15.4
The Dynamic Genome: More Transposable Elements Than Ever Imagined
15.4
The Dynamic Genome: More Transposable Elements Than Ever Imagined
Transposable elements were first discovered with the use of genetic approaches. In these studies, the elements made their presence known when they transposed into a gene or were sites of chromosome breakage or rearrangement. After the DNA of transposable elements was isolated from unstable mutations, scientists could use that DNA as molecular probes to determine if there were more related copies in the genome. In all cases, at least several copies—
Scientists wondered about the prevalence of transposable elements in genome s. Were there other transposable elements in the genome that remained unknown because they had not caused a mutation that could be studied in the laboratory? Were there transposable elements in the vast majority of organisms that were not amenable to genetic analysis? Asked another way, do organisms without mutations induced by transposable elements nonetheless have transposable elements in their genomes? These questions are reminiscent of the philosophical thought experiment, If a tree falls in the forest and no one is around to hear it, does it make a sound?
Large genomes are largely transposable elements
Long before the advent of DNA-
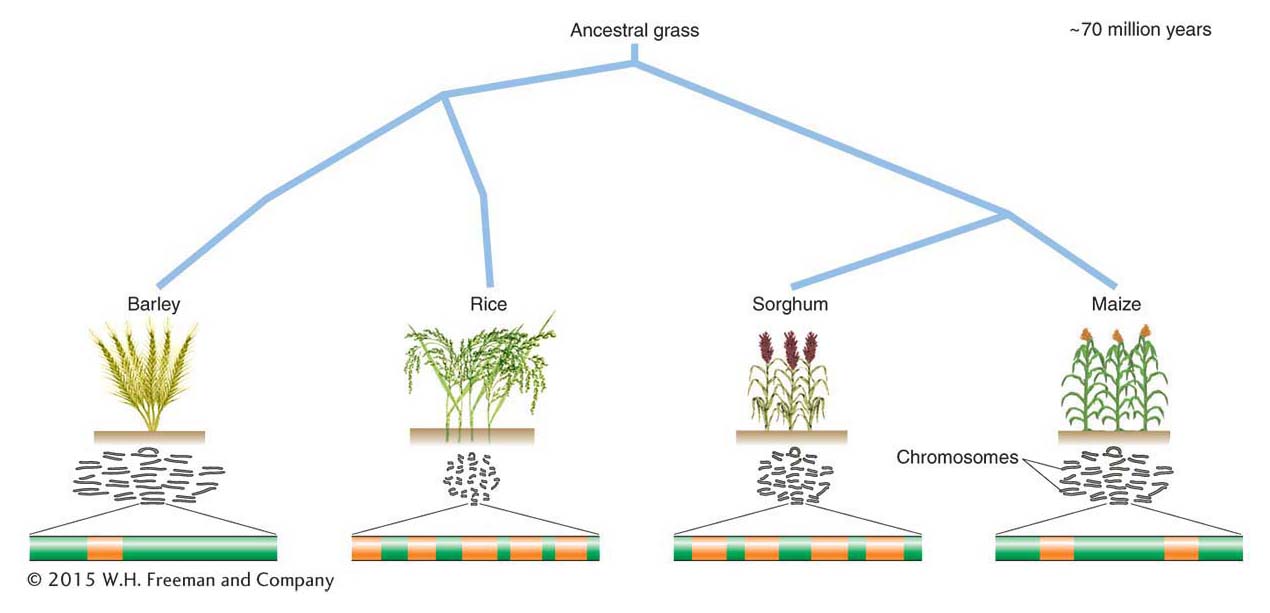
Barley and rice are both cereal grasses, and, as such, their gene content should be similar. However, if genes are a relatively constant component of the genomes of multicellular organisms, what is responsible for the additional DNA in the larger genomes? On the basis of the results of additional experiments, scientists were able to determine that DNA sequences that are repeated thousands, even hundreds of thousands, of times make up a large fraction of eukaryotic genomes and that some genomes contain much more repetitive DNA than others.
Thanks to many recent projects to sequence the genomes of a wide variety of organisms (including Drosophila, humans, the mouse, Arabidopsis, and rice), we now know that there are many classes of repetitive sequences in the genomes of higher organisms and that some are similar to the DNA transposons and retrotransposons shown to be responsible for mutations in plants, yeast, and insects. Most remarkably, these sequences make up most of the DNA in the genomes of multicellular eukaryotes.
Rather than correlating with gene content, genome size frequently correlates with the amount of DNA in the genome that is derived from transposable elements. Organisms with big genomes have lots of sequences that resemble transposable elements, whereas organisms with small genomes have many fewer. Two examples, one from the human genome and the other from a comparison of the grass genomes, illustrate this point. The structural features of the transposable elements that are found in human genomes are summarized in Figure 15-21 and will be referred to in the next section.
KEY CONCEPT
The C-value paradox is the lack of correlation between genome size and biological complexity. Genes make up only a small proportion of the genomes of multicellular organisms. Genome size usually corresponds to the amount of transposable-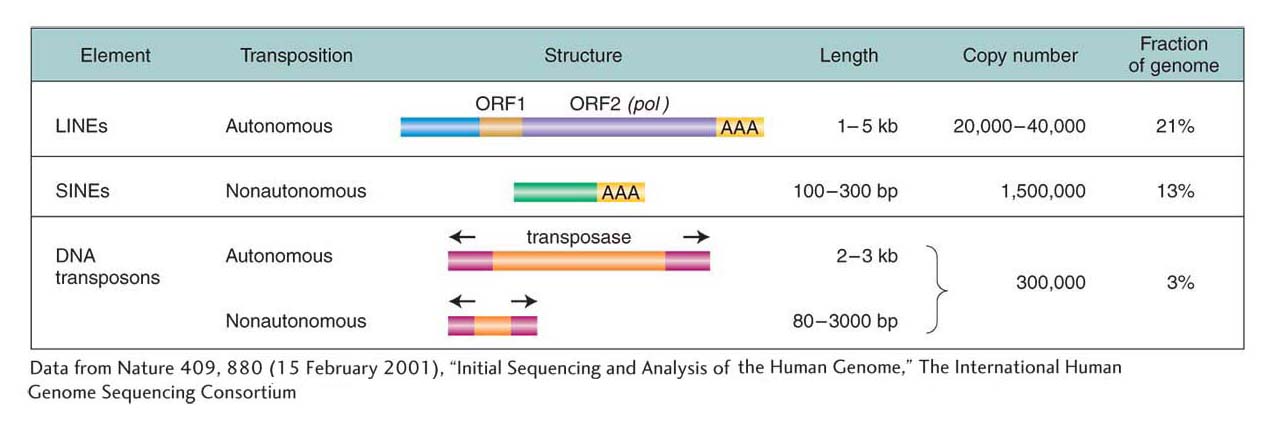
Transposable elements in the human genome
Almost half of the human genome is derived from transposable elements. The vast majority of these transposable elements are two types of retrotransposons called long interspersed elements, or LINEs, and short interspersed elements, or SINEs (see Figure 15-21). LINEs move like a retrotransposon with the help of an element-
The most abundant SINE in humans is called Alu, so named because it contains a target site for the Alu restriction enzyme. The human genome contains more than 1 million whole and partial Alu sequences, scattered between genes and within introns. These Alu sequences make up more than 10 percent of the human genome. The full Alu sequence is about 200 nucleotides long and bears remarkable resemblance to 7SL RNA, an RNA that is part of a complex by which newly synthesized polypeptides are secreted through the endoplasmic reticulum. Presumably, the Alu sequences originated as reverse transcripts of these RNA molecules.
There is about 20 times as much DNA in the human genome derived from transposable elements as there is DNA encoding all human proteins. Figure 15-22 illustrates the number and diversity of transposable elements present in the human genome, using as an example the positions of individual Alus, other SINEs, and LINEs in the vicinity of a typical human gene.
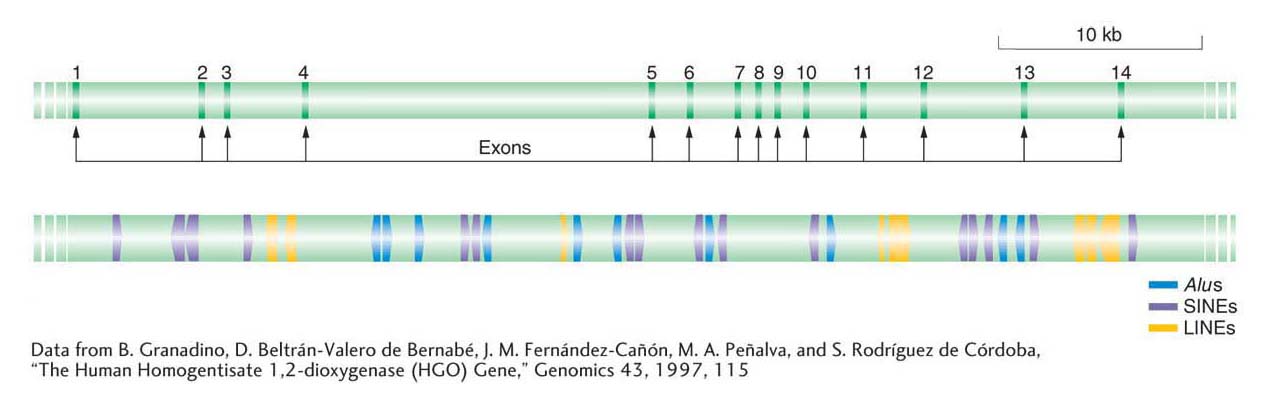
The human genome seems to be typical for a multicellular organism in the abundance and distribution of transposable elements. Thus, an obvious question is, How do plants and animals survive and thrive with so many insertions in genes and so much mobile DNA in the genome? First, with regard to gene function, all of the elements shown in Figure 15-22 are inserted into introns. Thus, the mRNA produced by this gene will not include any sequences from transposable elements because they will have been spliced out of the pre-
The overall frequency of spontaneous mutation due to the insertion of class 2 elements in humans is quite low, accounting for less than 0.2 percent (1 in 500) of all characterized spontaneous mutations. Surprisingly, retrotransposon insertions account for about 10 percent of spontaneous mutations in another mammal, the mouse. The approximately 50-
KEY CONCEPT
Transposable elements compose the largest fraction of the human genome, with LINEs and SINEs being the most abundant. The vast majority of transposable elements are ancient relics that can no longer move or increase their copy number. A few elements remain active, and their movement into genes can cause disease.The grasses: LTR-retrotransposons thrive in large genomes
As already mentioned, the C-value paradox is the lack of correlation between genome size and biological complexity. How can organisms have very similar gene content but differ dramatically in the size of their genomes? This situation has been investigated in the cereal grasses. Differences in the genome sizes of these grasses have been shown to correlate primarily with the number of one class of elements, the LTR-
Safe havens
The abundance of transposable elements in the genomes of multicellular organisms led some investigators to postulate that successful transposable elements (those that are able to attain very high copy numbers) have evolved mechanisms to prevent harm to their hosts by not inserting into host genes. Instead, successful transposable elements insert into so-
Safe havens in small genomes: targeted insertions In contrast with the genomes of multicellular eukaryotes, the genome of unicellular yeast is very compact, with closely spaced genes and very few introns. With almost 70 percent of its genome as exons, there is a high probability that new insertions of transposable elements will disrupt a coding sequence. Yet, as we have seen earlier in this chapter, the yeast genome supports a collection of LTR-
How are transposable elements able to spread to new sites in genomes with few safe havens? Investigators have identified hundreds of Ty elements in the sequenced yeast genome and have determined that they are not randomly distributed. Instead, each family of Ty elements inserts into a particular genomic region. For example, the Ty3 family inserts almost exclusively near but not in tRNA genes, at sites where they do not interfere with the production of tRNAs and, presumably, do not harm their hosts. Ty elements have evolved a mechanism that allows them to insert into particular regions of the genome: Ty proteins necessary for integration interact with specific yeast proteins bound to genomic DNA. Ty3 proteins, for example, recognize and bind to subunits of the RNA polymerase complex that have assembled at tRNA promoters (Figure 15-24a).
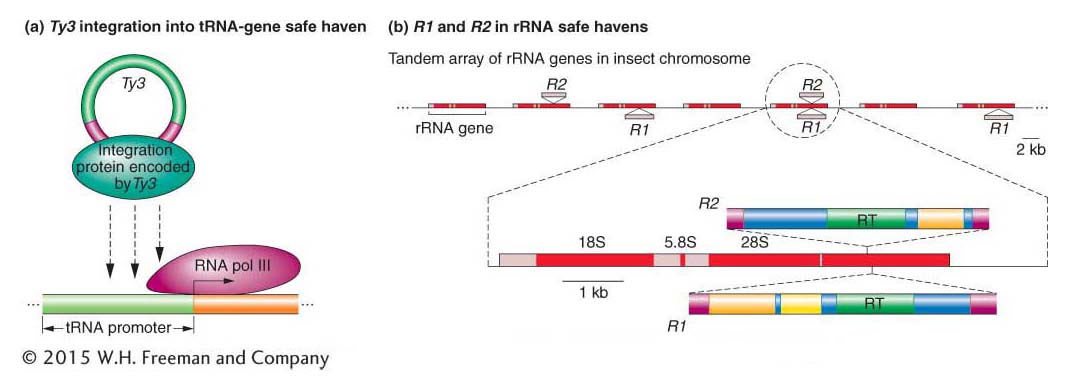
The ability of some transposons to insert preferentially into certain sequences or genomic regions is called targeting. A remarkable example of targeting is illustrated by the R1 and R2 elements of arthropods, including Drosophila. R1 and R2 are LINEs (see Figure 15-21) that insert only into the genes that produce ribosomal RNA. In arthropods, several hundred rRNA genes are organized in tandem arrays (Figure 15-
Gene therapy revisited This chapter began with a description of a recessive genetic disorder called SCID (severe combined immunodeficiency disease). The immune systems of persons afflicted with SCID are severely compromised owing to a mutation in a gene encoding the enzyme adenosine deaminase. To correct this genetic defect, bone-
Clearly, the serious risk associated with this form of gene therapy might be greatly improved if doctors were able to control where the retroviral vector integrates into the human genome. We have already seen that there are many similarities between LTR-