8.2 Effect Size
As we learned when we looked at the research on gender differences in mathematical reasoning ability, “statistically significant” does not mean that the findings from a study represent a meaningful difference. “Statistically significant” only means that those findings are unlikely to occur if in fact the null hypothesis is true. Calculating an effect size moves us a little closer to what we are most interested in: Is the pattern in a data set meaningful or important?
The Effect of Sample Size on Statistical Significance

The almost completely overlapping curves in Figure 8-1 were “statistically significant” because the sample size was so big. Increasing sample size always increases the test statistic if all else stays the same. For example, psychology test scores on the Graduate Record Examination (GRE) had a mean of 603 and a standard deviation of 101 during the years 2005-
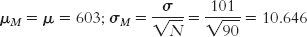
The test statistic calculated from these numbers was:
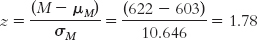
What would happen if we increased the sample size to 200? We’d have to recalculate the standard error to reflect the larger sample, and then recalculate the test statistic to reflect the smaller standard error.
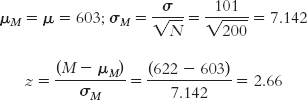
What if we increased the sample size to 1000?
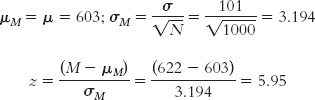
What if we increased it to 100,000?
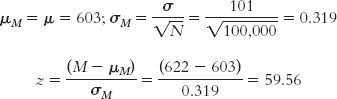
199

MASTERING THE CONCEPT
8.2: As sample size increases, so does the test statistic (if all else stays the same). Because of this, a small difference might not be statistically significant with a small sample but might be statistically significant with a large sample.
Notice that each time we increased the sample size, the standard error decreased and the test statistic increased. The original test statistic, 1.78, was not beyond the critical values of 1.96 and −1.96. However, the remaining test statistics (2.66, 5.95, and 59.56) were increasingly more extreme than the positive critical value. In their study of gender differences in mathematics performance, researchers studied 10,000 participants, a very large sample (Benbow & Stanley, 1980). It is not surprising, then, that a small difference would be a statistically significant difference.
Let’s consider, logically, why it makes sense that a large sample should allow us to reject the null hypothesis more readily than a small sample. If we randomly selected 5 people among all those who had taken the GRE and they had scores well above the national average, we might say, “It could be chance.” But if we randomly selected 1000 people with GRE scores well above the national average, it is very unlikely that we just happened to choose 1000 people with high scores.
But just because a real difference exists does not mean it is a large, or meaningful, difference. The difference we found with 5 people might be the same as the difference we found with 1000 people. As we demonstrated with multiple z tests with different sample sizes, we might fail to reject the null hypothesis with a small sample but then reject the null hypothesis for the same-
Cohen (1990) used the small but statistically significant correlation between height and IQ to explain the difference between statistical significance and practical importance. The sample size was big: 14,000 children. Imagining that height and IQ were causally related, Cohen calculated that a person would have to grow by 3.5 feet to increase her IQ by 30 points (two standard deviations). Or, to increase her height by 4 inches, a person would have to increase IQ by 233 points! Height may have been statistically significantly related to IQ, but there was no practical real-
Language Alert! When you come across the term statistical significance, do not interpret this as an indication of practical importance.
What Effect Size Is
Effect size indicates the size of a difference and is unaffected by sample size.
Effect size can tell us whether a statistically significant difference might also be an important difference. Effect size indicates the size of a difference and is unaffected by sample size. Effect size tells us how much two populations do not overlap. Simply put, the less overlap, the bigger the effect size.
The amount of overlap between two distributions can be decreased in two ways. First, as shown in Figure 8-6, overlap decreases and effect size increases when means are further apart. Second, as shown in Figure 8-7, overlap decreases and effect size increases when variability within each distribution of scores is smaller.
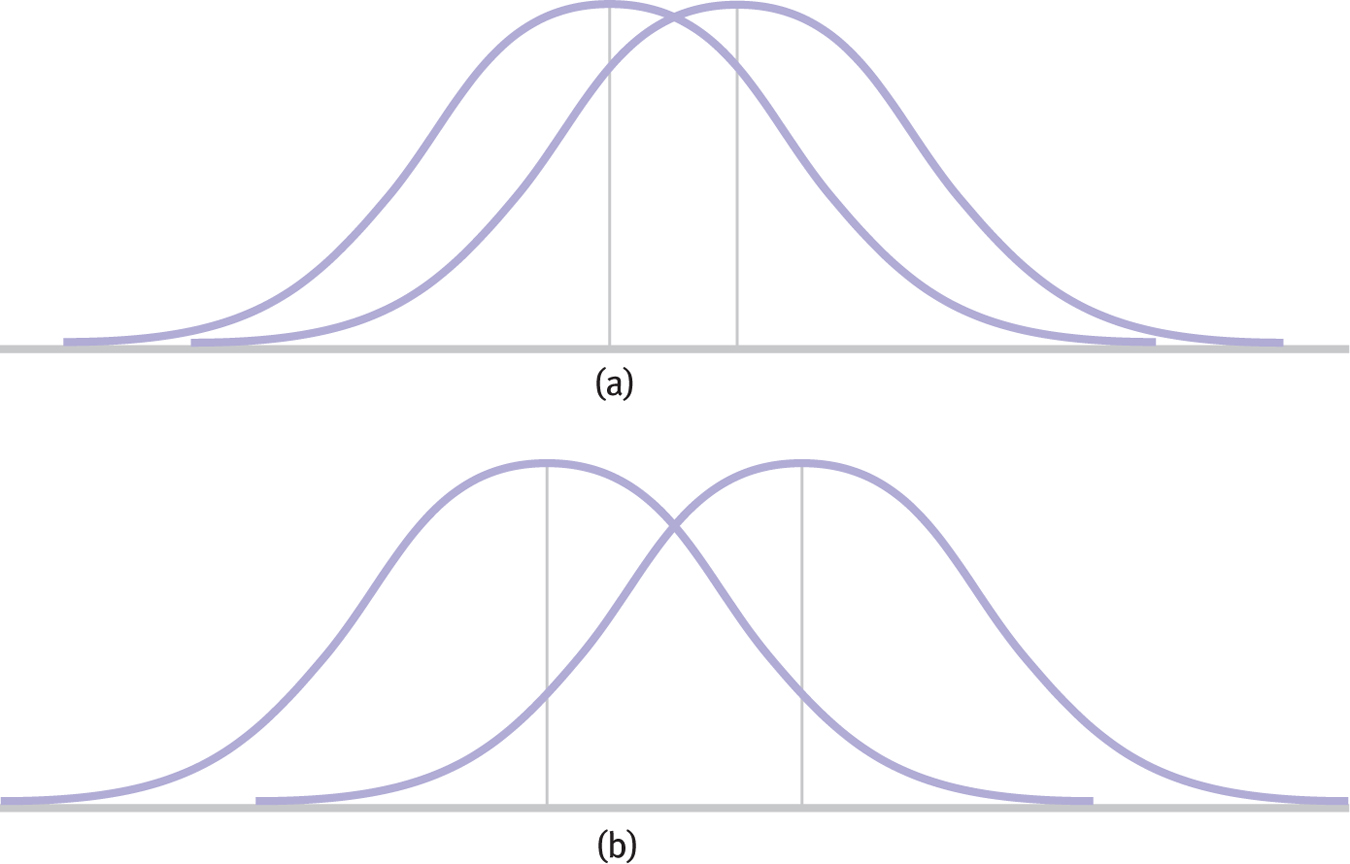
Figure 8-
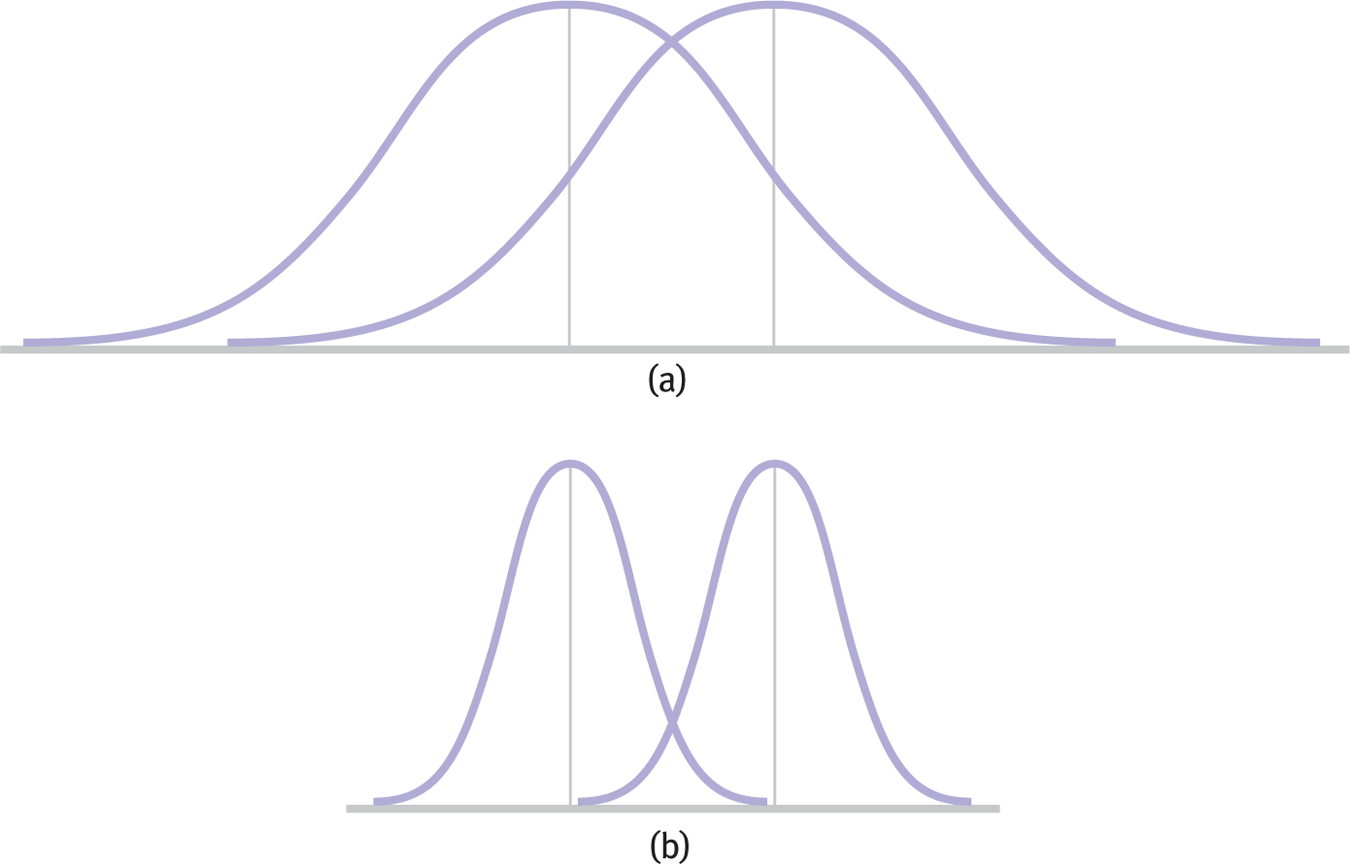
Figure 8-
When we discussed gender differences in mathematical reasoning ability, you may have noticed that we described the size of the findings as “small” (Hyde, 2005). Because effect size is a standardized measure based on scores rather than means, we can compare the effect sizes of different studies with one another, even when the studies have different sample sizes.
200
EXAMPLE 8.3
Figure 8-8 demonstrates why we use scores instead of means to calculate effect size. First, assume that each of these distributions is based on the same underlying population. Second, notice that all means represented by the vertical lines are identical. The differences are due only to the spread of the distributions. The small degree of overlap in the tall, skinny distributions of means in Figure 8-8a is the result of a large sample size. The greater degree of overlap in the somewhat wider distributions of means in Figure 8-8b is the result of a smaller sample size. By contrast, the distributions of scores in Figures 8-
201
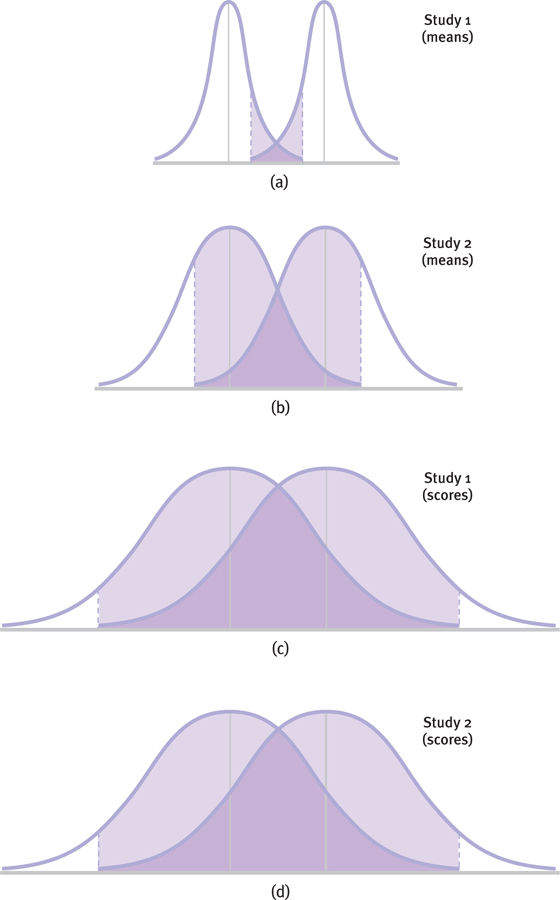
Figure 8-
In this case, the amounts of real overlap in Figures 8-
Cohen’s d
Cohen’s d is a measure of effect size that assesses the difference between two means in terms of standard deviation, not standard error.
There are many different effect-
202
EXAMPLE 8.4
Let’s calculate Cohen’s d for the situation for which we constructed a confidence interval. We simply substitute standard deviation for standard error. When we calculated the test statistic for the 1000 customers at Starbucks with posted calories, we first calculated standard error:
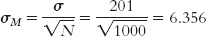
We calculated the z statistic using the population mean of 247 and the sample mean of 232:
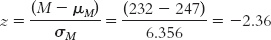
To calculate Cohen’s d, we simply use the formula for the z statistic, substituting σ for σM (and μ for μM, even though these means are always the same). So we use 201 instead of 6.356 in the denominator. The Cohen’s d is now based on the spread of the distribution of scores, rather than the distribution of means.
MASTERING THE FORMULA
8-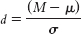 . It is the same formula as for the z statistic, except we divide by the population standard deviation rather than by standard error.
. It is the same formula as for the z statistic, except we divide by the population standard deviation rather than by standard error.
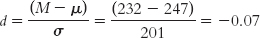
Now that we have the effect size, often written in shorthand as d = −0.07, what does it mean? First, we know that the two sample means are 0.07 standard deviation apart, which doesn’t sound like a big difference—
| Effect Size | Convention | Overlap |
|---|---|---|
| Small | 0.2 | 85% |
| Medium | 0.5 | 67% |
| Large | 0.8 | 53% |
203
Based on these numbers, the effect size for the study of Starbucks customers (−0.07) is not even at the level of a small effect. As we pointed out in Chapter 7, however, the researchers hypothesized that even a small effect might spur eateries to provide more low-
MASTERING THE CONCEPT
8.3: Because a statistically significant effect might not be an important one, we should calculate effect size in addition to conducting a hypothesis test. We can then report whether a statistically significant effect is small, medium, or large.
Next Steps
Meta-
A meta-
Many researchers consider meta-
The logic of the meta-
STEP 1: Select the topic of interest, and decide exactly how to proceed before beginning to track down studies.
Here are some of the considerations to keep in mind:
- Make sure the necessary statistical information, either effect sizes or the summary statistics necessary to calculate effect sizes, is available.
- Consider selecting only studies in which participants meet certain criteria, such as age, gender, or geographic location.
- Consider eliminating studies based on the research design—
for example, because they were not experimental in nature.
For example, British researcher Fidelma Hanrahan and her colleagues conducted a meta-
STEP 2: Locate every study that has been conducted and meets the criteria.
Obvious places to start are PsycINFO, Google Scholar, and other electronic databases. For example, these researchers searched several databases using terms such as “generalized anxiety disorder,” “cognitive,” “therapy,” and “anxiety” (Hanrahan et al., 2013). A key part of meta-
204
STEP 3: Calculate an effect size, often Cohen’s d, for every study.
When the effect size has not been reported, the researcher must calculate it from summary statistics that were reported. These researchers were able to calculate 19 effect sizes from the 15 studies that met their criteria (some studies reported more than one effect) (Hanrahan et al., 2013).
STEP 4: Calculate statistics—
Most importantly, researchers calculate a mean effect size for all studies. In fact, we can apply all of the statistical insights we’ve learned: means, medians, standard deviations, confidence intervals and hypothesis testing, and visual displays such as box plots or stem-
In their meta-
Much of the fugitive literature of unpublished studies exists because studies with null results are less likely to appear in press (e.g., Begg, 1994). Twenty percent of the studies included in the meta-
205
A file drawer analysis is a statistical calculation, following a meta-
The first solution involves additional analyses. The most common follow-
There are other variants of the file drawer analysis, including analyses that allow researchers to examine their findings as if there were publication bias—
A second solution is particularly exciting because it creates new opportunities for undergraduates. Psi Chi, the International Honor Society in Psychology, has partnered with the Open Science Collaboration to test the reproducibility of well-
CHECK YOUR LEARNING
Reviewing the Concepts
- As sample size increases, the test statistic becomes more extreme and it becomes easier to reject the null hypothesis.
- A statistically significant result is not necessarily one with practical importance.
- Effect sizes are calculated with respect to scores, rather than means, so they are not contingent on sample size.
- The size of an effect is based on the difference between two group means and the amount of variability within each group.
- Effect size for a z test is measured with Cohen’s d, which is calculated much like a z statistic, but using standard deviation instead of standard error.
- A meta-
analysis is a study of studies that provides a more objective measure of an effect size than an individual study does. - A researcher conducting a meta-
analysis chooses a topic, decides on guidelines for a study’s inclusion, tracks down every study on a given topic, and calculates an effect size for each. A mean effect size is calculated and reported, often along with a standard deviation, median, significance testing, confidence interval, and appropriate graphs.
206
Clarifying the Concepts
- 8-
4 Distinguish statistical significance and practical importance. - 8-
5 What is effect size?
Calculating the Statistics
- 8-
6 Using IQ as a variable, where we know the mean is 100 and the standard deviation is 15, calculate Cohen’s d for an observed mean of 105.
Applying the Concepts
- 8-
7 In Check Your Learning 8-3, we calculated a confidence interval based on CFC data. The population mean CFC score was 3.20, with a standard deviation of 0.70. The mean for the sample of 45 students who joined a career discussion group is 3.45. - Calculate the appropriate effect size for this study.
- Citing Cohen’s conventions, explain what this effect size tells us.
- Based on the effect size, does this finding have any consequences or implications for anyone’s life?
Solutions to these Check Your Learning questions can be found in Appendix D.