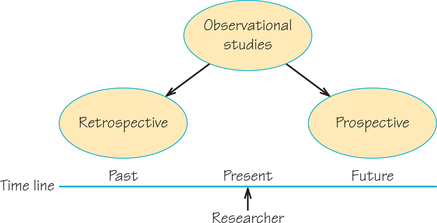
For the Wynder and Graham study, participants belonged to one of two groups, those diagnosed with lung cancer and those not diagnosed with lung cancer. The researchers then collected data on participants’ backgrounds, including medical history and smoking habits. They searched for a connection between the data on participants’ pasts and their current status as having or not having lung cancer. This is an example of a retrospective study.
Retrospective Study DEFINITION
A retrospective study starts with an outcome (e.g., a group of cancer and noncancer patients) and then looks back to examine exposures to suspected risk or protective factors that might be linked to that outcome.
On the other hand, the Hammond and Horn study recruited healthy participants and gathered data about their backgrounds—including medical history and smoking habits. Then they followed them forward in time for a period of years to see which participants died and from what causes. This is an example of a prospective study.
Prospective Study DEFINITION
A prospective study starts with a group and watches for outcomes (e.g., the development of cancer or remaining cancer-free) during the study period and relates this to suspected risk or protective factors that might be linked to the outcomes.
Figure 7.4 summarizes the differences between retrospective and prospective observational studies.
Self Check 7
Researchers investigating the connection between serial killers and child abuse identified a group of convicted serial killers and then found out which of them had a history of childhood abuse. Is this an example of a retrospective or prospective study?
(a) ˆp=6231005≈0.6199ˆp±2√ˆp(1−ˆp)n=0.6199±2√(0.6199)(0.3801)1005=0.6199±0.0306 or 61.99±3.06%=0.5893 to 0.6505 or 58.93% to 65.05%
(b) The margins of error are close. In fact, if rounded to one decimal place, the margins of error are both 3.1%.
Based on many studies, we can say that the connection between smoking and lung cancer is statistically significant. That is, it is far stronger than would occur by chance. We can be confident that something other than chance links smoking to cancer. But observation of samples cannot tell us what factors other than chance might be at work. Perhaps some other factor is involved, such as differences in diet or exposure to air pollution. Perhaps there is something in the genetic makeup of some people that predisposes them to both nicotine addiction and lung cancer. If so, we would observe a strong link even if smoking itself had no effect on the lungs.
However, the statistical evidence that points to cigarette smoking as a cause of lung cancer is about as strong as nonexperimental evidence can be. First, the connection has been observed in many studies in numerous countries. This eliminates factors peculiar to one group of people or to one specific study design. Second, there is a dose–response relationship: People who smoke more are more likely to get lung cancer than those who smoke less, and quitting cigarettes reduces the cancer risk. Third, specific ways in which smoking could cause cancer have been identified; cigarette smoke contains tars that have been shown by experiments to cause tumors in animals. Finally, no plausible alternative explanation is available. For example, the genetic hypothesis cannot explain the increase in lung cancer among women that occurred as more and more women became smokers. Also, the hypothesis was not supported by studies of identical twins where only one smoked.
It is very difficult and complicated to amass convincing evidence from observational studies and rule out all possible alternative explanations. This is why we have a strong preference for the more conclusive statistical evidence that we get from randomized comparative experiments when it is possible and ethical to conduct them. Despite their status as the “gold standard” of research, however, experiments can also have weaknesses. The most common of these is a contrived condition that makes it hard to say how far results may apply beyond a controlled laboratory setting.
EXAMPLE 13![]() Is the Experiment Realistic?
Is the Experiment Realistic?
Clinical trials give medical treatments to actual patients with the condition that the treatments are supposed to help. But some experiments are less realistic in terms of how well experimental conditions align with the usual circumstances of what is of greatest interest. For example, a researcher studying stages and cycles of sleep observes patients overnight in a special “sleep lab” that can monitor their electroencephalography (EEG) waves and other data. However, individuals may sleep quite differently in a lab setting than in the natural sleeping environment of their bedroom at home.
Another type of example is that some studies on animals may be limited in how reliably their conclusions might apply to humans. Penicillin, for instance, is highly toxic to guinea pigs, but it has been a very helpful medicine for humans.
These are not statistical questions. Researchers must use their understanding of their academic domain to judge how far their results apply. Good statistical design enables us to trust results for the participants in the study at hand, but additional knowledge and judgment are needed to decide the extent to which conclusions might be generalized to other settings.
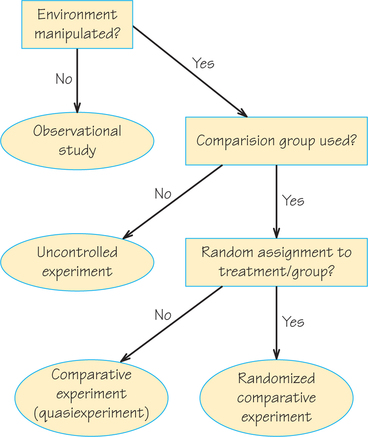
Figure 7.5 gives a conceptual overview of the types of designs we have covered in these last two sections.