CONCEPT10.2 DNA Expression Begins with Its Transcription to RNA
Transcription—the formation of a specific RNA sequence from a specific DNA sequence—requires several key components:
198
- A DNA template for complementary base pairing
- The four ribonucleoside triphosphates (ATP, GTP, CTP, and UTP) to act as substrates
- An RNA polymerase enzyme
The same transcription process is responsible for the synthesis of mRNA, tRNA, and rRNA. Like mRNA, tRNA and rRNA are encoded by specific genes; their important roles in protein synthesis will be described in Concepts 10.3 and 10.4. There are also other kinds of RNA in the cell, with functions other than protein synthesis.
LINK
Small nuclear RNAs are involved in processing mRNA after it is transcribed, and microRNAs play important roles in stimulating or inhibiting gene expression; see Concept 11.4
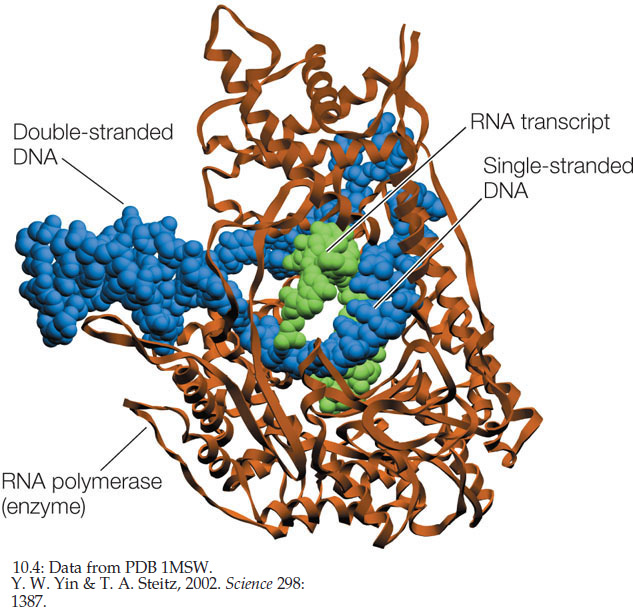
RNA polymerases share common features
RNA polymerases from both prokaryotes and eukaryotes catalyze the synthesis of RNA from the DNA template. There is only one kind of RNA polymerase in bacteria and archaea, whereas there are several kinds in eukaryotes. However, they all share a common structure (FIGURE 10.4). Like DNA polymerases, RNA polymerases are processive; that is, a single enzyme–template binding event results in the polymerization of hundreds of RNA nucleotides. But unlike DNA polymerases, RNA polymerases do not require a primer.
Transcription occurs in three steps
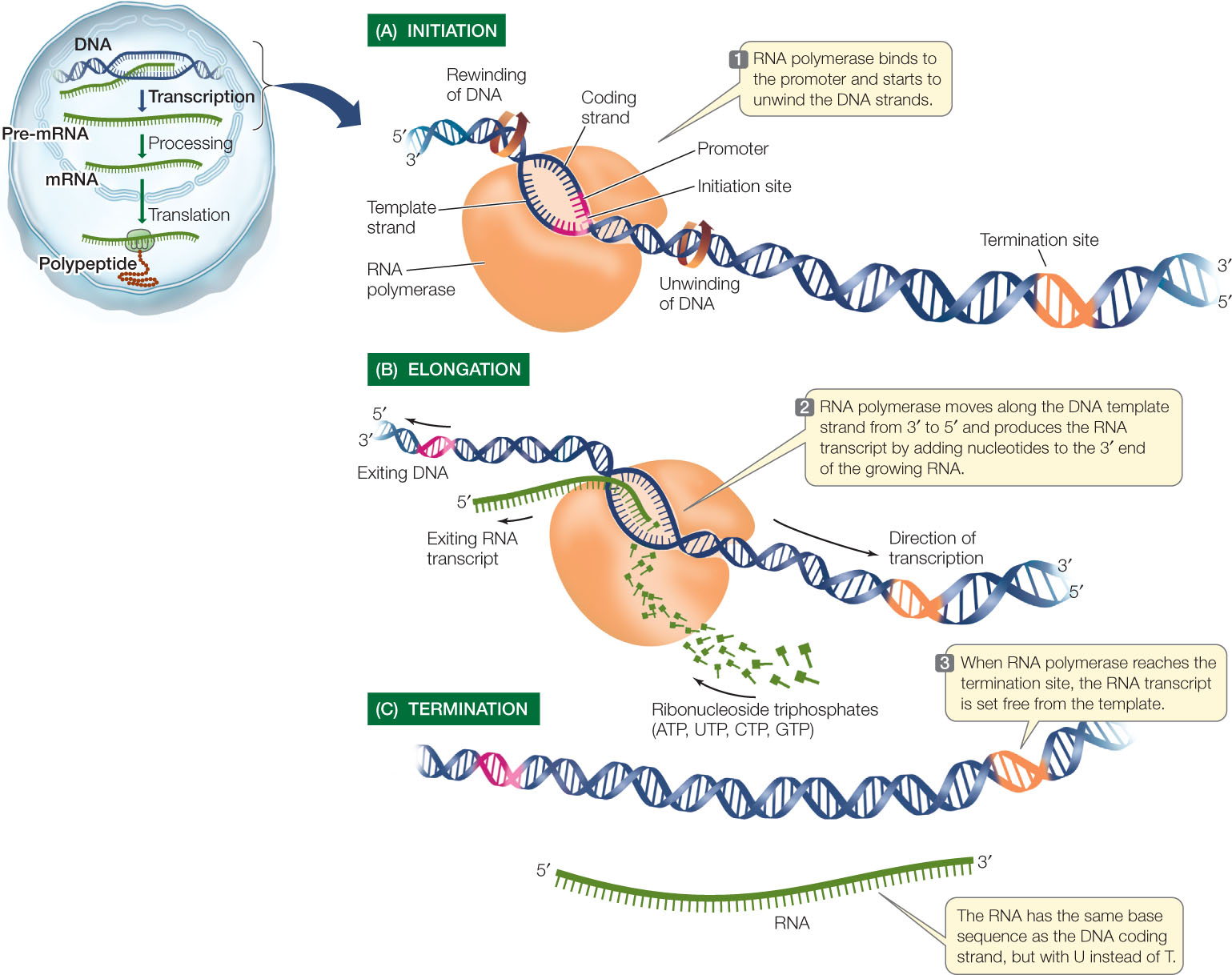
Transcription can be divided into three distinct processes: initiation, elongation, and termination. You can follow these processes in FIGURE 10.5.
Initiation
Transcription begins with initiation, which requires a promoter, a special DNA sequence to which the RNA polymerase binds very tightly (see Figure 10.5A). Promoters are control sequences that “tell” the RNA polymerase two crucial things:
- Where to start transcription
- Which of the two DNA strands to transcribe and under what conditions
The promoter has a nucleotide sequence that can be “read” in a particular direction and orients the RNA polymerase, thus “aiming” it at the correct strand to use as a template. Part of each promoter is the transcription initiation site, where transcription begins. Groups of nucleotides lying “upstream” from the initiation site (5′ on the coding strand and 3′ on the template strand) are bound by other proteins, which help the RNA polymerase bind. These other proteins, called sigma factors and transcription factors, help determine which genes are expressed at a particular time in a particular cell.
LINK
The roles of sigma factors and transcription factors are described in Concepts 11.1 and 11.2
Every gene has a promoter, but not all promoters are identical; some promoters are more effective at transcription initiation than others. Furthermore, bacteria, archaea, and eukaryotes differ in the details of transcription initiation. Despite these variations, the basic mechanisms of initiation are the same throughout the living world and provide further evidence of the biochemical unity of life on Earth.
Elongation
Once RNA polymerase has bound to the promoter, it begins the process of elongation (see Figure 10.5B). RNA polymerase unwinds the DNA about 13 base pairs at a time and reads the template strand in the 3′-to-5′ direction. Like DNA polymerase, RNA polymerase adds new nucleotides to the 3′ end of the growing strand, beginning with the first nucleotide at the transcription initiation site. Thus the first nucleotide in the new RNA forms its 5′ end, and the RNA transcript is antiparallel to the DNA template strand.
RNA polymerase adds new nucleotides to the RNA molecule by complementary base pairing with nucleotides in the template strand of the DNA. This process is similar to DNA replication except that the base uracil (rather than thymine) in the RNA molecule is paired with adenine in the DNA molecule. In a mechanism very similar to that used by DNA polymerase, the RNA polymerase uses the ribonucleoside triphosphates ATP, UTP, GTP, and CTP as substrates and catalyzes the formation of phosphodiester bonds between them, releasing pyrophosphate in the process (see Figure 9.7). As transcription progresses, the two DNA strands rewind and the RNA grows as a single-stranded molecule (see Figure 10.5B).
Like DNA polymerases, RNA polymerases and associated proteins have mechanisms for proofreading during transcription, but these mechanisms are not as efficient as those for DNA. Transcriptional errors occur at rates of about 1 for every 104 to 105 bases. Because many copies of RNA are made, however, and because they often have relatively short life spans, these errors are not as potentially harmful as mutations in DNA.
199
Termination
Just as initiation sites in the DNA template strand specify the starting point for transcription, particular base sequences specify its termination (see Figure 10.5C). The mechanisms of termination are complex and vary among different genes and organisms. In eukaryotes, multiple proteins are involved in recognizing the transcription termination site and separating the newly formed RNA strand from the DNA template and the RNA polymerase.
Eukaryotic coding regions are often interrupted by introns
Coding regions are sequences within a DNA molecule that are eventually translated as proteins. The coding region on the DNA template strand is transcribed into a complementary mRNA molecule, which has the same base sequence (with U’s instead of T’s) as the DNA coding strand. In prokaryotes, most of the genomic DNA is made up of coding regions, and the mRNAs are usually co-linear with them. That is, the mRNA sequence (e.g., 5′-AUGAUAGCCCC….) can be found in the DNA coding strand (e.g., 5′-ATGATAGCCCC….) without interruptions. In eukaryotes the situation is often different (TABLE 10.1).

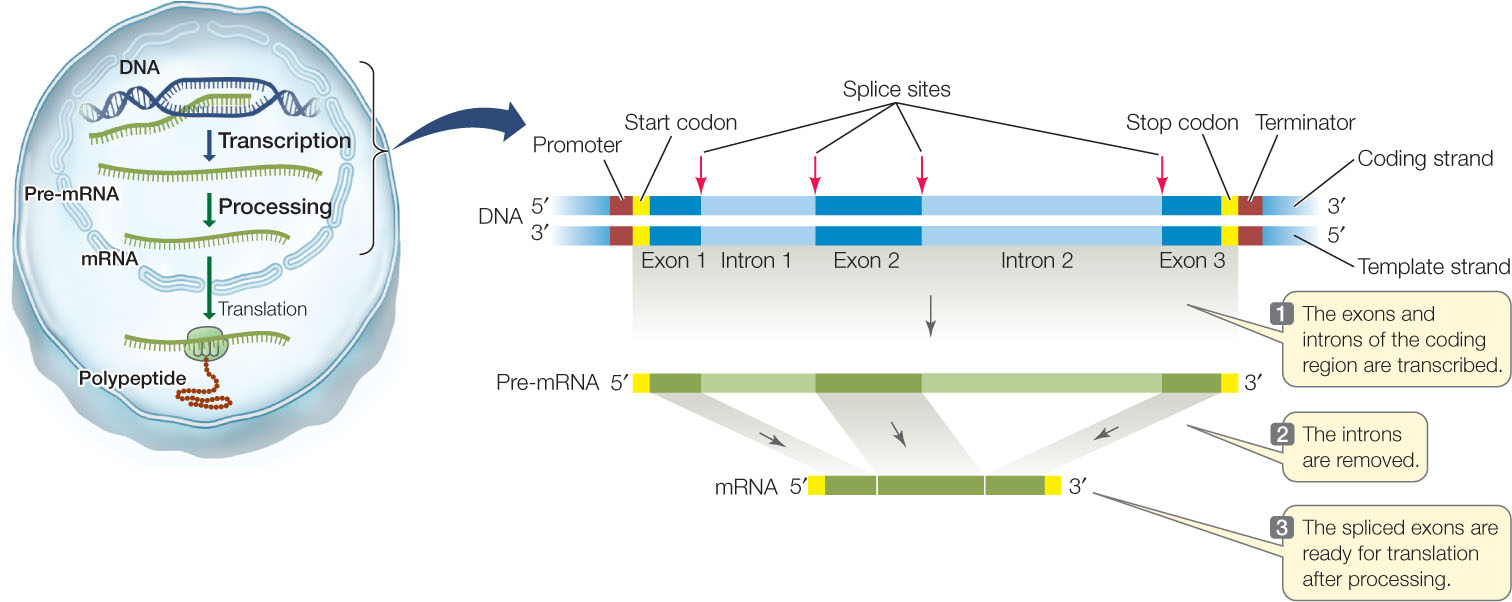
A diagram of the structure and transcription of a typical eukaryotic gene is shown in FIGURE 10.6. In prokaryotes and viruses several adjacent genes sometimes share one promoter, but in eukaryotes each gene has its own promoter. And while the coding region of a prokaryotic gene is usually continuous (with no interruptions), a eukaryotic gene may contain noncoding sequences called introns (intervening regions) that interrupt the coding region. The transcribed regions that are interspersed with the introns are called exons (expressed regions). Both introns and exons appear in the primary mRNA transcript, called the precursor RNA, or pre-mRNA, but the introns are removed by the time the mature mRNA leaves the nucleus. Pre-mRNA processing involves cutting introns out of the pre-mRNA transcript and splicing together the exon transcripts (see Figure 10.6). If this seems surprising to you, you are in good company. For scientists who were familiar with prokaryotic genes and gene expression, the discovery of introns in eukaryotic genes was entirely unexpected.
200
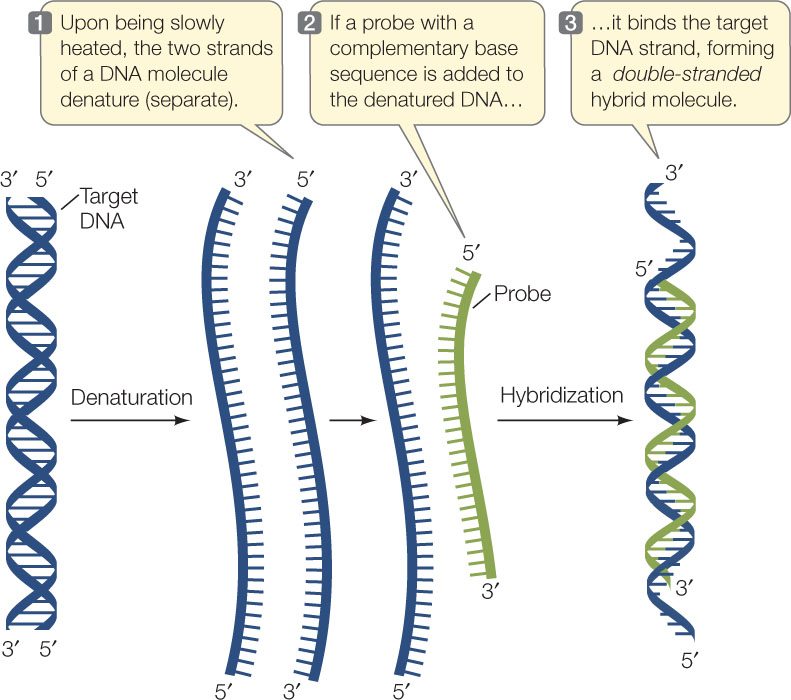
How can we locate introns within a eukaryotic gene? One way is by nucleic acid hybridization, the method that originally revealed the existence of introns. This method, outlined in FIGURE 10.7, has been crucial for studying the relationship between eukaryotic genes and their transcripts and is widely used in many applications. It involves two steps:
- The DNA to be analyzed is denatured by heat to break the hydrogen bonds between the base pairs and separate the two strands.
- A single-stranded nucleic acid from another source (called a probe) is incubated with the denatured DNA. If the probe has a base sequence complementary to the target DNA, a probe–target double helix forms by hydrogen bonding between the bases. Because the two strands are from different sources, the resulting double-stranded molecule is called a hybrid.
RESEARCH TOOLS
Biologists used this technique to examine the β-globin gene, which encodes a hemoglobin subunit (FIGURE 10.8). The researchers first denatured DNA containing the gene by heating it slowly, then used previously isolated β-globin mRNA as a probe. They were able to view the hybridized molecules using electron microscopy. As expected, the mRNA bound to the template DNA by complementary base pairing. The researchers expected to obtain a linear (1:1) matchup of the mRNA to the coding DNA. That expectation was only partially met. There were indeed stretches of RNA–DNA hybrid, but some unexpected looped structures were also visible. These loops turned out to be introns, stretches of DNA that did not have complementary base sequences on the mature mRNA.
Investigation
HYPOTHESIS
All regions within the coding sequence of a gene end up in its mRNA.
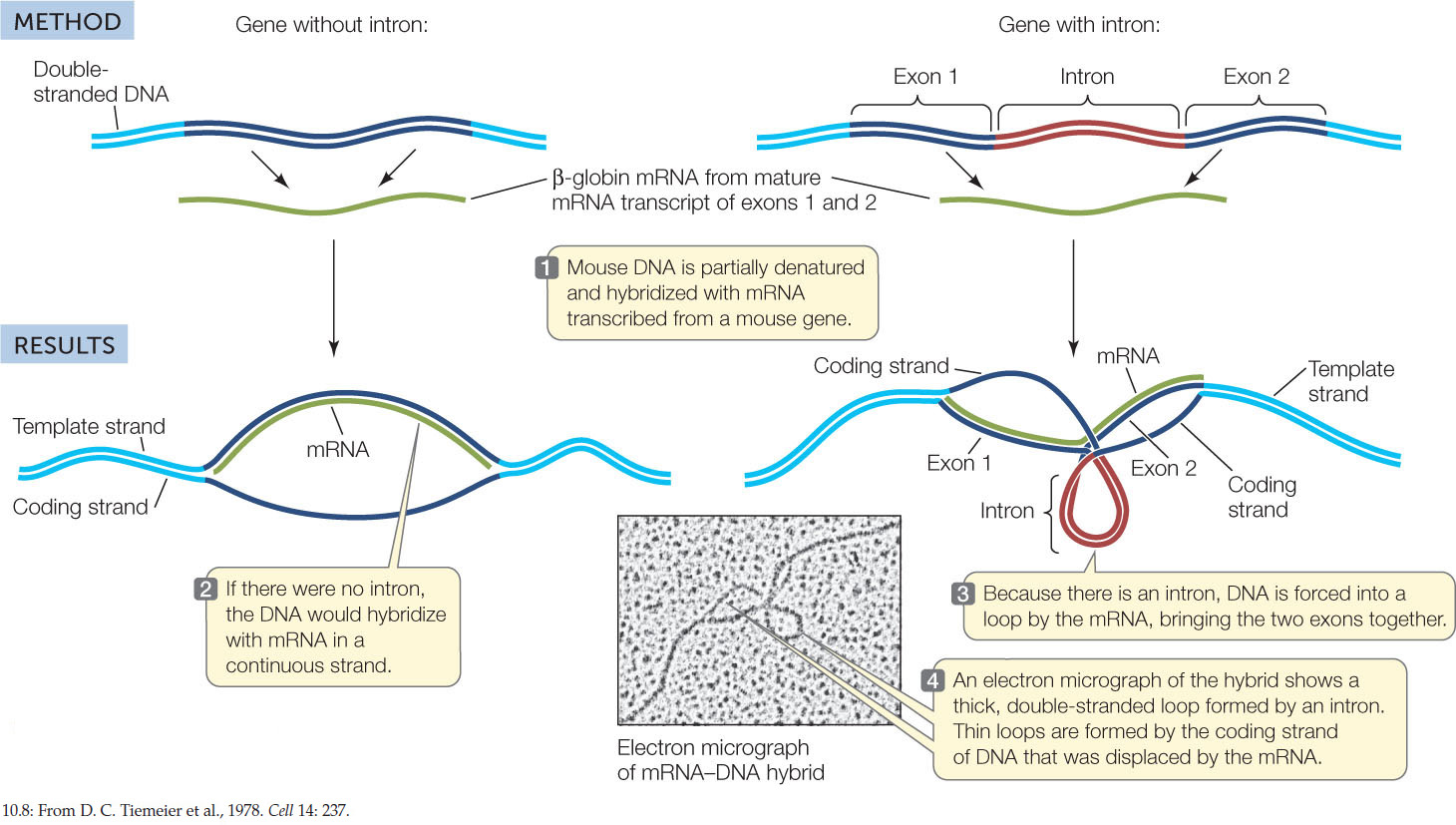
CONCLUSION
The DNA contains noncoding regions within the genes that are not present in the mature mRNA.
aS. M. Tilghman et al. 1978. Proceedings of the National Academy of Sciences USA 75: 725–729.
201
When pre-mRNA was used instead of mature mRNA to hybridize to the DNA, there was complete hybridization with no loops, revealing that the introns were part of the pre-mRNA transcript. Somewhere on the path from primary transcript (pre-mRNA) to mature mRNA, the introns had been removed, and the exons had been spliced together. We will examine this splicing process in the next section.
Introns interrupt, but do not scramble, the DNA sequence of a gene. The base sequences of the exons in the template strand, if joined and taken in order, form a continuous sequence that is complementary to that of the mature mRNA. Most (but not all) eukaryotic genes contain introns, and in rare cases, introns are also found in prokaryotes. The largest human gene encodes a muscle protein called titin; it has 363 exons, which together code for 38,138 amino acids. Can you deduce how many introns the titin gene has?
Eukaryotic gene transcripts are processed before translation
The primary transcript of a eukaryotic gene is modified in several ways before it leaves the nucleus: introns are removed, and both ends of the pre-mRNA are chemically modified.
Splicing to Remove Introns
After the pre-mRNA is made, its introns must be removed. If this did not happen, the extra nucleotides in the mRNA would be translated at the ribosome and a nonfunctional protein would result. A process called RNA splicing removes the introns and splices the exons together.
202
At the boundaries between introns and exons are consensus sequences—short stretches of DNA that appear with little variation (“consensus”) in many different genes. As soon as the pre-mRNA is transcribed, these consensus sequences are bound by several small nuclear ribonucleoprotein particles (snRNPs) (FIGURE 10.9). The RNA in one of the snRNPs has a stretch of bases complementary to the consensus sequence at the 5′ exon–intron boundary, and it binds to the pre-mRNA by complementary base pairing. Another snRNP binds to the pre-mRNA near the 3′ intron–exon boundary, and then other proteins accumulate to form a large RNA–protein complex called a spliceosome. This complex cuts the pre-mRNA, releases the introns, and joins the ends of the exons together to produce mature mRNA.
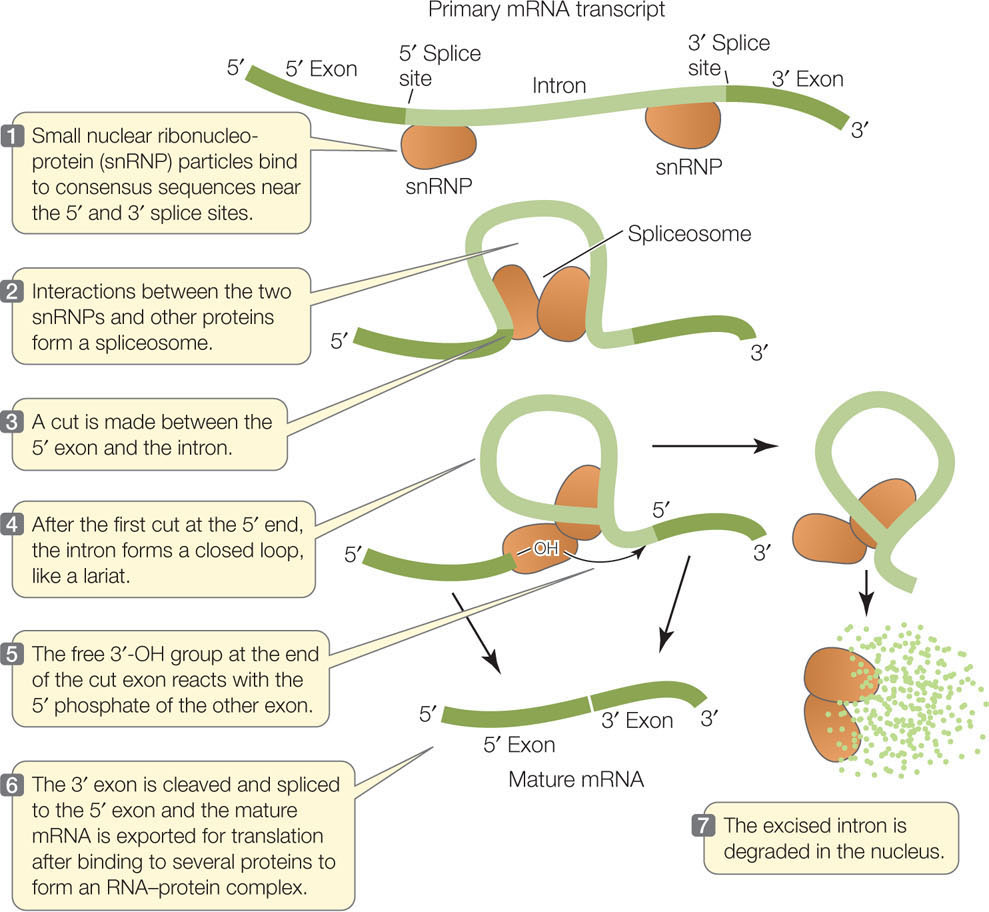
Molecular studies of human genetic diseases have provided insights into intron consensus sequences and the splicing machinery. For example, people with the genetic disease beta thalassemia have a defect in the production of one of the hemoglobin subunits. These people suffer from severe anemia because they have an inadequate supply of red blood cells. In some cases, the genetic mutation that causes the disease occurs at an intron consensus sequence in the β-globin gene. Consequently, the β-globin pre-mRNA cannot be spliced correctly, and a defective β-globin mRNA is made. This finding offers another example of how biologists can use mutations to elucidate cause-and-effect relationships.
Modification at Both Ends
While the pre-mRNA is still in the nucleus it undergoes two processing steps, one at each end of the molecule:

- A 5′ cap (or G cap) is added to the 5′ end of the pre-mRNA as it is transcribed. The 5′ cap is a chemically modified molecule of guanosine triphosphate (GTP). It facilitates the binding of mRNA to the ribosome for translation, and it protects the mRNA from being digested by ribonucleases (enzymes that break down RNAs).
- A poly A tail is added to the 3′ end of the pre-mRNA at the end of transcription. This sequence of 100–300 adenine nucleotides assists in the export of the mRNA from the nucleus and is also important for mRNA stability.
CHECKpointCONCEPT10.2
- Part of a DNA template strand has the sequence 5′-ATGGTGTACG-3′. What will be the sequence of the RNA transcribed from this DNA? (Be careful to specify the 5′ and 3′ ends.)
- What would be the consequences of the following?
- A mutation of a promoter sequence such that the promoter is deleted
- A mutation of the gene that encodes RNA polymerase, such that the polymerase is not made
- Deletion of intron consensus sequences from a gene
- Refer to the experiment shown in Figure 10.8. What would the result have been if there were five exons and four introns? Sketch what this would look like in an electron micrograph.
The transcription of a gene to produce mRNA is only the first step in gene expression. The next step in the pathway from DNA to RNA to protein is translation, the subject of Concepts 10.3 and 10.4. First we will discuss the genetic code, which enables the base sequence in an mRNA to be translated into a specific amino acid sequence in the resulting polypeptide. Then we will look in more detail at the process of translation.
203