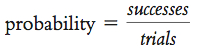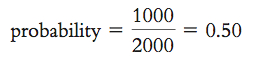Probability
You have probably heard phrases such as “the margin of error” or “plus or minus 3 percentage points,” especially during an election season. These are another way of saying, “We’re not 100% sure that we can believe our own results.” This could make you cynical about statistics—you do all this work, and then you still don’t know if you can trust your data.
You would be more justified, however, in celebrating statistics for being so truthful—statistics allows us to quantify the uncertainty. And let’s be honest—most of life is filled with uncertainty, whether it’s the lack of clouds over Nagasaki, the results you get from a given face moisturizer, or the most efficient way for a worker to perform a task. Probability is central to inferential statistics because our conclusions about a population are based on data collected from a sample rather than on anecdotes and testimonials.
Coincidence and Probability
Page 105
Confirmation bias is our usually unintentional tendency to pay attention to evidence that confirms what we already believe and to ignore evidence that would disconfirm our beliefs. Confirmation biases closely follow illusory correlations.
Illusory correlation is the phenomenon of believing one sees an association between variables when no such association exists.

Paul the Octopus Amazingly, Paul the German Octopus accurately predicted the outcome of all of Germany’s 2010 World Cup matches (Shenker, 2010). By the championship game, he was famous, with a BBC News headline announcing: “German ‘psychic’ octopus predicts victory for Spain.” Before each match, Paul was presented with two boxes of food, each marked by a national flag. His picks were the boxes from which he chose food first. Paul was famous because he did so well with his picks; he wouldn’t have been in the news otherwise! But once he was famous, people focused only on his successes, not his failures. Indeed, he only correctly picked four of Germany’s six matches in the earlier Euro 2008 tournament—just one more correct pick than chance would predict. Moreover, it’s not at all surprising that there will occasionally be an animal with a lucky streak like this. As University of Cambridge statistics professor David Spiegelharter pointed out to the BBC News, Paul’s feat is not that remarkable if you consider all of the animals who have tried and failed to predict sports wins over the years.
AFP/Getty Images
Probability and statistical reasoning can save us from ourselves when, for example, we are confronted with eerie coincidences. Two personal biases get intertwined in our thinking so that we say with genuine astonishment, “Wow! What are the chances of that?” Confirmation bias is our usually unintentional tendency to pay attention to evidence that confirms what we already believe and to ignore evidence that would disconfirm our beliefs. It is a confirmation bias when an athlete attributes her team’s wins to her lucky earrings, ignoring any losses while wearing them or any wins while wearing other earrings. Confirmation biases closely follow illusory correlations. Illusory correlation is the phenomenon of believing one sees an association between variables when no such association exists. An athlete with a confirmation bias attributing wins to her lucky earrings now believes an illusory correlation. We invite illusory correlations into our lives whenever we ignore the gentle, restraining logic of statistical reasoning.
For example, the science show Radiolab told a remarkable story of coincidence (Abumrad & Krulwich, 2009). A 10-year-old girl named Laura Buxton released a red balloon from her hometown in the north of England. “Almost 10,” Laura corrected the host. Laura had written her address on the balloon as well as an entreaty: “Please return to Laura Buxton.” The balloon traveled 140 miles to the south of England and was found by a neighbor of another 10-year-old girl, also named Laura Buxton! The second Laura wrote to the first, and they arranged to meet. They both showed up to their meeting wearing jeans and pink sweaters. They were both the same height, had brown hair; and owned a black Labrador retriever, a gray rabbit, and a brown guinea pig with an orange spot. In fact, each brought her guinea pig to the meeting. At the time of the radio broadcast, they were 18 years old and friends. “Maybe we were meant to meet,” one of the Laura Buxtons speculated. “If it was just the wind, it was a very, very lucky wind,” said the other.
Page 106
MASTERING THE CONCEPT
5-3: Human biases result from two closely related concepts. When we notice only evidence that confirms what we already believe and ignore evidence that refutes what we already believe, we’re succumbing to the confirmation bias. Confirmation biases often follow illusory correlations—when we believe we see an association between two variables, but no association exists.
The chances seem unbelievably slim, but confirmation bias and illusory correlations both play a role here—and probability helps us understand why such coincidences happen. The thing is, coincidences are not unlikely. We notice and remember strange coincidences, but do not notice the uncountable times in which there are not unlikely occurrences—the background, so to speak. We remember unusual stories of coincidences and luck, like that of the great-grandmother who won the lottery by playing the numbers in the fortune cookie that came with her Chinese take-out (Rosario & Sutherland, 2014). But we forget the many times we bought lottery tickets and lost—and the millions of people who did the same.
The Radiolab story described this phenomenon as the “blade of grass paradox.” Imagine a golfer hitting a ball that flies way down the fairway and lands on a blade of grass. The radio show imagines the blade of grass saying: “Wow. What are the odds that that ball, out of all the billions of blades of grass … just landed on me?” Yet we know that there’s almost a 100% chance that some blade of grass was going to be crushed by that ball. It just seems miraculous to the individual blade of grass—or to the lottery winner.
Let’s go back to our story about the Laura Buxtons. A statistician pointed out that the details were “manipulated” to make for a better story. The host had remembered that they were both 10 years old, yet the first Laura reminded him she was still 9 at the time (“almost 10”). The host also admitted there were many discrepancies—one’s favorite color was pink and one’s was blue, and they had opposite academic interests—biology, chemistry, and geography for one and English, history, and classical civilization for the other. Further, it was not the second Laura Buxton who found the balloon; rather, it was her neighbor. The similarities make a better story. When you add in confirmation bias and illusory correlation, these become the WOW! details that we remember—but it’s still just another blade of grass. Still not convinced? Read on.
Expected Relative-Frequency Probability
Personal probability is a person’s own judgment about the likelihood that an event will occur; also called subjective probability.
MASTERING THE CONCEPT
5-4: In everyday life, we use the word probability very loosely—saying how likely a given outcome is, in our subjective judgment. Statisticians are referring to something very particular when they refer to probability. For statisticians, probability is the actual likelihood of a given outcome in the long run.
When we discuss probability in everyday conversation, we tend to think of what statisticians call personal probability: a person’s own judgment about the likelihood that an event will occur; also called subjective probability. We might say something like “There’s a 75% chance I’ll finish my paper and go out tonight.” We don’t mean that the chance we’ll go out is precisely 75%. Rather, this is our rating of our confidence that this event will occur. It’s really just our best guess.
Probability is the likelihood that a particular outcome—out of all possible outcomes—will occur.
Mathematicians and statisticians, however, use the word probability a bit differently. Statisticians are concerned with a different type of probability, one that is more objective. In a general sense, probability is the likelihood that a particular outcome—out of all possible outcomes—will occur. For example, we might talk about the likelihood of getting heads (a particular outcome) if we flip a coin 10 times (all possible outcomes). We use probability because we usually have access only to a sample (10 flips of a coin) when we want to know about an entire population (all possible flips of a coin).
The expected relative-frequency probability is the likelihood of an event occurring based on the actual outcome of many, many trials.

Determining Probabilities To determine the probability of heads, we would have to conduct many trials (coin flips), record the outcomes (either heads or tails), and determine the proportion of successes (in this case, heads).
© Eyebyte/Alamy
Language Alert! In statistics, we are interested in an even more specific definition of probability—expected relative-frequency probability, the likelihood of an event occurring, based on the actual outcome of many, many trials. When flipping a coin, the expected relative-frequency probability of heads, in the long run, is 0.50. Probability refers to the likelihood that something would take place, and frequency refers to how often a given outcome (e.g., heads or tails) occurs out of a certain number of trials (e.g., coin flips). Relative indicates that this number is relative to the overall number of trials, and expected indicates that it’s what we would anticipate, which might be different from what actually happens.
Page 107
In reference to probability, a trial refers to each occasion that a given procedure is carried out.
In reference to probability, outcome refers to the result of a trial.
In reference to probability, success refers to the outcome for which we’re trying to determine the probability.
In reference to probability, the term trial refers to each occasion that a given procedure is carried out. For example, each time we flip a coin, it is a trial. Outcome refers to the result of a trial. For coin-flip trials, the outcome is either heads or tails. Success refers to the outcome for which we’re trying to determine the probability. If we are testing for the probability of heads, then success is heads.
EXAMPLE 5.1
We can think of probability in terms of a formula. We calculate probability by dividing the total number of successes by the total number of trials. So the formula would look like this:
If we flip a coin 2000 times and get 1000 heads, then:
Here is a recap of the steps to calculate probability:
STEP 1: Determine the total number of trials.
STEP 2: Determine the number of these trials that are considered successful outcomes.
STEP 3: Divide the number of successful outcomes by the number of trials.
People often confuse the terms probability, proportion, and percentage. Probability, the concept of most interest to us right now, is the proportion that we expect to see in the long run. Proportion is the number of successes divided by the number of trials. In the short run, in just a few trials, the proportion might not reflect the underlying probability. A coin flipped six times might come up heads more or fewer than three times, leading to a proportion of heads that does not parallel the underlying probability of heads. Both proportions and probabilities are written as decimals.
Percentage is simply probability or proportion multiplied by 100. A flipped coin has a 0.50 probability of coming up heads and a 50% chance of coming up heads. You are probably already familiar with percentages, so simply keep in mind that probabilities are what we would expect in the long run, whereas proportions are what we observe.
Page 108
One of the central characteristics of expected relative-frequency probability is that it only works in the long run. This is an important aspect of probability, and it is referred to as the law of large numbers. Think of the earlier discussion of random assignment in which we used a random numbers generator to create a series of 0’s and 1’s to assign participants to levels of the independent variable. In the short run, over just a few trials, we can get strings of 0’s and 1’s and often do not end up with half 0’s and half 1’s, even though that is the underlying probability. With many trials, however, we’re much more likely to get close to 0.50, or 50%, of each, although many strings of 0’s or 1’s would be generated along the way. In the long run, the results are quite predictable.
Independence and Probability
Language Alert! To avoid bias, statistical probability requires that the individual trials be independent, one of the favorite words of statisticians. Here we use independent to mean that the outcome of each trial must not depend in any way on the outcome of previous trials. If we’re flipping a coin, then each coin flip is independent of every other coin flip. If we’re generating a random numbers list to select participants, each number must be generated without thought to the previous numbers. In fact, this is exactly why humans can’t think randomly. We automatically glance at the previous numbers we have generated in order to best make the next one “random.” Chance has no memory, and randomness is, therefore, the only way to assure that there is no bias.

Gambling and Misperceptions of Probability Many people falsely believe that a slot machine that has not paid off in a long time is “due.” A person may continue to feed coins into it, expecting an imminent payout. Of course, the slot machine itself, unless rigged, has no memory of its previous outcomes. Each trial is independent of the others.
© Photofusion Picture Library/Alamy
CHECK YOUR LEARNING
| Reviewing the Concepts |
|
Probability theory helps us understand that coincidences might not have an underlying meaning; coincidences are probable when we think of the vast number of occurrences in the world (billions of interactions between people daily). An illusory correlation refers to perceiving a connection where none exists. It is often followed by a confirmation bias, whereby we notice occurrences that fit with our preconceived ideas and fail to notice those that do not. Personal probability refers to a person’s own judgment about the likelihood that an event will occur (also called subjective probability). Expected relative-frequency probability is the likelihood of an event occurring, based on the actual outcome of many, many trials. The probability of an event occurring is defined as the expected number of successes (the number of times the event occurred) out of the total number of trials (or attempts) over the long run. Proportions over the short run might have many different outcomes, whereas proportions over the long run are more indicative of the underlying probabilities.
|
| Clarifying the Concepts |
5-5 |
Distinguish the personal probability assessments we perform on a daily basis from the objective probability that statisticians use. |
| Calculating the Statistics |
5-6 |
Calculate the probability for each of the following instances.
-
-
1044 trials, 130 successes
|
| Applying the Concepts |
5-7 |
Consider a scenario in which a student wonders whether men or women are more likely to use the banking machine (ATM) in the student center. He decides to observe those who use the banking machine. (Assume that there is an equal number of men and women who use the banking machine.)
Define success as a woman using the banking machine on a given trial. What proportion of successes might this student expect to observe in the short run? What might this student expect to observe in the long run?
|
Solutions to these Check Your Learning questions can be found in Appendix D.
Page 109