18.1 Mutations Are Inherited Alterations in the DNA Sequence
DNA is a highly stable molecule that is replicated with amazing accuracy (see Chapters 10 and 12), but changes in DNA structure and errors of replication do take place. A mutation is defined as an inherited change in genetic information; the descendants may be cells or organisms.
The Importance of Mutations
Mutations are both the sustainer of life and the cause of great suffering. On the one hand, mutation is the source of all genetic variation, the raw material of evolution. The ability of organisms to adapt to environmental change depends on the presence of genetic variation in natural populations, and genetic variation is produced by mutation. On the other hand, many mutations have detrimental effects and mutation is the source of many diseases and disorders.
Much of the study of genetics focuses on how variants produced by mutation are inherited; genetic crosses are meaningless if all individual members of a species are identically homozygous for the same alleles. Much of Gregor Mendel’s success in unraveling the principles of inheritance can be traced to his use of carefully selected variants of the garden pea. Similarly, Thomas Hunt Morgan and his students discovered many basic principles of genetics by analyzing mutant fruit flies.
Mutations are also useful for examining fundamental biological processes. Finding or creating mutations that affect different components of a biological system and studying their effects can often lead to an understanding of the system. This method, referred to as genetic dissection, is analogous to figuring out how an automobile works by breaking different parts of a car and observing the effects; for example, smash the radiator and the engine overheats, revealing that the radiator cools the engine. The use of mutations to disrupt function can likewise be a source of insight into biological processes. For example, geneticists have begun to unravel the molecular details of development by studying mutations, such as tinman, that interrupt various embryonic stages in Drosophila (see Chapter 22). Scientists also used analysis of mutations to reveal the different parts of the lac operon (discussed in Chapter 16) and how they function in gene regulation. Although breaking “parts” to determine their function might seem like a crude approach to understanding a system, it is actually very powerful and has been used extensively in biochemistry, developmental biology, physiology, and behavioral science. But this method is not recommended for learning how your car works!
CONCEPTS
Mutations are heritable changes in DNA. They are essential to the study of genetics and are useful in many other biological fields.
Categories of Mutations
In multicellular organisms, we can distinguish between two broad categories of mutations: somatic mutations and germline mutations. Somatic mutations arise in somatic tissues, which do not produce gametes (Figure 18.1). When a somatic cell with a mutation divides (mitosis), the mutation is passed on to the daughter cells, leading to a population of genetically identical cells (a clone). The earlier in development that a somatic mutation takes place, the larger the clone of cells will be that contain the mutation.
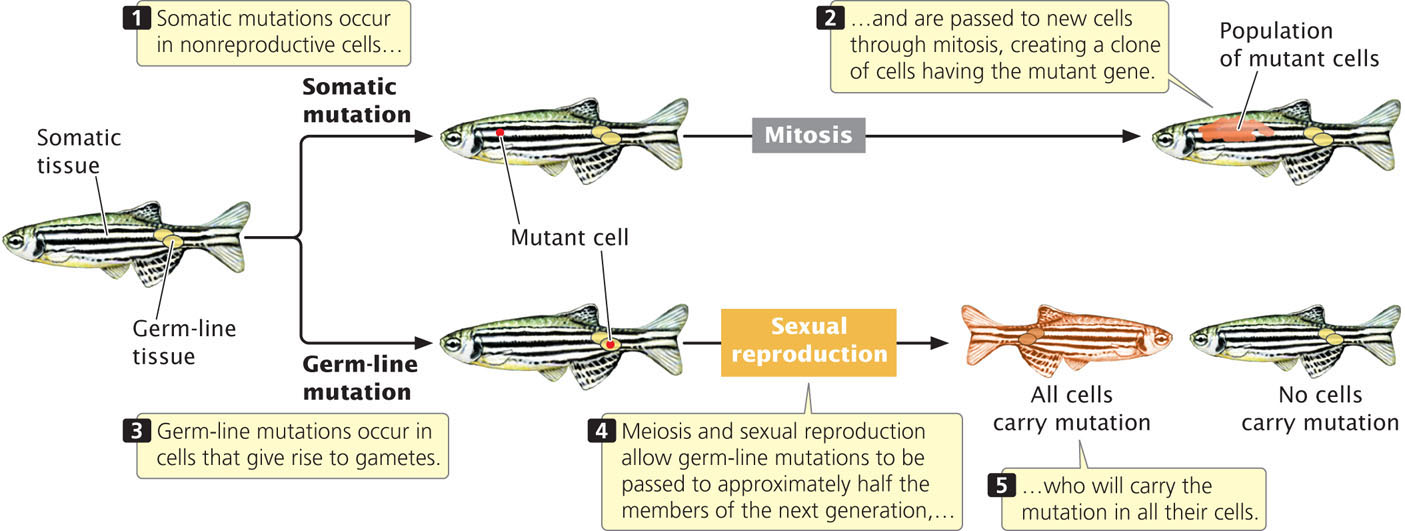
Because of the huge number of cells present in a typical eukaryotic organism, somatic mutations are numerous. For example, there are about 1014 cells in the human body. Typically, a mutation arises once in every million cell divisions, so hundreds of millions of somatic mutations must arise in each person. Many somatic mutations have no obvious effect on the phenotype of the organism, because the function of the mutant cell is replaced by that of normal cells or the mutant cell dies and is replaced by normal cells. However, cells with a somatic mutation that stimulates cell division can increase in number and spread; this type of mutation can give rise to cells with a selective advantage and is the basis for cancers (see Chapter 23).
Germ-line mutations arise in cells that ultimately produce gametes. A germ-line mutation can be passed to future generations, producing individual organisms that carry the mutation in all their somatic and germ-line cells (see Figure 18.1). When we speak of mutations in multicellular organisms, we’re usually talking about germ-line mutations.
Historically, mutations have been partitioned into those that affect a single gene, called gene mutations, and those that affect the number or structure of chromosomes, called chromosome mutations. This distinction arose because chromosome mutations could be observed directly, by looking at chromosomes with a microscope, whereas gene mutations could be detected only by observing their phenotypic effects. Now, DNA sequencing allows direct observation of gene mutations, and chromosome mutations are distinguished from gene mutations somewhat arbitrarily on the basis of the size of the DNA lesion. Nevertheless, it is practical to use chromosome mutation for a large-scale genetic alteration that affects chromosome structure or the number of chromosomes and to use gene mutation for a relatively small DNA lesion that affects a single gene. This chapter focuses on gene mutations; chromosome mutations were discussed in Chapter 8.
Types of Gene Mutations
There are a number of ways to classify gene mutations. Some classification schemes are based on the nature of the phenotypic effect, others are based on the causative agent of the mutation, and still others focus on the molecular nature of the defect. Here, we will categorize mutations primarily on the basis of their molecular nature, but we will also encounter some terms that relate the causes and the phenotypic effects of mutations.
Base Substitutions
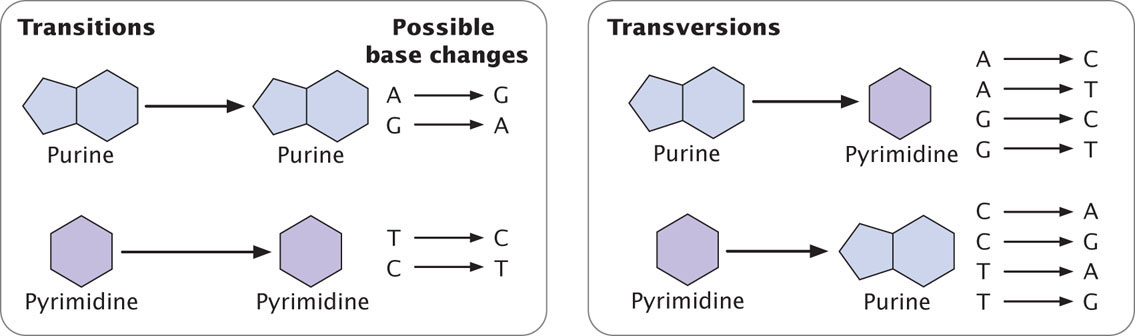
The simplest type of gene mutation is a base substitution, the alteration of a single nucleotide in the DNA (Figure 18.2a). There are two types of base substitutions. In a transition, a purine is replaced by a different purine or, alternatively, a pyrimidine is replaced by a different pyrimidine (Figure 18.3). In a transversion, a purine is replaced by a pyrimidine or a pyrimidine is replaced by a purine. The number of possible transversions (see Figure 18.3) is twice the number of possible transitions, but transitions arise more frequently because transforming a purine into different purine or a pyrimidine into different pyrimidine is easier than transforming a purine into pyrimidine, or vice versa. ![]() TRY PROBLEM 18
TRY PROBLEM 18

Insertions and Deletions
Another class of gene mutations contains insertions and deletions (collectively called indels)—the addition or removal, respectively, of one or more nucleotide pairs (Figure 18.2b and c). Although base substitutions are often assumed to be the most common type of mutation, molecular analysis has revealed that insertions and deletions are often more frequent. Insertions and deletions within sequences that encode proteins may lead to frameshift mutations, changes in the reading frame of the gene. Frameshift mutations usually alter all amino acids encoded by nucleotides following the mutation, and so they generally have drastic effects on the phenotype. Some frameshifts also introduce premature stop codons, terminating protein synthesis early and resulting in a shortened (truncated) protein. Not all insertions and deletions lead to frameshifts, however; insertions and deletions consisting of any multiple of three nucleotides will leave the reading frame intact, although the addition or removal of one or more amino acids may still affect the phenotype. Indels not affecting the reading frame are called in-frame insertions and in-frame deletions.
CONCEPTS
Gene mutations consist of changes in a single gene and can be base substitutions (a single pair of nucleotides is altered) or insertions or deletions (nucleotides are added or removed). A base substitution can be a transition (substitution of like bases) or a transversion (substitution of unlike bases). Insertions and deletions often lead to a change in the reading frame of a gene.
 CONCEPT CHECK 1
CONCEPT CHECK 1Which of the following changes is a transition base substitution?
- Adenine is replaced by thymine.
- Cytosine is replaced by adenine.
- Guanine is replaced by adenine.
- Three nucleotide pairs are inserted into DNA.
Expanding Nucleotide Repeats
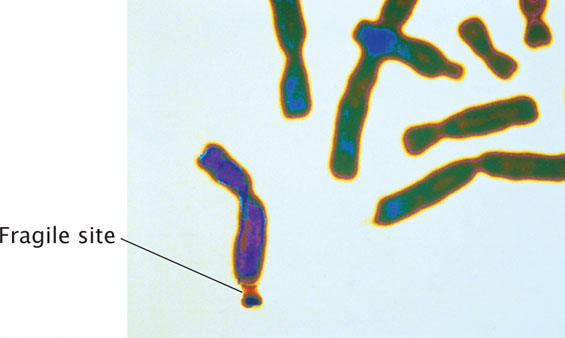
Mutations in which the number of copies of a set of nucleotides increases are called expanding nucleotide repeats. This type of mutation was first observed in 1991 in a gene called FMR-1, which causes fragile-X syndrome, the most common hereditary cause of intellectual disability. The disorder is so named because, in specially treated cells from persons having the condition, the tip of each long arm of the X chromosome is attached by a slender-appearing part of the chromosome (Figure 18.4). The normal FMR-1 allele (not containing the mutation) has 60 or fewer copies of CGG but, in persons with fragile-X syndrome, the allele may harbor hundreds or even thousands of copies.
Expanding nucleotide repeats have been found in almost 30 human diseases, several of which are listed in Table 18.1. Most of these diseases are caused by the expansion of a set of three nucleotides (called a trinucleotide), most often CNG, where N can be any nucleotide. However, some diseases are caused by repeats of four, five, and even twelve nucleotides. The number of copies of the nucleotide repeat often correlates with the severity or age of onset of the disease. The number of copies of the repeat also correlates to the instability of nucleotide repeats: when more repeats are present, the probability of expansion to even more repeats increases. This association between the number of copies of nucleotide repeats, the severity of the disease, and the probability of expansion leads to a phenomenon known as anticipation (see Chapter 5), in which diseases caused by nucleotide-repeat expansions become more severe in each generation. Less commonly, the number of nucleotide repeats may decrease within a family. Expanding nucleotide repeats have also been observed in some microbes and plants.
| Number of Copies of Repeat | |||
|---|---|---|---|
| Disease | Repeated Sequence | Normal Range | Disease Range |
| Spinal and bulbar muscular atrophy | CAG | 11-33 | 40-62 |
| Fragile-X syndrome | CGG | 6-54 | 50-1500 |
| Jacobsen syndrome | CGG | 11 | 100-1000 |
| Spinocerebellar ataxia (several types) | CAG | 4-44 | 21-130 |
| Autosomal dominant cerebellar ataxia | CAG | 7-19 | 37-220 |
| Myotonic dystrophy | CTG | 5-37 | 44-3000 |
| Huntington disease | CAG | 9-37 | 37-121 |
| Friedreich ataxia | GAA | 6-29 | 200-900 |
| Dentatorubral-pallidoluysian atrophy | CAG | 7-25 | 49-75 |
| Myoclonus epilepsy of the Unverricht-Lundborg type | CCCCGCCCCGCG | 2-3 | 12-13 |
Increases in the number of nucleotide repeats can produce disease symptoms in different ways. In several of the diseases (e.g., Huntington disease), the nucleotide expands within the coding part of a gene, producing a toxic protein that has extra glutamine residues (the amino acid encoded by CAG). In other diseases, the repeat is outside the coding region of a gene and affects its expression. In fragile-X syndrome, additional copies of the nucleotide repeat cause the DNA to become methylated, which turns off the transcription of an essential gene.
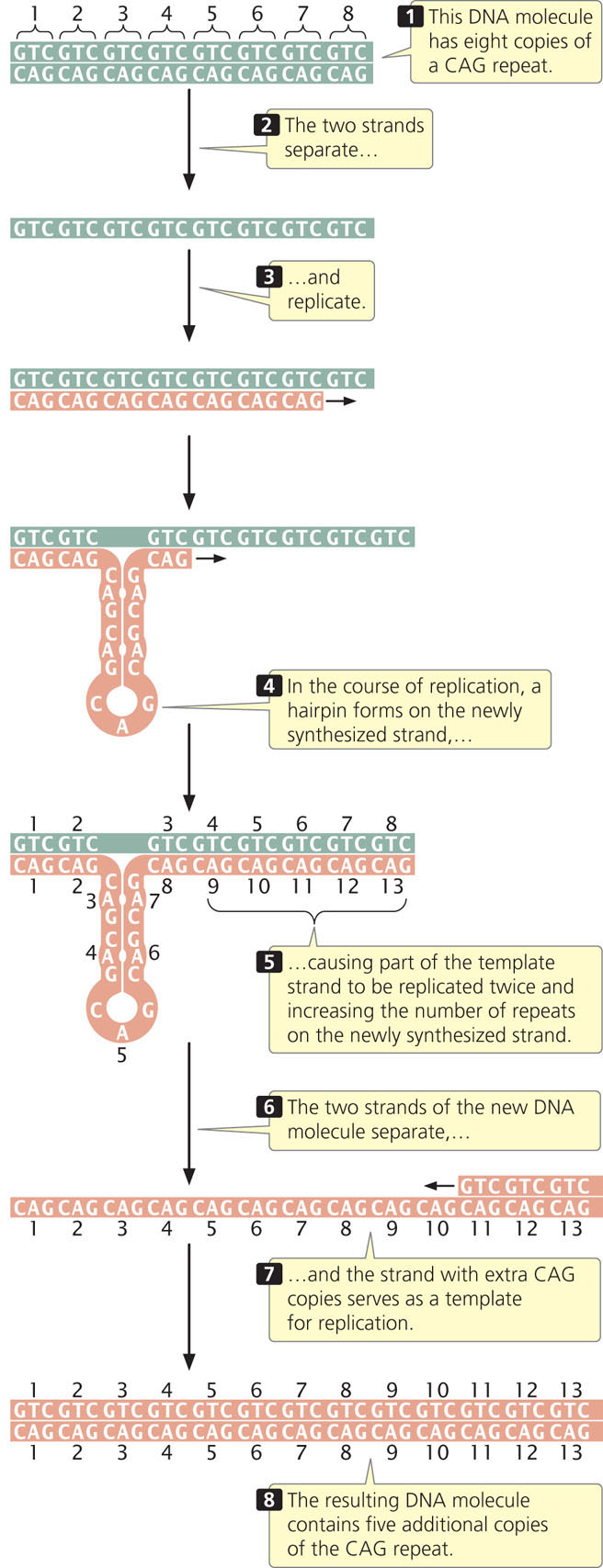
Some evidence suggests that expansion of nucleotide repeats occurs in the course of DNA replication and appears to be related to the formation of hairpins and other special DNA structures that form in single-stranded DNA consisting of nucleotide repeats. Such structures may interfere with normal replication by causing strand slippage, misalignment of the sequences, or stalling of replication. One model of how repeat hairpins might result in repeat expansion is shown in Figure 18.5. Watch  Animation 18.1 to help you understand how copies of nucleotide repeats increase in number. Other models of repeat expansion that occur through transcription and DNA repair have also been proposed. Many aspects of this phenomenon are unknown, including why repeat expansion occurs in some people and not in others.
Animation 18.1 to help you understand how copies of nucleotide repeats increase in number. Other models of repeat expansion that occur through transcription and DNA repair have also been proposed. Many aspects of this phenomenon are unknown, including why repeat expansion occurs in some people and not in others.
CONCEPTS
Expanding nucleotide repeats are regions of DNA that consist of repeated copies of sets of nucleotides. Increased numbers of nucleotide repeats are associated with several human genetic diseases.
Phenotypic Effects of Mutations
Another way that mutations are classified is on the basis of their phenotypic effects. At the most-general level, we can distinguish a mutation on the basis of its phenotype compared with the wild-type phenotype. A mutation that alters the wild-type phenotype is called a forward mutation, whereas a reverse mutation (a reversion) changes a mutant phenotype back into the wild type.
Geneticists use other terms to describe the effects of mutations on protein structure. A base substitution that results in a different amino acid in the protein is referred to as a missense mutation (Figure 18.6a). A nonsense mutation changes a sense codon (one that specifies an amino acid) into a nonsense codon (one that terminates translation), as shown in Figure 18.6b. If a nonsense mutation occurs early in the mRNA sequence, the protein will be truncated and usually nonfunctional.
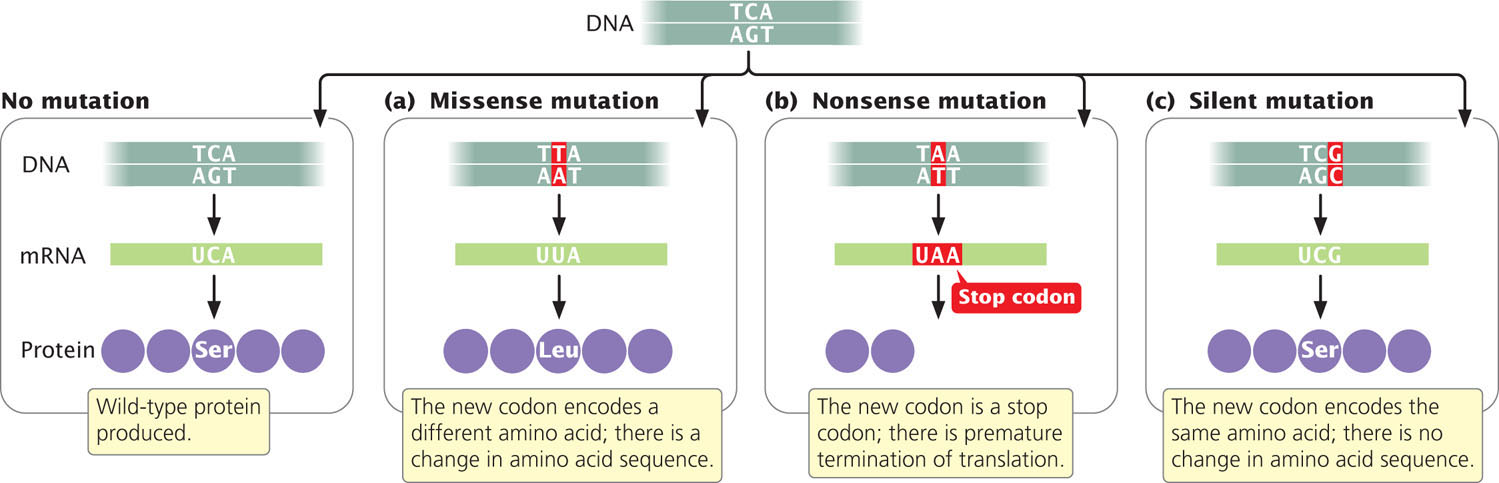
Because of the redundancy of the genetic code, some different codons specify the same amino acid. A silent mutation changes a codon to a synonymous codon that specifies the same amino acid (Figure 18.6c), altering the DNA sequence without changing the amino acid sequence of the protein. Not all silent mutations, however, are truly silent: some do have phenotypic effects. For example, silent mutations may have phenotypic effects when different tRNAs (called isoaccepting tRNAs, see Chapter 15) are used for different synonymous codons. Because some isoaccepting tRNAs are more abundant than others, which synonymous codon is used may affect the rate of protein synthesis. The rate of protein synthesis can influence the phenotype by affecting the amount of protein present in the cell and, in a few cases, the folding of the protein. Other silent mutations can alter sequences near the exon–intron junctions that affect splicing (see Chapter 14). Still other silent mutations can influence the binding of miRNAs to complementary sequences in the mRNA, which determine whether the mRNA is translated (see Chapter 14).
A neutral mutation is a missense mutation that alters the amino acid sequence of the protein but does not significantly change its function. Neutral mutations occur when one amino acid is replaced by another that is chemically similar or when the affected amino acid has little influence on protein function. For example, neutral mutations occur in the genes that encode hemoglobin; although these mutations alter the amino acid sequence of hemoglobin, they do not affect its ability to transport oxygen.
Loss-of-function mutations cause the complete or partial absence of normal protein function. A loss-of-function mutation so alters the structure of the protein that the protein no longer works correctly—or the mutation can occur in regulatory regions that affect the transcription, translation, or splicing of the protein. Loss-of-function mutations are frequently recessive: an individual diploid organism must be homozygous for a loss-of-function mutation before the effects of the loss of the functional protein can be exhibited. The mutations that cause cystic fibrosis are loss-of-function mutations: these mutations produce a nonfunctional form of the cystic fibrosis transmembrane conductance regulator protein, which normally regulates the movement of chloride ions into and out of the cell (see Chapter 5).
In contrast, a gain-of-function mutation causes the cell to produce a protein or gene product whose function is not normally present. This could be an entirely new gene product or one produced in an inappropriate tissue or at an inappropriate time in development. For example, a mutation in a gene that encodes a receptor for a growth factor might cause the mutated receptor to stimulate growth all the time, even in the absence of the growth factor. Gain-of-function mutations are frequently dominant in their expression, because a single copy of the mutation leads to the presence of a new gene product. Still other types of mutations are conditional mutations, which are expressed only under certain conditions. For example, some conditional mutations affect the phenotype only at elevated temperatures. Others are lethal mutations, causing premature death (Chapter 5). ![]() TRY PROBLEM 22
TRY PROBLEM 22
Suppressor Mutations
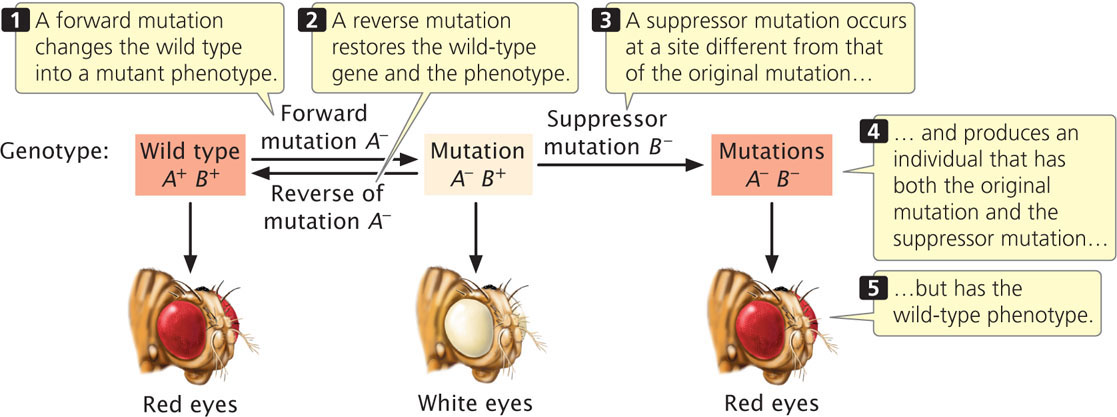
A suppressor mutation is a genetic change that hides or suppresses the effect of another mutation. This type of mutation is different from a reverse mutation, in which the mutated site changes back into the original wild-type sequence (Figure 18.7). A suppressor mutation occurs at a site that is distinct from the site of the original mutation; thus, an individual with a suppressor mutation is a double mutant, possessing both the original mutation and the suppressor mutation but exhibiting the phenotype of an unmutated wild type. Geneticists distinguish between two classes of suppressor mutations: intragenic and intergenic.
Intragenic Suppressor Mutations
An intragenic suppressor mutation takes place in the same gene as that containing the mutation being suppressed and may work in several ways. The suppressor may change a second nucleotide in the same codon altered by the original mutation, producing a codon that specifies the same amino acid as that specified by the original, unmutated codon (Figure 18.8). Intragenic suppressors may also work by suppressing a frameshift mutation. If the original mutation is a one-base deletion, then the addition of a single base elsewhere in the gene will restore the former reading frame.

Consider the following nucleotide sequence on the template stand of DNA and the amino acids that it encodes:

Suppose that a one-base deletion occurs in the first nucleotide of the second codon. This deletion shifts the reading frame by one nucleotide and alters all the amino acids that follow the mutation.
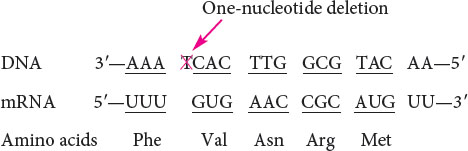
If a single nucleotide is added to the third codon (the suppressor mutation), the reading frame is restored, although two of the amino acids differ from those specified by the original sequence.

Similarly, a mutation due to an insertion may be suppressed by a subsequent deletion in the same gene.
A third way in which an intragenic suppressor may work is by making compensatory changes in the protein. A first missense mutation can alter the folding of a polypeptide chain by changing the way in which amino acids in the protein interact with one another. A second missense mutation at a different site (the suppressor) can recreate the original folding pattern by restoring interactions between the amino acids.
Intergenic Suppressor Mutations
An intergenic suppressor mutation, in contrast, occurs in a gene other than the one bearing the original mutation. These suppressors sometimes work by changing the way that the mRNA is translated. In the example illustrated in Figure 18.9a, the original DNA sequence is AAC (UUG in the mRNA) and specifies leucine. This sequence mutates to ATC (UAG in mRNA), a termination codon (Figure 18.9b). The ATC nonsense mutation could be suppressed by a second mutation in a different gene that encodes a tRNA; this second mutation would result in a codon capable of pairing with the UAG termination codon (Figure 18.9c). For example, the gene that encodes the tRNA for tyrosine (tRNATyr), which has the anticodon AUA, might be mutated to have the anticodon AUC, which will then pair with the UAG stop codon. Instead of translation terminating at the UAG codon, tyrosine would be inserted into the protein and a full-length protein would be produced, although tyrosine would now substitute for leucine. The effect of this change would depend on the role of this amino acid in the overall structure of the protein, but the effect of the suppressor mutation is likely to be less detrimental than the effect of the nonsense mutation, which would halt translation prematurely.

Because cells in many organisms have multiple copies of tRNA genes, other unmutated copies of tRNATyr would remain available to recognize tyrosine codons in the transcripts of the mutant gene in question and other genes being expressed concurrently. We might expect that the tRNAs that have undergone the suppressor mutation just described would also suppress the normal termination codons at the ends of other coding sequences, resulting in the production of longer-than-normal proteins, but this event does not usually take place.
Intergenic suppressors can also work through genic interactions (see Chapter 5). Polypeptide chains that are produced by two genes may interact to produce a functional protein. A mutation in one gene may alter the encoded polypeptide such that the interaction between the two polypeptides is destroyed, in which case a functional protein is not produced. A suppressor mutation in the second gene may produce a compensatory change in its polypeptide, therefore restoring the original interaction. Characteristics of some of the different types of mutations are summarized in Table 18.2.
| Type of Mutation | Definition |
|---|---|
| Base substitution | Changes the base of a single DNA nucleotide |
| Transition | Base substitution in which a purine replaces a purine or a pyrimidine replaces a pyrimidine |
| Transversion | Base substitution in which a purine replaces a pyrimidine or a pyrimidine replaces a purine |
| Insertion | Addition of one or more nucleotides |
| Deletion | Deletion of one or more nucleotides |
| Frameshift mutation | Insertion or deletion that alters the reading frame of a gene |
| In-frame deletion or insertion | Deletion or insertion of a multiple of three nucleotides that does not alter the reading frame |
| Expanding nucleotide repeats | Repeated sequence of a set of nucleotides in which the number of copies of the sequence increases |
| Forward mutation | Changes the wild-type phenotype to a mutant phenotype |
| Reverse mutation | Changes a mutant phenotype back to the wild-type phenotype |
| Missense mutation | Changes a sense codon into a different sense codon, resulting in the incorporation of a different amino acid in the protein |
| Nonsense mutation | Changes a sense codon into a nonsense (stop) codon, causing premature termination of translation |
| Silent mutation | Changes a sense codon into a synonymous codon, leaving unchanged the amino acid sequence of the protein |
| Neutral mutation | Changes the amino acid sequence of a protein without altering its ability to function |
| Loss-of-function mutation | Causes a complete or partial loss of function |
| Gain-of-function mutation | Causes the appearance of a new trait or function or causes the appearance of a trait in inappropriate tissue or at an inappropriate time |
| Lethal mutation | Causes premature death |
| Suppressor mutation | Suppresses the effect of an earlier mutation at a different site |
| Intragenic suppressor mutation | Suppresses the effect of an earlier mutation within the same gene |
| Intergenic suppressor mutation | Suppresses the effect of an earlier mutation in another gene |
CONCEPTS
A suppressor mutation overrides the effect of an earlier mutation at a different site. An intragenic suppressor mutation occurs within the same gene as that containing the original mutation; an intergenic suppressor mutation occurs in a different gene.
CONCEPT CHECK 2How is a suppressor mutation different from a reverse mutation?
WORKED PROBLEM
A gene encodes a protein with the following amino acid sequence:
Met-Arg-Cys-Ile-Lys-Arg
A mutation of a single nucleotide alters the amino acid sequence to:
Met-Asp-Ala-Tyr-Lys-Gly-Glu-Ala-Pro-Val
A second single-nucleotide mutation occurs in the same gene and suppresses the effects of the first mutation (an intragenic suppressor). With the original mutation and the intragenic suppressor present, the protein has the following amino acid sequence:
Met-Asp-Gly-Ile-Lys-Arg
What is the nature and location of the first mutation and of the intragenic suppressor mutation?
What information is required in your answer to the problem?
The type and location of the first mutation and the intragenic suppressor.
What information is provided to solve the problem?
 The amino acid sequence of the protein encoded by the original unmutated gene.
The amino acid sequence of the protein encoded by the original unmutated gene.-
The amino acid sequence of the protein encoded by the mutated gene.
-
The amino acid sequence of the protein encoded by the mutated gene and the intragenic suppressor.
The first mutation alters the reading frame, because all amino acids after Met are changed. Insertions and deletions affect the reading frame; the original mutation consists of a single-nucleotide insertion or deletion in the second codon. The intragenic suppressor restores the reading frame; the intragenic suppressor also is most likely a single-nucleotide insertion or deletion. If the first mutation is an insertion, the suppressor must be a deletion; if the first mutation is a deletion, then the suppressor must be an insertion. Notice that the protein produced by the suppressor still differs from the original protein at the second and third amino acids, but the second amino acid produced by the suppressor is the same as that in the protein produced by the original mutation. Thus, the suppressor mutation must have occurred in the third codon, because the suppressor does not alter the second amino acid.
For more practice with analyzing mutations, try working Problem 23 at the end of the chapter.
Mutation Rates
The frequency with which a wild-type allele at a locus changes into a mutant allele is referred to as the mutation rate and is generally expressed as the number of mutations per biological unit, which may be mutations per cell division, per gamete, or per round of replication. For example, achondroplasia is a type of hereditary dwarfism in humans that results from a dominant mutation. On average, about four achondroplasia mutations arise in every 100,000 gametes, and so the mutation rate is 4/100,000, or 0.00004 mutations per gamete. The mutation rate provides information about how often a mutation arises.
Factors Affecting Mutation Rates
Calculations of mutation rates are affected by three factors. First, they depend on the frequency with which a change takes place in DNA. A change in the DNA can arise from spontaneous molecular changes in DNA or it can be induced by chemical, biological, or physical agents in the environment.
The second factor influencing the mutation rate is the probability that when a change takes place, it will be repaired. Most cells possess a number of mechanisms for repairing altered DNA, so most alterations are corrected before they are replicated. If these repair systems are effective, mutation rates will be low; if they are faulty, mutation rates will be elevated. Some mutations increase the overall rate of mutation at other genes; these mutations usually occur in genes that encode components of the replication machinery or DNA-repair enzymes.
The third factor is the probability that a mutation will be detected. When DNA is sequenced, all mutations are potentially detectable. In practice, however, mutations are usually detected by their phenotypic effects. Some mutations may appear to arise at a higher rate simply because they are easier to detect.
Variation in Mutation Rates
We can draw several general conclusions about mutation rates, though they vary among genes and species (Table 18.3). First, spontaneous mutation rates are low for all organisms studied. Typical mutation rates for bacterial genes range from about 1 to 100 mutations per 10 billion cells (from 1 × 10–8 to 1 × 10–10). The mutation rates for most eukaryotic genes are a bit higher, from about 1 to 10 mutations per million gametes (from 1 × 10–5 to 1 × 10–6). These higher values in eukaryotes may be due to the fact that the rates are calculated per gamete, and several cell divisions are required to produce a gamete, whereas mutation rates in prokaryotic cells are calculated per cell division.
| Organism | Mutation | Rate | Unit |
|---|---|---|---|
| Bacteriophage T2 | Lysis inhibition | 1 × KT8 | Per replication |
| Host range | 3 × 10–9 | ||
| Escherichia coli | Lactose fermentation | 2 × 10–7 | Per cell division |
| Histidine requirement | 2 × 10–8 | ||
| Neurospora crassa | Inositol requirement | 8 × 10–8 | Per asexual spore |
| Adenine requirement | 4 × 10–8 | ||
| Corn | Kernel color | 2.2 × 10–6 | Per gamete |
| Drosophila | Eye color | 4 × 10–5 | Per gamete |
| Allozymes | 5.14 × 10–6 |
||
| Mouse | Albino coat color | 4.5 × 10–5 | Per gamete |
| Dilution coat color | 3 × 10–5 | ||
| Human | Huntington disease | 1 × 10–6 | Per gamete |
| Achondroplasia | 1 × 10–5 | ||
| Neurofibromatosis (Michigan) | 1 × 10–4 | ||
| Hemophilia A (Finland) | 3.2 × 10–5 | ||
| Duchenne muscular dystrophy (Wisconsin) | 9.2 × 10–5 |
The differences in mutation rates among species may be due to differing abilities to repair mutations, unequal exposures to mutagens, or biological differences in rates of spontaneously arising mutations. Even within a single species, spontaneous rates of mutation vary among genes. The reason for this variation is not entirely understood, but some regions of DNA are known hotspots for mutations.
Recent research suggests that fewer mutations occur in DNA sequences that are occupied by nucleosomes (see Chapter 11). Reduced mutation rates may occur in these sequences because DNA associated with nucleosomes is less exposed to mutagens, but it could also be explained by the effect of nucleosomes on DNA repair, recombination, or replication, all of which influence the rate of mutation.
Several recent studies have measured mutation rates directly by sequencing genes of organisms before and after a number of generations. These new studies suggest that mutation rates are often higher than those previously measured on the basis of changes in phenotype. In one study, geneticists sequenced randomly chosen stretches of DNA in the nematode worm Caenorhabditis elegans and found about 2.1 mutations per genome per generation, which was 10 times as high as previous estimates based on phenotypic changes. The researchers found that about half of the mutations were insertions and deletions.
Recent genome sequencing has also provided more accurate information about mutation rates in humans. Several sequencing studies suggest that the overall rate of base substitutions in humans is about 1 × 10–8 mutations per base pair per generation. Other research suggests that each person carries approximately 100 loss-of-function germ-line mutations.
Adaptive Mutation
As will be discussed in Chapters 24 through 26, genetic variation is critical for evolutionary change that brings about adaptation to new environments. New genetic variants arise primarily through mutation. For many years, genetic variation was assumed to arise randomly and at rates that are independent of the need for adaptation. However, some evidence suggests that stressful environments—where adaptation may be necessary to survive—can induce more mutations in bacteria, a process that has been termed adaptive mutation. The idea of adaptive mutation has been intensely debated; critics counter that most mutations are expected to be deleterious, and so increased mutagenesis would likely be harmful most of the time.
CONCEPTS
Mutation rate is the frequency with which a specific mutation arises. Rates of mutations are generally low and are affected by environmental and genetic factors.
CONCEPT CHECK 3What three factors affect mutation rates?