4.3 Vision II: Recognizing What We Perceive
Our journey into the visual system has already revealed how it accomplishes some pretty astonishing feats. But the system needs to do much more in order for us to be able to interact effectively with our visual worlds. Let’s now consider how the system links together individual visual features into whole objects, allows us to recognize what those objects are, organizes objects into visual scenes, and detects motion and change in those scenes. Along the way, we’ll see that studying visual errors and illusions provides key insights into how these processes work.
Attention: The “Glue” That Binds Individual Features into a Whole
Specialized feature detectors in different parts of the visual system analyze each of the multiple features of a visible object: orientation, color, size, shape, and so forth. But how are different features combined into single, unified objects? What allows us to perceive that the young man in the photo is wearing a red shirt and the young woman is wearing a yellow shirt? Why don’t we see free-
binding problem
How features are linked together so that we see unified objects in our visual world rather than free-
Illusory Conjunctions: Perceptual Mistakes

In everyday life, we correctly combine features into unified objects so automatically and effortlessly that it may be difficult to appreciate that binding is ever a problem at all. However, researchers have discovered errors in binding that reveal important clues about how the process works. One such error is known as an illusory conjunction, a perceptual mistake where features from multiple objects are incorrectly combined. In one study, researchers briefly showed participants visual displays in which black digits flanked colored letters, such as a red A and a blue X, then instructed participants first to report the black digits and second to describe the colored letters (Triesman & Schmidt, 1982). Participants frequently reported illusory conjunctions, claiming to have seen, for example, a blue A or a red X (see FIGURE 4.13a and b). These illusory conjunctions were not just the result of guessing; they occurred more frequently than other kinds of errors, such as reporting a letter or color that was not present in the display (see FIGURE 4.13c).
illusory conjunction
A perceptual mistake where features from multiple objects are incorrectly combined.
110
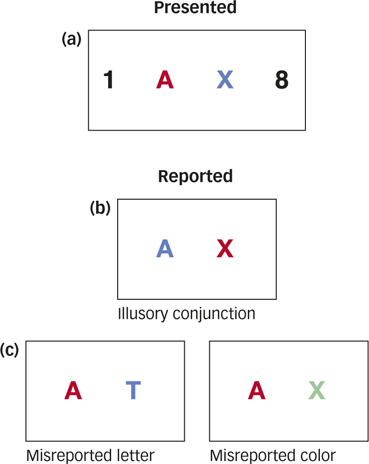
How does the study of illusory conjunctions help us understand the role of attention in feature binding?
Why do illusory conjunctions occur? Psychologist Anne Treisman and her colleagues proposed a feature-integration theory (Treisman, 1998, 2006; Treisman & Gelade, 1980; Treisman & Schmidt, 1982), which holds that focused attention is not required to detect the individual features that comprise a stimulus, such as the color, shape, size, and location of letters, but it is required to bind those individual features together. From this perspective, attention provides the “glue” necessary to bind features together, and illusory conjunctions occur when it is difficult for participants to pay full attention to the features that need to be glued together. For example, in the experiments we just considered, participants were first required to name the black digits, thereby reducing attention to the colored letters and allowing illusory conjunctions to occur. When experimental conditions are changed so that participants can pay full attention to the colored letters and they are able to correctly bind their features together, illusory conjunctions disappear (Treisman, 1998; Treisman & Schmidt, 1982).
feature-integration theory
The idea that focused attention is not required to detect the individual features that comprise a stimulus, but is required to bind those individual features together.
The Role of the Parietal Lobe
The binding process makes use of feature information processed by structures within the ventral visual stream, the “what” pathway (Seymour et al., 2010; see FIGURE 4.12). But because binding involves linking together features that appear at a particular spatial location, it also depends critically on the parietal lobe in the dorsal stream, the “where” pathway (Robertson, 1999). For example, Treisman and others studied R.M., who had suffered strokes that destroyed both his left and right parietal lobes. Although many aspects of his visual function were intact, he had severe problems attending to spatially distinct objects. When presented with stimuli such as those in FIGURE 4.13, R.M. perceived an abnormally large number of illusory conjunctions, even when he was given as long as 10 seconds to look at the displays (Friedman-
Recognizing Objects by Sight
Take a quick look at the letters in the accompanying illustration. Even though they’re quite different from one another, you probably effortlessly recognized them as all being examples of the letter G. Now consider the same kind of demonstration using your best friend’s face. Suppose one day your friend gets a dramatic new haircut—
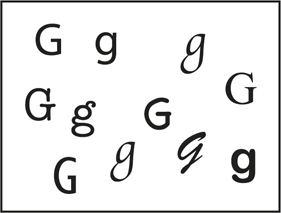
This thought exercise may seem trivial, but it’s no small perceptual feat. If the visual system were somehow stumped each time a minor variation occurred in an object, the inefficiency of it all would be overwhelming. We’d have to process information effortfully just to perceive our friend as the same person from one meeting to another, not to mention laboring through the process of knowing when a G is really a G. In general, though, object recognition proceeds fairly smoothly, in large part due to the operation of the feature detectors we discussed earlier.
111
How do feature detectors help the visual system accurately perceive an object in different circumstances, such as your friend’s face? Some researchers argue for a modular view—namely, that specialized brain areas, or modules, detect and represent faces or houses or even body parts. Using fMRI to examine visual processing in healthy young adults, researchers found a subregion in the temporal lobe that responds most strongly to faces compared to just about any other object category, whereas a nearby area responds most strongly to buildings and landscapes (Kanwisher, McDermott, & Chun, 1997). This view suggests we have not only feature detectors to aid in visual perception but also “face detectors,” “building detectors,” and possibly other types of neurons specialized for particular types of object perception (Downing et al., 2006; Kanwisher & Yovel, 2006). Other researchers argue for a more distributed representation of object categories. In this view, it is the pattern of activity across multiple brain regions that identifies any viewed object, including faces (Haxby et al., 2001). Each of these views explains some data better than the other one, and researchers continue to debate their relative merits.
How do we recognize our friends, even when they’re hidden behind sunglasses?

Warner Bros./The Kobal Collection/Art Resource
Principles of Perceptual Organization
Before object recognition can even kick in, the visual system must perform another important task: grouping the image regions that belong together into a representation of an object. The idea that we tend to perceive a unified, whole object rather than a collection of separate parts is the foundation of Gestalt psychology, which you read about in Chapter 1. Gestalt perceptual grouping rules govern how the features and regions of things fit together (Koffka, 1935). Here’s a sampling:
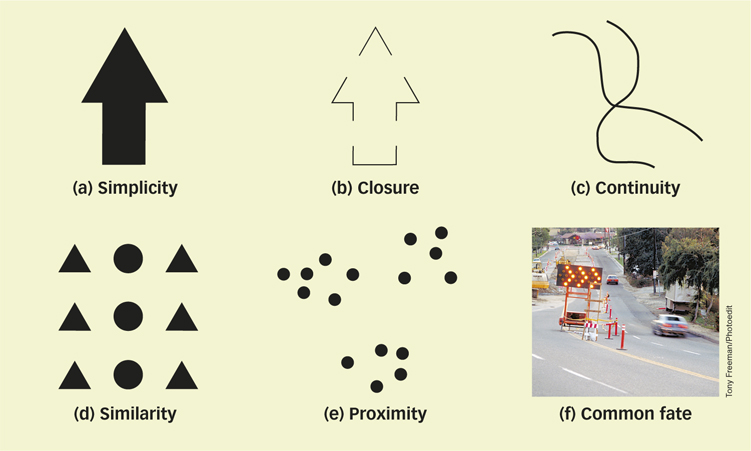
- Simplicity: When confronted with two or more possible interpretations of an object’s shape, the visual system tends to select the simplest or most likely interpretation. In FIGURE 4.14a, we see an arrow, rather than two separate shapes: a triangle sitting on top of a rectangle.
- Closure: We tend to fill in missing elements of a visual scene, allowing us to perceive edges that are separated by gaps as belonging to complete objects. In FIGURE 4.14b, we see an arrow despite the gaps.
- Continuity: When edges or contours have the same orientation, we tend to group them together perceptually. In FIGURE 4.14c, we perceive two (continuous) crossing lines instead of two V shapes.
- Similarity: Regions that are similar in color, lightness, shape, or texture are perceived as belonging to the same object. In FIGURE 4.14d, we perceive three columns—
a column of circles flanked by two columns of triangles— instead of three rows of mixed shapes. - Proximity: Objects that are close together tend to be grouped together. In FIGURE 4.14e, we perceive three groups or “clumps” of 5 or 6 dots each, not just 16 dots.
- Common fate: Elements of a visual image that move together are perceived as parts of a single moving object. In FIGURE 4.14f, the series of flashing lights in the road sign are perceived as a moving arrowhead.
112
Separating Figure from Ground

Perceptual grouping involves visually separating an object from its surroundings. In Gestalt terms, this means identifying a figure apart from the (back)ground in which it resides. For example, the words on this page are perceived as figural: They stand out from the ground of the sheet of paper on which they’re printed. Similarly, your instructor is perceived as the figure against the backdrop of all the other elements in your classroom. You certainly can perceive these elements differently, of course: The words and the paper are all part of a thing called a page, and your instructor and the classroom can all be perceived as your learning environment. Typically, though, our perceptual systems focus attention on some objects as distinct from their environments.
Size provides one clue to what’s figure and what’s ground: Smaller regions are likely to be figures, such as tiny letters on a big sheet of paper. Movement also helps: Your instructor is (we hope) a dynamic lecturer, moving around in a static environment. Another critical step toward object recognition is edge assignment. Given an edge, or boundary, between figure and ground, which region does that edge belong to? If the edge belongs to the figure, it helps define the object’s shape, and the background continues behind the edge. Sometimes, though, it’s not easy to tell which is which.
Edgar Rubin (1886–
113
Perceiving Depth and Size
Objects in the world are arranged in three dimensions—
Monocular Depth Cues
Monocular depth cues are aspects of a scene that yield information about depth when viewed with only one eye. These cues rely on the relationship between distance and size. Even when you have one eye closed, the retinal image of an object you’re focused on grows smaller as that object moves farther away and larger as it moves closer. Our brains routinely use these differences in retinal image size, or relative size, to perceive distance. Most adults, for example, fall within a familiar range of heights (perhaps 5-

monocular depth cues
Aspects of a scene that yield information about depth when viewed with only one eye.
In addition to relative size, there are several more monocular depth cues, such as

Age Fotostock/Superstock
Altrendo/Getty Images
Rob Blakers/Getty Images
- Linear perspective, the phenomenon that parallel lines seem to converge as they recede into the distance (see FIGURE 4.17a).
- Texture gradient, the fact that the size of the elements on a patterned surface grows smaller as the surface recedes from the observer (see FIGURE 4.17b).
- Interposition, the fact that when one object partly blocks another (see FIGURE 4.17c), you can infer that the blocking object is closer than the blocked object.
- Relative height in the image, the fact that objects that are closer to you are lower in your visual field, whereas faraway objects are higher (see FIGURE 4.17d).
114
Binocular Depth Cues
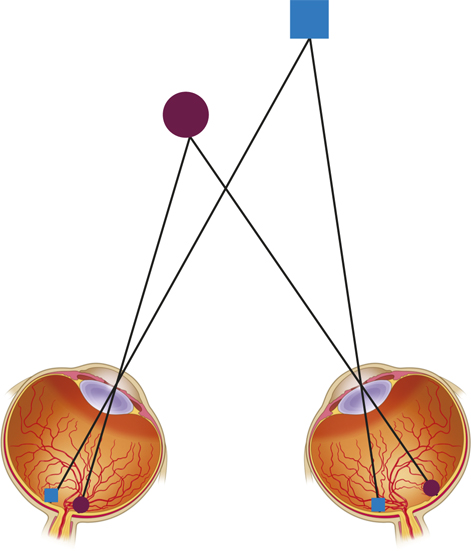
We can also obtain depth information through binocular disparity, the difference in the retinal images of the two eyes that provides information about depth. Because our eyes are slightly separated, each registers a slightly different view of the world. Your brain computes the disparity between the two retinal images to perceive how far away objects are, as shown in FIGURE 4.18. Viewed from above in the figure, the images of the more distant square and the closer circle each fall at different points on each retina. The View-

© Nmpft/Sspl/The Image Works
binocular disparity
The difference in the retinal images of the two eyes that provides information about depth.
Illusions of Depth and Size
We all are vulnerable to illusions, which, as you’ll remember from the Psychology: Evolution of a Science chapter, are errors of perception, memory, or judgment in which subjective experience differs from objective reality (Wade, 2005). A famous illusion that makes use of a variety of depth cues is the Ames room, which is trapezoidal in shape rather than square (see FIGURE 4.19a). A person standing in one corner of an Ames room is physically twice as far away from the viewer as a person standing in the other corner. But when viewed with one eye through the small peephole placed in one wall, the Ames room looks square because the shapes of the windows and the flooring tiles are carefully crafted to look square from the viewing port (Ittelson, 1952). The visual system perceives the far wall as perpendicular to the line of sight so that people standing at different positions along that wall appear to be at the same distance, and the viewer’s judgments of their sizes are based directly on retinal image size. As a result, a person standing in the right corner appears to be much larger than a person standing in the left corner (see FIGURE 4.19b).
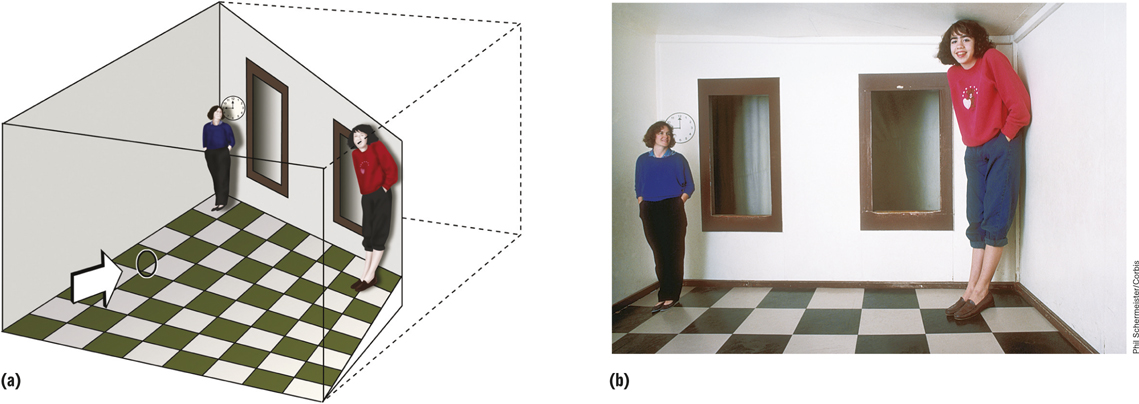
115
Perceiving Motion and Change
You should now have a good sense of how we see what and where objects are, a process made substantially easier when the objects stay in one place. But real life, of course, is full of moving targets. Birds fly, horses gallop, and trees bend in the wind. Understanding how we perceive motion and why we sometimes fail to perceive change can bring us closer to appreciating how visual perception works in everyday life.
Motion Perception
To sense motion, the visual system must encode information about both space and time. The simplest case to consider is an observer who does not move trying to perceive an object that does.
As an object moves across an observer’s stationary visual field, it first stimulates one location on the retina, and then a little later it stimulates another location on the retina. Neural circuits in the brain can detect this change in position over time and respond to specific speeds and directions of motion (Emerson, Bergen, & Adelson, 1992). A region in the middle of the temporal lobe referred to as MT (part of the dorsal stream we discussed earlier) is specialized for the visual perception of motion (Born & Bradley, 2005; Newsome & Paré, 1988), and brain damage in this area leads to a deficit in normal motion perception (Zihl, von Cramon, & Mai, 1983).
Of course, in the real world, rarely are you a stationary observer. As you move around, your head and eyes move all the time. The motion-
How can flashing lights on a casino sign give the impression of movement?
The movement of objects in the world is not the only event that can evoke the perception of motion. The successively flashing lights of a Las Vegas casino sign can evoke a strong sense of motion because people perceive a series of flashing lights as a whole, moving object (see again FIGURE 4.15f). This perception of movement as a result of alternating signals appearing in rapid succession in different locations is called apparent motion. Video technology and animation depend on apparent motion. Motion pictures flash 24 frames per second (fps). A slower rate would produce a much choppier sense of motion; a faster rate would be a waste of resources because we would not perceive the motion as any smoother than it appears at 24 fps.
apparent motion
The perception of movement as a result of alternating signals appearing in rapid succession in different locations.
116
Change Blindness and Inattentional Blindness
Motion involves a change in an object’s position over time, but objects in the visual environment can change in ways that do not involve motion (Rensink, 2002). You might walk by the same clothing store window every day and notice when a new suit or dress is on display. Intuitively, we feel that we can easily detect changes to our visual environment. However, our comfortable intuitions have been challenged by experimental demonstrations of change blindness, which occurs when people fail to detect changes to the visual details of a scene (Rensink, 2002; Simons & Rensink, 2005). One study tested this idea by having an experimenter ask a person on a college campus for directions (Simons & Levin, 1998). While they were talking, two men walked between them holding a door that hid a second experimenter (see FIGURE 4.20). Behind the door, the two experimenters traded places so that when the men carrying the door moved on, a different person was asking for directions than the one who had been there just a second or two earlier. Remarkably, only 7 of 15 participants reported noticing this change.

change blindness
When people fail to detect changes to the visual details of a scene.
Although surprising, these findings once again illustrate the importance of focused attention for visual perception. Just as focused attention is critical for binding together the features of objects, it is also necessary for detecting changes to objects and scenes (Rensink, 2002; Simons & Rensink, 2005). Change blindness is most likely to occur when people fail to focus attention on the changed object (even though the object is registered by the visual system) and is least likely to occur for items that draw attention to themselves (Rensink, O’Regan, & Clark, 1997).
How can a failure of focused attention explain change blindness?
The role of focused attention in conscious visual experience is also dramatically illustrated by the closely related phenomenon of inattentional blindness, a failure to perceive objects that are not the focus of attention. We’ve already seen that using cell phones has negative effects on driving (see The Real World: Multitasking). In another study, researchers asked whether cell phone use contributes to inattentional blindness in everyday life (Hyman et al., 2010). They recruited a clown to ride a unicycle in the middle of a large square in the middle of the campus at Western Washington University. On a pleasant afternoon, the researchers asked 151 students who had just walked through the square whether they saw the clown. Seventy-
inattentional blindness
A failure to perceive objects that are not the focus of attention.

117
Culture & Community: Does culture influence change blindness?
Does culture influence change blindness? The evidence for change blindness that we’ve considered in this chapter comes from studies using participants from Western cultures, mainly Americans. Would change blindness occur in individuals from other cultures? Think back to the Culture & Community box from the Psychology: Evolution of a Science chapter, where we discussed evidence showing that people from Western cultures rely on an analytic style of processing information (i.e., they tend to focus on an object without paying much attention to the surrounding context), whereas people from Eastern cultures tend to adopt a holistic style (i.e., they tend to focus on the relationship between an object and the surrounding context: Kitayama et al., 2003; Nisbett & Miyamoto, 2005).
With this distinction in mind, Masuda and Nisbett (2006) noted that previous studies of change blindness, using mainly American participants, had shown that participants are more likely to detect changes in the main or focal object in a scene, and less likely to detect changes in surrounding context. The researchers hypothesized that individuals from an Eastern culture would be more focused on—
The results of the experiments were consistent with predictions: Japanese students detected more changes to contextual information than did American students, whereas American students detected more changes to focal objects than did Japanese students. These findings extend earlier reports that people from Eastern and Western cultures see the world differently, with Easterners focusing more on the context in which an object appears and Westerners focusing more on the object itself.
SUMMARY QUIZ [4.3]
Question 4.7
| 1. | Our ability to visually combine details so that we perceive unified objects is explained by |
- feature-
integration theory. - illusory conjunction.
- synesthesia.
- ventral and dorsal streaming.
a.
Question 4.8
| 2. | The idea that specialized brain areas represent particular classes of objects is |
- the modular view.
- attentional processing.
- distributed representation.
- neuron response.
a.
Question 4.9
| 3. | What kind of cues are relative height and linear perspective? |
- motion-
based - binocular
- monocular
- template
c.
118