10.1 The Paired-Samples t Test
As we learned in the chapter opening, researchers found that weight gain over the holidays is far less than what folk wisdom had suggested. Guess what? The dreaded “freshman 15” also appears to be a myth. One study found that male university students gained an average of 3.5 pounds between the beginning of the fall semester and November, and female students gained an average of 4.0 pounds (Holm-
The paired-
The paired-
The steps for the paired-
245

Distributions of Mean Differences
We already learned about a distribution of scores and a distribution of means. Now we need to develop a distribution of mean differences for the pre-
Imagine that many college students’ weights were measured before and after the winter holidays and written on individual cards. We begin by gathering data from a sample of three people from among this population of many college students. There are two cards for each person in the population, on which weights are listed—
- Step 1. Randomly choose three pairs of cards, replacing each pair of cards before randomly selecting the next.
- Step 2. For each pair, calculate a difference score by subtracting the first weight from the second weight.
- Step 3. Calculate the mean of the differences in weights for these three people. Then complete these three steps again. Randomly choose another three people from the population of many college students, calculate their difference scores, and calculate the mean of the three difference scores. And then complete these three steps again, and again, and again.
Let’s walk through these steps once again, using an example.
246
- Step 1. We randomly select one pair of cards and find that the first student weighed 140 pounds before the holidays and 144 pounds after the holidays. We replace those cards and randomly select another pair; the second student had before and after scores of 126 and 124, respectively. We replace those cards and randomly select another pair; the third student had before and after scores of 168 and 168, respectively.
- Step 2. For the first student, the difference between weights, subtracting the before score from the after score, is 144 − 140 = 4. For the second student, the difference between weights is 124 − 126 = −2. For the third student, the difference between weights is 168 − 168 = 0.
- Step 3. The mean of these three difference scores (4, −2, 0) is 0.667.
We would then choose three more students and calculate the mean of their difference scores. Eventually, we would have many mean differences to plot on a curve of mean differences—
But this would only be the beginning of what this distribution of mean differences would look like. If we were to calculate the whole distribution of mean differences, then we would do this an uncountable number of times. When the authors of this book calculated 30 mean differences for pairs of weights, we got the distribution in Figure 10-1. If no mean difference is found when comparing weights from before and after the holidays, as with the data we used to create Figure 10-1, the distribution would center around 0. According to the null hypothesis, we would expect no mean difference in weight—
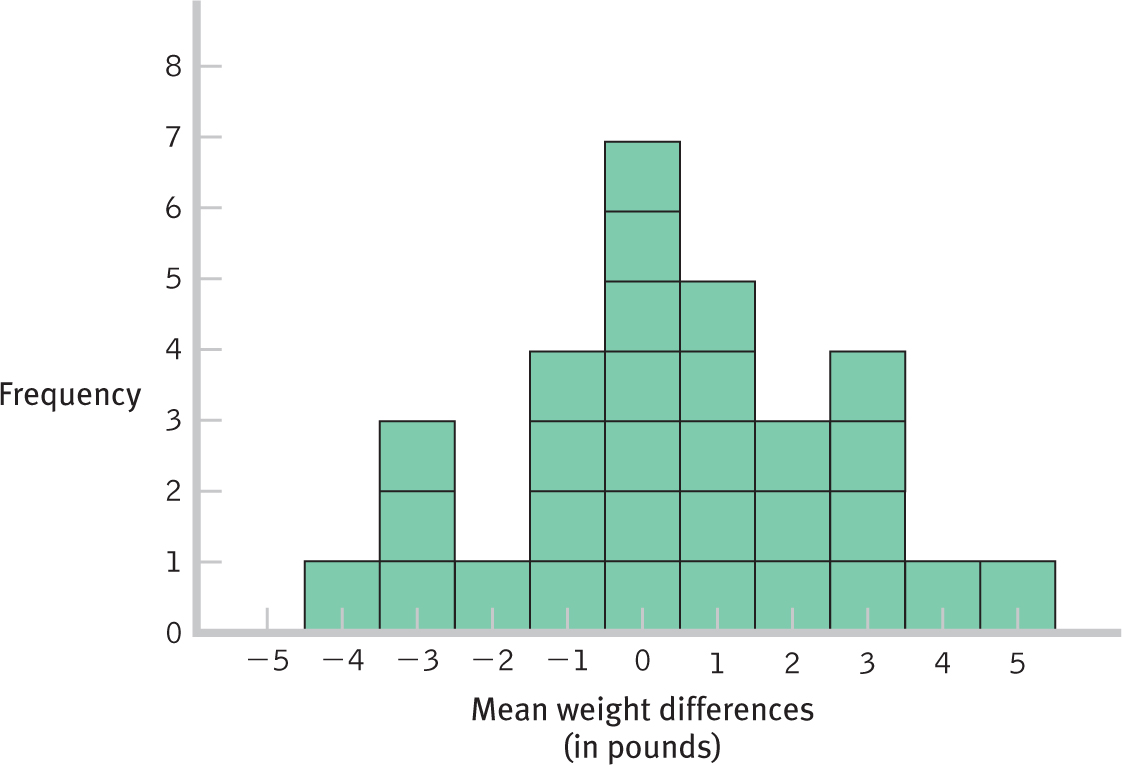
Figure 10-
The Six Steps of the Paired-Samples t Test
In a paired-
247

EXAMPLE 10.1
Let’s use an example from the software industry (which employs social scientists to improve the ways in which people interact with their products). For example, behavioral scientists at Microsoft studied how 15 volunteers performed on a set of tasks under two conditions—
Here are five participants’ fictional data, which reflect the actual means reported by researchers. Note that a smaller number is good—
STEP 1: Identify the populations, distribution, and assumptions.
The paired-
MASTERING THE CONCEPT
10.2: The steps for the paired-
Summary: Population 1: People performing tasks using a 15-
The comparison distribution is a distribution of mean difference scores based on the null hypothesis. The hypothesis test is a paired-
This study meets one of the three assumptions and may meet the other two: (1) The dependent variable is time, which is scale. (2) The participants were not randomly selected, however, so we must be cautious with respect to generalizing our findings. (3) We do not know whether the population is normally distributed, and there are not at least 30 participants. However, the data from this sample do not suggest a skewed distribution.
248
STEP 2: State the null and research hypotheses.
This step is identical to that for the single-
Summary: Null hypothesis: People who use a 15-
STEP 3: Determine the characteristics of the comparison distribution.
This step is similar to that for the single-
For the paired-
Summary: μM = 0; sM = 1.924
Calculations: (Notice that we crossed out the original scores once we created the column of difference scores. We did this to remind ourselves that all remaining calculations involve the differences scores, not the original scores.)
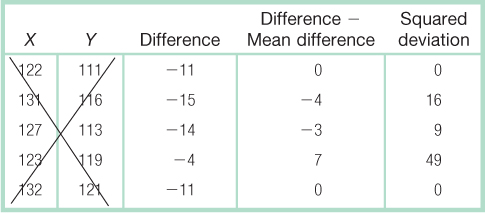
The mean of the difference scores is:
Mdifference = −11
The numerator is the sum of square, SS (that we learned about in Chapter 4):
SS = 0 + 16 + 9 + 49 + 0 = 74
The standard deviation, s, is:
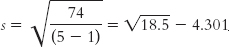
249
The standard error, sM, is:
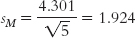
STEP 4: Determine the critical values, or cutoffs.
This step is the same as that for the single-
Summary: df = N − 1 = 5 − 1 = 4
The critical values, based on a two-
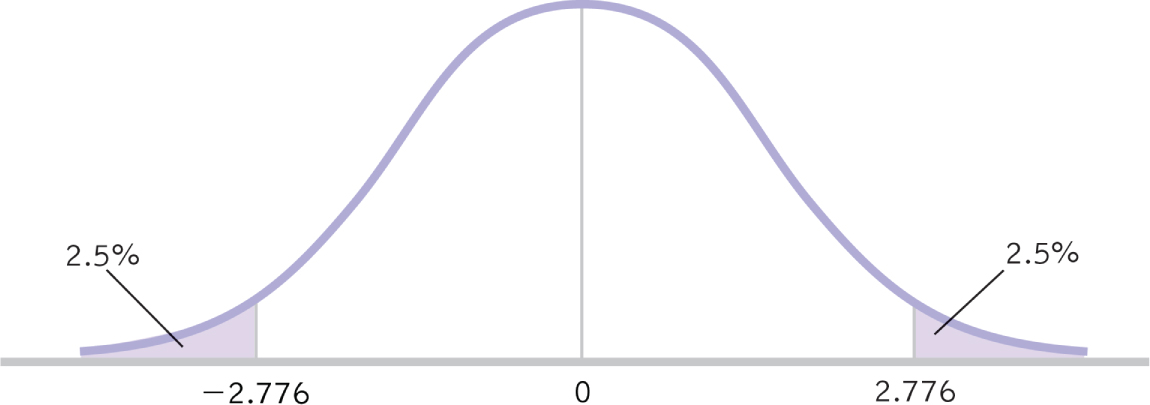
Figure 10-
STEP 5: Calculate the test statistic.
This step is identical to that for the single-
Summary: 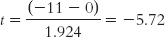
STEP 6: Make a decision.
This step is identical to that for the single-
Summary: Reject the null hypothesis. When we examine the means (MX = 127; MY = 116), it appears that, on average, people perform faster when using a 42-
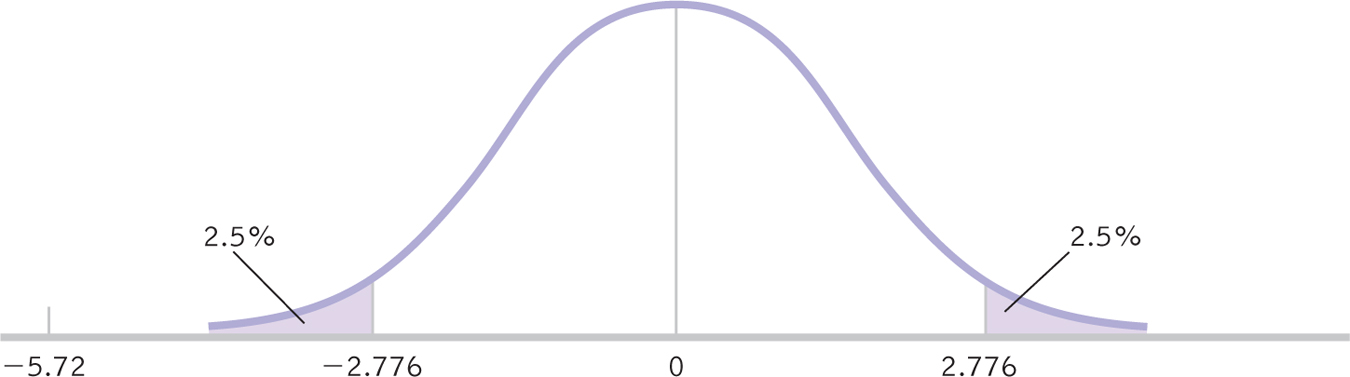
Figure 10-
The statistics, as reported in a journal article, follow the same APA format as for a single-
t(4) = −5.72, p < 0.05
250
We also include the means and the standard deviations for the two samples. We calculated the means in step 6 of hypothesis testing, but we would also have to calculate the standard deviations for the two samples to report them.
The researchers note that the faster time with the large display might not seem much faster but that, in their research, they have had great difficulty identifying any factors that lead to faster times (Czerwinski et al., 2003). Based on their previous research, therefore, this is an impressive difference.
CHECK YOUR LEARNING
Reviewing the Concepts
- The paired-
samples t test is used when we have data for all participants under two conditions— a within- groups design. - In the paired-
samples t test, we calculate a difference score for every individual in the study. The statistic is calculated on those difference scores. - We use the same six steps of hypothesis testing that we used with the z test and with the single-
sample t test.
Clarifying the Concepts
- 10-
1 How do we conduct a paired-samples t test? - 10-
2 Explain what an individual difference score is, as it is used in a paired-samples t test.
Calculating the Statistics
- 10-
3 Below are energy-level data (on a scale of 1 to 7, where 1 = feeling of no energy and 7 = feeling of high energy) for five students before and after lunch. Calculate the mean difference for these people so that loss of energy is a negative value. Assume you are testing the hypothesis that students go into what we call “food comas” after eating, versus lunch giving them added energy.
| Before lunch | After lunch |
|---|---|
| 6 | 3 |
| 5 | 2 |
| 4 | 6 |
| 5 | 4 |
| 7 | 5 |
Applying the Concepts
- 10-
4 Using the energy-level data presented in Check Your Learning 10- 3, test the hypothesis that students have different energy levels before and after lunch. Perform the six steps of hypothesis testing for a two- tailed paired- samples t test.
Solutions to these Check Your Learning questions can be found in Appendix D.