4.3 Vision II: Recognizing What We Perceive
Our journey into the visual system has already revealed how it accomplishes some pretty astonishing feats. But the system needs to do much more in order for us to be able to interact effectively with our visual worlds. Let us now consider how the system links together individual visual features into whole objects, allows us to recognize what those objects are, organizes objects into visual scenes, and detects motion and change in those scenes. Along the way we will see that studying visual errors and illusions provides key insights into how these processes work.
4.3.1 Attention: The “Glue” That Binds Individual Features into a Whole
Specialized feature detectors in different parts of the visual system analyze each of the multiple features of a visible object: orientation, colour, size, shape, and so forth. But how are different features combined into single, unified objects? What allows us to perceive so easily and correctly that the young man in the photograph is wearing a red shirt and the young woman is wearing a yellow shirt? How come we do not see free-

4.3.1.1 Illusory Conjunctions: Perceptual Mistakes
How does the study of illusory conjunctions help us understand the role of attention in feature binding?
In everyday life, we correctly combine features into unified objects so automatically and effortlessly that it may be difficult to appreciate that binding is ever a problem at all. However, researchers have discovered errors in binding that reveal important clues about how the process works. One such error is known as an illusory conjunction, a perceptual mistake where features from multiple objects are incorrectly combined. In a pioneering study of illusory conjunctions, Anne Treisman and Hilary Schmidt (1982) briefly showed study participants visual displays in which black digits flanked coloured letters, then instructed them first to report the black digits and second to describe the coloured letters. Participants frequently reported illusory conjunctions, claiming to have seen, for example, a blue A or a red X instead of the red A and the blue X that had actually been shown (see FIGURE 4.15a and b). These illusory conjunctions were not just the result of guessing; they occurred more frequently than other kinds of errors, such as reporting a letter or colour that was not present in the display (see FIGURE 4.15c). Illusory conjunctions look real to the participants, who were just as confident they had seen them as they were about the actual coloured letters they perceived correctly.
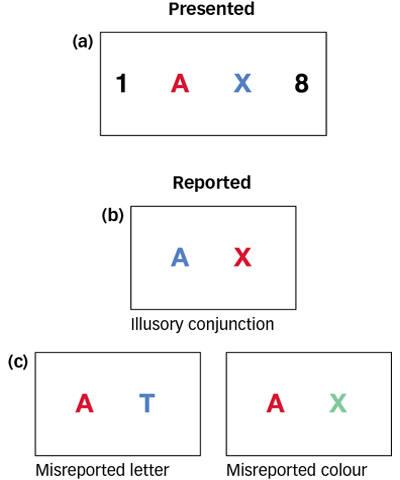
Why do illusory conjunctions occur? Treisman and her colleagues have tried to explain them by proposing a feature-integration theory (Treisman, 1998, 2006; Treisman & Gelade, 1980; Treisman & Schmidt, 1982), which holds that focused attention is not required to detect the individual features that comprise a stimulus, such as the colour, shape, size, and location of letters, but is required to bind those individual features together. From this perspective, attention provides the “glue” necessary to bind features together, and illusory conjunctions occur when it is difficult for participants to pay full attention to the features that need to be glued together. For example, in the experiments we just considered, participants were required to process the digits that flank the coloured letters, thereby reducing attention to the letters and allowing illusory conjunctions to occur. When experimental conditions are changed so that participants can pay full attention to the coloured letters, and they are able to correctly bind their features together, illusory conjunctions disappear (Treisman, 1998; Treisman & Schmidt, 1982).
4.3.1.2 The Role of the Parietal Lobe
The binding process makes use of feature information processed by structures within the ventral visual stream, the “what” pathway (Seymour et al., 2010) (see Figure 4.13). But because binding involves linking together features processed in distinct parts of the ventral stream at a particular spatial location, it also depends critically on the parietal lobe in the dorsal stream, the “where” pathway (Robertson, 1999). For example, Treisman and others studied R.M., who had suffered strokes that destroyed both his left and right parietal lobes. Although many aspects of his visual function were intact, he had severe problems attending to spatially distinct objects. When presented with stimuli such as those in Figure 4.15, R.M. perceived an abnormally large number of illusory conjunctions, even when he was given as long as 10 seconds to look at the displays (Friedman-
THE REAL WORLD: Multitasking
By one estimate, using a cell phone while driving makes having an accident four times more likely (McEvoy et al., 2005). In response to highway safety experts and statistics such as this, provincial and territorial legislatures are passing laws that restrict, and sometimes ban, using mobile phones while driving. You might think that is a fine idea … for everyone else on the road. But surely you can manage to punch in a number on a phone, carry on a conversation, or maybe even text-
The issue here is selective attention, or perceiving only what is currently relevant to you. Perception is an active, moment-
This kind of multitasking creates problems when you need to react suddenly while driving. Researchers have tested experienced drivers in a highly realistic driving simulator, measuring their response times to brake lights and stop signs while they listened to the radio or carried on phone conversations about a political issue, among other tasks (Strayer, Drews, & Johnston, 2003). These experienced drivers reacted significantly more slowly during phone conversations than during the other tasks. This is because a phone conversation requires memory retrieval, deliberation, and planning, and often carries an emotional stake in the conversation topic. Tasks such as listening to the radio require far less attention.
The tested drivers became so engaged in their conversations that their minds no longer seemed to be in the car. Their slower braking response translated into an increased stopping distance that, depending on the driver’s speed, would have resulted in a rear-
Interestingly, people who report that they multitask frequently in everyday life have difficulty in laboratory tasks that require focusing attention in the face of distractions compared with individuals who do not multitask much in daily life (Ophir, Nass, & Wagner, 2009). So how well do we multitask in a couple of tonnes of metal hurtling down the highway? Not very much—
4.3.2 Recognizing Objects by Sight
Take a quick look at the letters in the illustration below. Even though they are quite different from one another, you probably effortlessly recognized them as all being examples of the letter G. Now consider the same kind of demonstration using your best friend’s face. Suppose one day your friend gets a dramatic new haircut—
This thought exercise may seem trivial, but it is no small perceptual feat. If the visual system were somehow stumped each time a minor variation occurred in an object being perceived, the inefficiency of it all would be overwhelming. We would have to process information effortfully just to perceive our friend as the same person from one meeting to another, not to mention labouring through the process of knowing when a G is really a G. In general, though, object recognition proceeds fairly smoothly, in large part due to the operation of the feature detectors we discussed earlier.
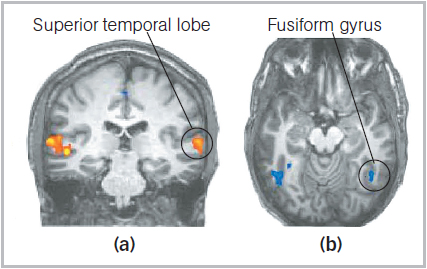
How do feature detectors help the visual system get from a spatial array of light hitting the eye to the accurate perception of an object in different circumstances, such as your friend’s face? Some researchers argue for a modular view, that specialized brain areas, or modules, detect and represent faces or houses or even body parts. Using fMRI to examine visual processing in healthy young adults, researchers found a sub-
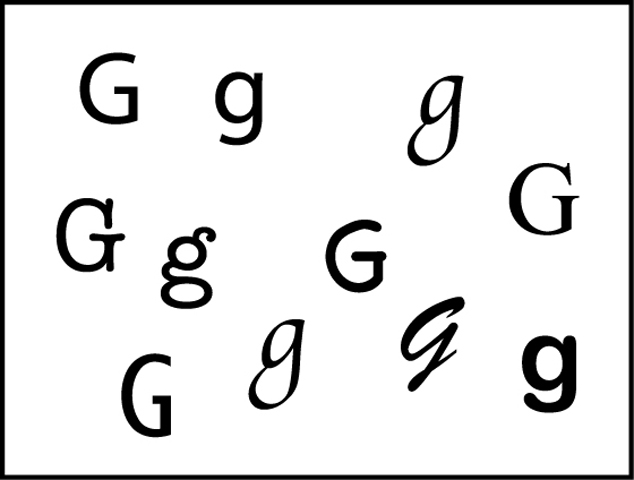
Another perspective on this issue is provided by experiments designed to measure precisely where seizures originate; these experiments have also provided insights on how single neurons in the human brain respond to objects and faces (Suthana & Fried, 2012). For example, in a study by Quiroga and his colleagues (2005), electrodes were placed in the temporal lobes of people who suffer from epilepsy. Then the volunteers were shown photographs of faces and objects as the researchers recorded their neural responses. The researchers found that neurons in the temporal lobe respond to specific objects viewed from multiple angles and to people wearing different clothing and facial expressions and photographed from various angles. In some cases, the neurons also respond to the words for these same objects. For example, neurons that responded to photographs of the Sydney Opera House also responded when the words Sydney Opera were displayed, but not when the words Eiffel Tower were displayed.
How do we recognize our friends, even when they are hidden behind sunglasses?
Taken together, these experiments demonstrate the principle of perceptual constancy: Even as aspects of sensory signals change, perception remains consistent. Recall our discussion of difference thresholds early in this chapter. Our perceptual systems are sensitive to relative differences in changing stimulation and make allowances for varying sensory input. This general principle helps explain why you still recognize your friend despite changes in hair colour or style or the addition of facial jewellery. It is not as though your visual perceptual system responds to a change with, “Here’s a new and unfamiliar face to perceive.” Rather, it is as though it responds with, “Interesting … here’s a deviation from the way this face usually looks.” Perception is sensitive to changes in stimuli, but perceptual constancies allow us to notice the differences in the first place.

4.3.2.1 Principles of Perceptual Organization
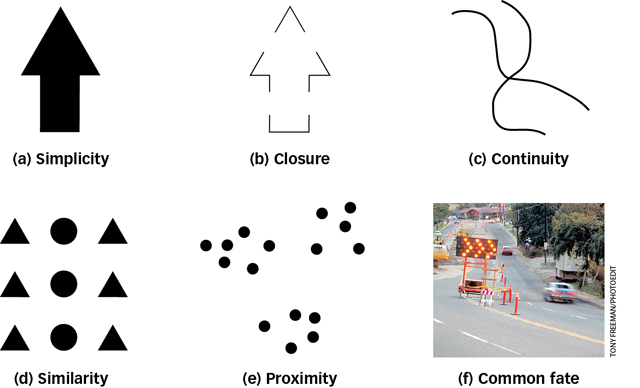
Before object recognition can even kick in, the visual system must perform another important task: grouping the image regions that belong together into a representation of an object. The idea that we tend to perceive a unified, whole object rather than a collection of separate parts is the foundation of Gestalt psychology, which you read about in the Psychology: Evolution of a Science chapter. Gestalt principles characterize many aspects of human perception. Among the foremost are the Gestalt perceptual grouping rules, which govern how the features and regions of things fit together (Koffka, 1935). Here’s a sampling (see FIGURE 4.16):
Simplicity: A basic rule in science is that the simplest explanation is usually the best so, when confronted with two or more possible interpretations of an object’s shape, the visual system tends to select the simplest or most likely interpretation. In FIGURE 4.16a we see an arrow.
Closure: We tend to fill in missing elements of a visual scene, allowing us to perceive edges that are separated by gaps as belonging to complete objects. In FIGURE 4.16b we see an arrow despite the gaps.
Continuity: Edges or contours that have the same orientation have what the Gestalt psychologists called good continuation, and we tend to group them together perceptually. In FIGURE 4.16c we perceive two crossing lines instead of two V shapes.
Similarity: Regions that are similar in colour, lightness, shape, or texture are perceived as belonging to the same object. In FIGURE 4.16d we perceive three columns—
a column of circles flanked by two columns of triangles. Proximity: Objects that are close together tend to be grouped together. In FIGURE 4.16e we perceive three groups or “clumps” of 5 or 6 dots each, not just 16 dots.
Common fate: Elements of a visual image that move together are perceived as parts of a single moving object. In FIGURE 4.16f the series of flashing lights in the road sign are perceived as a moving arrowhead.
4.3.2.2 Separating Figure from Ground

Perceptual grouping is a powerful aid to our ability to recognize objects by sight. Grouping involves visually separating an object from its surroundings. In Gestalt terms, this means identifying a figure apart from the (back)ground in which it resides. For example, the words on this page are perceived as figural: They stand out from the ground of the sheet of paper on which they are printed. Similarly, your instructor is perceived as the figure against the backdrop of all the other elements in your classroom. You certainly can perceive these elements differently, of course: The words and the paper are all part of a thing called a page, and your instructor and the classroom can all be perceived as your learning environment. Typically, though, our perceptual systems focus attention on some objects as distinct from their environments.
Size provides one clue to what is figure and what is ground: Smaller regions are likely to be figures, such as tiny letters on a big sheet of paper. Movement also helps: Your instructor is (we hope) a dynamic lecturer, moving around in a static environment. Another critical step toward object recognition is edge assignment. Given an edge, or boundary, between figure and ground, which region does that edge belong to? If the edge belongs to the figure, it helps define the object’s shape, and the background continues behind the edge. Sometimes, though, it is not easy to tell which is which.
Edgar Rubin (1886–
4.3.2.3 Theories of Object Recognition
Researchers have proposed two broad explanations of object recognition, one based on the object as a whole and the other on its parts.
What is an important difference between template and parts-
based theory of object recognition? According to image-
based object recognition theories, an object you have seen before is stored in memory as a template, a mental representation that can be directly compared to a viewed shape in the retinal image (Tarr & Vuong, 2002). Your memory compares its templates to the current retinal image and selects the template that most closely matches the current image (recall the different forms of the letter G seen earlier). Image-based theories are widely accepted, yet they do not explain everything about object recognition. For one thing, correctly matching images to templates suggests that you would have to have one template for cups in a normal orientation, another template for cups on their side, another for cups upside down, and so on. This makes for an unwieldy and inefficient system and therefore one that is unlikely to be effective, yet seeing a cup on its side rarely perplexes anyone for long. Page 150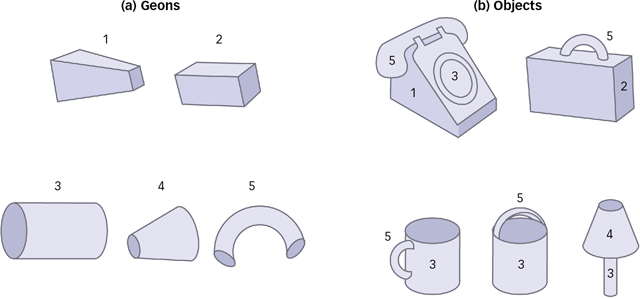
 Figure 4.18: An Alphabet of Geometric Elements Parts-
Figure 4.18: An Alphabet of Geometric Elements Parts-based theory holds that objects such as those shown in (b) are made up of simpler 3- D components called geons, shown in (a), much as letters combine to form different words. Parts-
based object recognition theories propose instead that the brain deconstructs viewed objects into a collection of parts (Marr & Nishihara, 1978). One important parts-based theory contends that objects are stored in memory as structural descriptions: mental inventories of object parts along with the spatial relations among those parts (Biederman, 1987). The parts inventories act as a sort of “alphabet” of geometric elements called geons that can be combined to make objects, just as letters are combined to form words (see FIGURE 4.18). Parts- based object recognition does not require a template for every view of every object, and so avoids some of the pitfalls of image- based theories. But parts- based object recognition does have major limitations. Most importantly, it allows for object recognition only at the level of categories and not at the level of the individual object. Parts- based theories offer an explanation for recognizing an object such as a face, for example, but are less effective at explaining how you distinguish between your best friend’s face and a stranger’s face.
Each set of theories has strengths and weaknesses, making object recognition an active area of study in psychology. Researchers are developing hybrid theories that attempt to exploit the strengths of each approach (Peissig & Tarr, 2007).
4.3.3 Perceiving Depth and Size
Objects in the world are arranged in three dimensions—
4.3.3.1 Monocular Depth Cues
Monocular depth cues are aspects of a scene that yield information about depth when viewed with only one eye. These cues rely on the relationship between distance and size. Even with one eye closed, the retinal image of an object you are focused on grows smaller as that object moves farther away, and larger as it moves closer. Our brains routinely use these differences in retinal image size, or relative size, to perceive distance.
This works particularly well in a monocular depth cue called familiar size. Most adults, for example, fall within a familiar range of heights (perhaps 1.5–

In addition to relative size and familiar size, there are several more monocular depth cues, such as those shown in FIGURE 4.20.
Linear perspective, which describes the phenomenon that parallel lines seem to converge as they recede into the distance (see FIGURE 4.20a).
Texture gradient, which arises when you view a more or less uniformly patterned surface because the size of the pattern elements, as well as the distance between them, grows smaller as the surface recedes from the observer (see FIGURE 4.20b).
Interposition, which occurs when one object partly blocks another (see FIGURE 4.20c). You can infer that the blocking object is closer than the blocked object. However, interposition by itself cannot provide information about how far apart the two objects are.
Page 151Relative height in the image depends on your field of vision (see FIGURE 4.20d). Objects that are closer to you are lower in your visual field, whereas faraway objects are higher.

4.3.3.2 Binocular Depth Cues

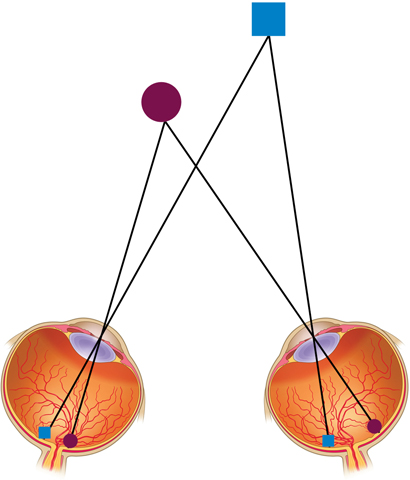
We can also obtain depth information through binocular disparity, the difference in the retinal images of the two eyes that provides information about depth. Because our eyes are slightly separated, each registers a slightly different view of the world. Your brain computes the disparity between the two retinal images to perceive how far away objects are, as shown in FIGURE 4.21. Viewed from above in the figure, the images of the more distant square and the closer circle each fall at different points on each retina.
Binocular disparity as a cue to depth perception was first discussed by Sir Charles Wheatstone in 1838. Wheatstone went on to invent the stereoscope, essentially a holder for a pair of photographs or drawings taken from two horizontally displaced locations. (Wheatstone did not lack for original ideas; he also invented the accordion and an early telegraph and coined the term microphone.) When viewed, one by each eye, the pairs of images evoked a vivid sense of depth. The View-
4.3.3.3 Illusions of Depth and Size
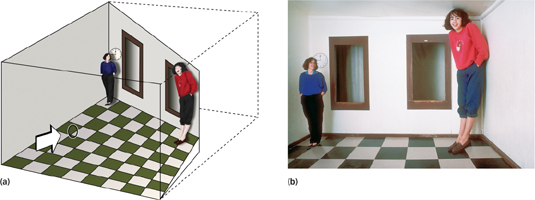
We all are vulnerable to illusions, which, as you will remember from the Psychology: Evolution of a Science chapter, are errors of perception, memory, or judgment in which subjective experience differs from objective reality (Wade, 2005). The relation between size and distance has been used to create elaborate illusions that depend on fooling the visual system about how far away objects are. All these illusions depend on the same principle: When you view two objects that project the same retinal image size, the object you perceive as farther away will be perceived as larger. One of the most famous illusions is the Ames room, constructed by the American ophthalmologist Adelbert Ames in 1946. The room is trapezoidal in shape rather than square: Only two sides are parallel (see FIGURE 4.22a). A person standing in one corner of an Ames room is physically twice as far away from the viewer as a person standing in the other corner. But when viewed with one eye through the small peephole placed in one wall, the Ames room looks square because the shapes of the windows and the flooring tiles are carefully crafted to look square from the viewing port (Ittelson, 1952).
The visual system perceives the far wall as perpendicular to the line of sight so that people standing at different positions along that wall appear to be at the same distance, and the viewer’s judgments of their sizes are based directly on retinal image size. As a result, a person standing in the right corner appears to be much larger than a person standing in the left corner (see FIGURE 4.22b).
4.3.4 Perceiving Motion and Change
You should now have a good sense of how we see what and where objects are, a process made substantially easier when the objects stay in one place. But real life, of course, is full of moving targets. Objects change position over time: Birds fly and horses gallop; rain and snow fall; and trees bend in the wind. Understanding how we perceive motion and why we sometimes fail to perceive change can bring us closer to appreciating how visual perception works in everyday life.
4.3.4.1 Motion Perception
To sense motion, the visual system must encode information about both space and time. The simplest case to consider is an observer who does not move trying to perceive an object that does.
As an object moves across an observer’s stationary visual field, it first stimulates one location on the retina, and then a little later it stimulates another location on the retina. Neural circuits in the brain can detect this change in position over time and respond to specific speeds and directions of motion (Emerson, Bergen, & Adelson, 1992). A region in the middle of the temporal lobe referred to as MT (part of the dorsal stream we discussed earlier) is specialized for the visual perception of motion (Born & Bradley, 2005; Newsome & Paré, 1988), and brain damage in this area leads to a deficit in normal motion perception (Zihl, von Cramon, & Mai, 1983).
Of course, in the real world, rarely are you a stationary observer. As you move around, your head and eyes move all the time, and motion perception is not as simple. The motion-

Motion perception, like colour perception, operates in part on opponent processes and is subject to sensory adaptation. A motion aftereffect called the waterfall illusion is analogous to colour aftereffects. If you stare at the downward rush of a waterfall for several seconds, you will experience an upward motion aftereffect when you then look at stationary objects near the waterfall such as trees or rocks. What is going on here?
The process is similar to seeing green after staring at a patch of red. Motion-
How can flashing lights on a traffic sign give the impression of movement?
The movement of objects in the world is not the only event that can evoke the perception of motion. The successively flashing lights of a traffic diversion sign can evoke a strong sense of motion because people perceive a series of flashing lights as a whole, moving object (see Figure 4.16f). This perception of movement as a result of alternating signals appearing in rapid succession in different locations is called apparent motion.
Video technology and animation depend on apparent motion. Motion pictures flash 24 still frames per second (fps). A slower rate would produce a much choppier sense of motion; a faster rate would be a waste of resources because we would not perceive the motion as any smoother than it appears at 24 fps.
4.3.4.2 Change Blindness and Inattentional Blindness
Motion involves a change in an object’s position over time, but objects in the visual environment can change in ways that do not involve motion (Rensink, 2002). You might walk by the same clothing store window every day and notice when a new suit or dress is on display or register surprise when you see a friend’s new haircut. Intuitively, we feel that we can easily detect changes to our visual environment. However, our comfortable intuitions have been challenged by experimental demonstrations of change blindness, which occurs when people fail to detect changes to the visual details of a scene (Rensink, 2002; Simons & Rensink, 2005). Strikingly, change blindness occurs even when major details of a scene are changed—
It is one thing to create change blindness by splicing a film, but does change blindness also occur in live interactions? Another study tested this idea by having an experimenter ask a person on a university campus for directions (Simons & Levin, 1998). While they were talking, two men walked between them holding a door that hid a second experimenter (see FIGURE 4.23). Behind the door, the two experimenters traded places, so that when the men carrying the door moved on, a different person was asking for directions than the one who had been there just a second or two earlier. Remarkably, only 7 of 15 participants reported noticing this change.
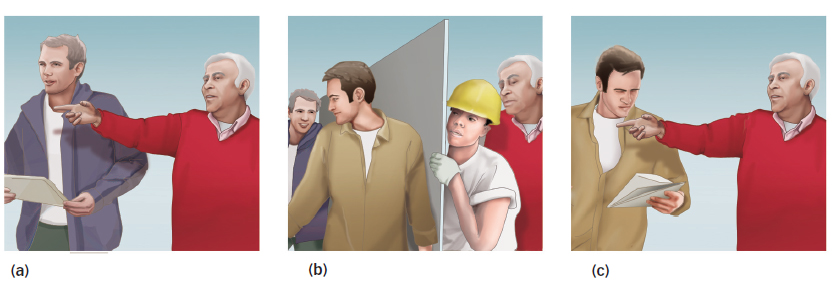
Simons, D. J., & Levin, D. T. (1998). Failure to detect changes to people during a real-
How can a failure of focused attention explain change blindness?
Although it is surprising that people can be blind to such dramatic changes, these findings once again illustrate the importance of focused attention for visual perception (see the discussion of feature-integration theory). Just as focused attention is critical for binding together the features of objects, it is also necessary for detecting changes to objects and scenes (Rensink, 2002; Simons & Rensink, 2005). Change blindness is most likely to occur when people fail to focus attention on the changed object (even though the object is registered by the visual system) and is least likely to occur for items that draw attention to themselves (Rensink, O’Regan, & Clark, 1997).

The role of focused attention in conscious visual experience is also dramatically illustrated by the closely related phenomenon of inattentional blindness, a failure to perceive objects that are not the focus of attention. Imagine the following scenario. You are watching a circle of people passing around a basketball, somebody dressed in a gorilla costume walks through the circle, and the gorilla stops to beat his chest before moving on. It seems inconceivable that you would fail to notice the gorilla, right? Think again. Simons and Chabris (1999) filmed such a scene, using two teams of three players each who passed the ball to one another as the costumed gorilla made his entrance and exit. Participants watched the film and were asked to track the movement of the ball by counting the number of passes made by one of the teams. With their attention focused on the moving ball, approximately half the participants failed to notice the chest-
This has interesting implications for a world in which many of us are busy texting and talking on our cell phones while carrying on other kinds of everyday business. We have already seen that using cell phones has negative effects on driving (see The Real World: Multitasking). Ira Hyman and colleagues (2010) asked whether cell phone use contributes to inattentional blindness in everyday life. They recruited a clown to ride a unicycle around a large square in the middle of Western Washington University campus. On a pleasant afternoon, the researchers asked 151 students who had just walked through the square whether they saw the clown. Seventy-
OTHER VOICES: Hallucinations and the Visual System
We rely on our perceptual systems to provide reliable information about the world around us. Yet we have already seen that perception is prone to various kinds of illusions. Even more striking, our perceptual systems are capable of creating hallucinations: perceptions of sights, sounds, or other sensory experiences that do not exist in the world outside us. As discussed by the perceptual psychologist V. S. Ramachandran in an interview with the New York Times, reported in an article written by Susan Kruglinski, vivid visual hallucinations can even occur in low vision or even blind individuals with severe damage to their retinas.
One day a few years ago, Doris Stowens saw the monsters from Maurice Sendak’s “Where the Wild Things Are” stomping into her bedroom. Then the creatures morphed into traditional Thai dancers with long brass fingernails, whose furious dance took them from the floor to the walls to the ceiling.
Although shocked to witness such a spectacle, Ms. Stowens, 85, was aware that she was having hallucinations, and she was certain that they had something to do with the fact that she suffered from the eye disease macular degeneration.
“I knew instantly that something was going on between my brain and my eyes,” she said.
Ms. Stowens says that ever since she developed partial vision loss, she has been seeing pink walls and early American quilts floating through the blind spots in her eyes several times each week.
In fact, Ms. Stowens’s hallucinations are a result of Charles Bonnet syndrome, a strange but relatively common disorder found in people who have vision problems. Because the overwhelming majority of people with vision problems are more than 70 years old, the syndrome, named after its eighteenth-
“It is not a rare disorder,” said Dr. V. S. Ramachandran, a neurologist at the University of California at San Diego, who has written about the syndrome. “It’s quite common. It’s just that people don’t want to talk about it when they have it.”
Researchers estimate that 10 to 15 percent of people whose eyesight is worse than 20/60 develop the disorder. Any eye disease that causes blind spots or low vision can be the source, including cataracts, glaucoma, diabetic retinopathy and, most commonly, macular degeneration. The hallucinations can vary from simple patches of color or patterns to lifelike images of people or landscapes to phantasms straight out of dreams. The hallucinations are usually brief and nonthreatening, and people who have the syndrome usually understand that what they are seeing is not real….
In some ways, researchers say, the hallucinations that define the syndrome are similar to the phenomenon of phantom limbs, where patients still vividly feel limbs that have been amputated, or phantom hearing, where a person hears music or other sounds while going deaf. In all three cases, the perceptions are caused by a loss of the sensory information that normally flows unceasingly into the brain.
In the case of sight, the primary visual cortex is responsible for taking in information, and also for forming remembered or imagined images. This dual function, Dr. Ramachandran and other experts say, suggests that normal vision is in fact a fusion of incoming sensory information with internally generated sensory input, the brain filling in the visual field with what it is used to seeing or expects to see. If you expect the person sitting next to you to be wearing a blue shirt, for example, you might, in a quick sideways glance, mistakenly perceive a red shirt as blue. A more direct gaze allows for more external information to correct the misperception.
“In a sense, we are all hallucinating all the time,” Dr. Ramachandran said. “What we call normal vision is our selecting the hallucination that best fits reality.”
With extensive vision loss, less external information is available to adjust and guide the brain’s tendency to fill in sensory gaps. The results may be Thai dancers or monsters from a children’s book….
Charles Bonnet syndrome was first described over 250 years ago by Bonnet, a Swiss scientist whose own blind grandfather experienced hallucinations like those reported by Ms. Stowens. However, neurologists and others have only recently begun to study the syndrome. Can you make some sense of this syndrome based on what you have learned about the visual system? How can someone who sees poorly or cannot see at all have intense visual experiences? What brain processes could be responsible for these kinds of visual hallucinations? Some clues come from neuroimaging studies of people who experience visual hallucinations, which have shown that specific types of hallucinations are accompanied by activity in parts of the brain responsible for the particular content of the hallucinations (Allen et al., 2008). For example, facial hallucinations are accompanied by activity in a part of the temporal lobe known to be involved in face processing. Our understanding of the visual system beyond the retina can provide some insight into how and why blind individuals experience visual hallucinations.
From the New York Times, September 14, 2004 © 2004 The New York Times. All rights reserved. Used by permission and protected by the Copyright Laws of the United States. The printing, copying, redistribution, or retransmission of this Content without express written permission is prohibited. http:/
CULTURE & COMMUNITY: Does Culture Influence Change Blindness?
The experiments discussed in this section of the chapter show that change blindness is dramatic and occurs across a range of situations. But the evidence for change blindness that we have considered comes from studies using participants from Western cultures, mainly Americans. Would change blindness occur in individuals from other cultures? If so, is there any reason to suspect that it would work differently across cultures? Think back to the Culture & Community box from the Psychology: Evolution of a Science chapter, where we discussed evidence showing that people from Western cultures rely on an analytic style of processing information (i.e., they tend to focus on an object without paying much attention to the surrounding context), whereas people from Eastern cultures tend to adopt a holistic style (i.e., they tend to focus on the relationship between an object and the surrounding context) (Kitayama et al., 2003; Nisbett & Miyamoto, 2005).
With this distinction in mind, Masuda and Nisbett (2006) noted that previous studies of change blindness, using mainly American participants, had shown that participants are more likely to detect changes in the main or focal object in a scene, and less likely to detect changes in surrounding context. They hypothesized that individuals from an Eastern culture would be more focused on, and therefore likely to notice, changes in surrounding context than individuals from a Western culture. To test their prediction, they conducted three experiments examining change detection in American (University of Michigan) and Japanese (Kyoto University) university students using still photographs and brief movie-
The results of the experiments were consistent with predictions: Japanese students detected more changes to contextual information than did American students, whereas American students detected more changes to focal objects than did Japanese students. These findings extend earlier reports that people from Eastern and Western cultures see the world differently, with Easterners focusing more on the context in which an object appears and Westerners focusing more on the object itself.
Illusory conjunctions occur when features from separate objects are mistakenly combined. According to feature-
integration theory, attention provides the glue necessary to bind features together. The parietal lobe is important for attention and contributes to feature binding. Some regions in the occipital and temporal lobes respond selectively to specific object categories, supporting the modular view that specialized brain areas represent particular classes of objects such as faces, houses, or body parts.
The principle of perceptual constancy holds that even as sensory signals change, perception remains consistent. Gestalt principles of perceptual grouping, such as simplicity, closure, and continuity, govern how the features and regions of things fit together.
Image-
based and parts- based theories each explain some, but not all, features of object recognition. Depth perception depends on: monocular cues, such as familiar size and linear perspective; binocular cues, such as retinal disparity; and motion-
based cues, which are based on the movement of the head over time. We experience a sense of motion through the differences in the strengths of output from motion-
sensitive neurons. These processes can give rise to illusions such as apparent motion. Change blindness and inattentional blindness occur when we fail to notice visible and even salient features of our environment, emphasizing that our conscious visual experience depends on focused attention.