The double helix is stabilized by hydrogen bonds and van der Waals interactions
The ability of nucleic acids to form specific base pairs was discovered in the course of studies directed at determining the three-dimensional structure of DNA. Maurice Wilkins and Rosalind Franklin obtained x-ray diffraction photographs of fibers of DNA (Figure 4.10). The characteristics of these diffraction patterns indicated that DNA is formed of two strands that wind in a regular helical structure. From these data and others, James Watson and Francis Crick deduced a structural model for DNA that accounted for the diffraction pattern and was the source of some remarkable insights into the functional properties of nucleic acids (Figure 4.11).
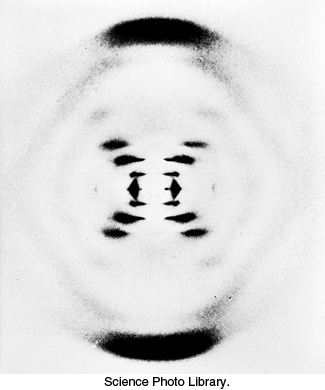
FIGURE 4.10X-ray diffraction photograph of a hydrated DNA fiber. When crystals of a biomolecule are irradiated with x-rays, the x-rays are diffracted and these diffracted x-rays are seen as a series of spots, called reflections, on a screen behind the crystal. The structure of the molecule can be determined by the pattern of the reflections (Section 3.5). In regard to DNA crystals, the central cross is diagnostic of a helical structure. The strong arcs on the meridian arise from the stack of nucleotide bases, which are 3.4 Å apart.
[Science Photo Library.]
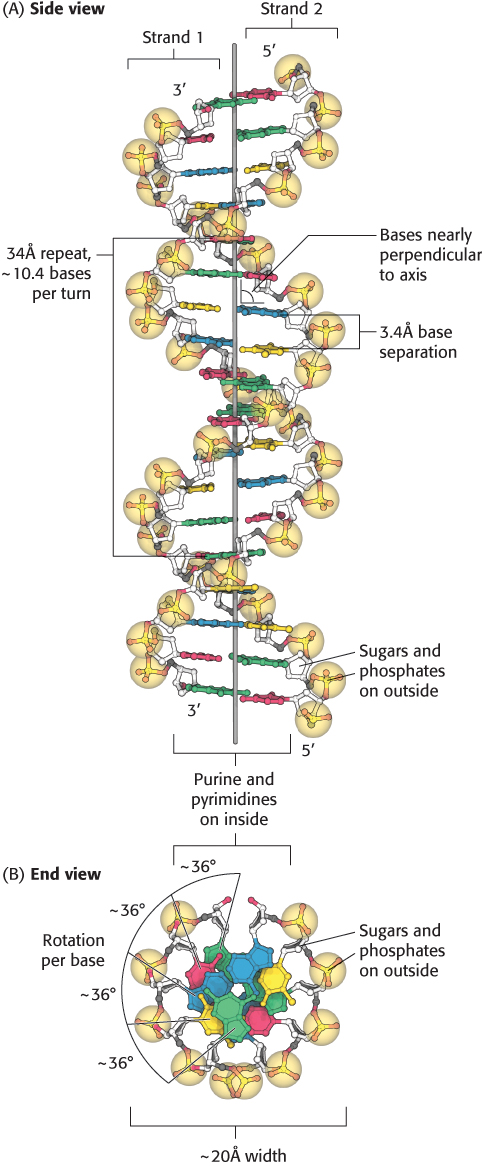
FIGURE 4.11Watson–Crick model of double-helical DNA. (A) Side view. Adjacent bases are separated by 3.4 Å. The structure repeats along the helical axis (vertical) at intervals of 34 Å, which corresponds to approximately 10 nucleotides on each chain. (B) Axial view, looking down the helix axis, reveals a rotation of 36° per base and shows that the bases are stacked on top of one another
[Source: J. L. Tymoczko, J. Berg, and L. Stryer, Biochemistry: A Short Course, 2nd ed. (W. H. Freeman and Company, 2013), Fig. 33.11.].
The features of the Watson–Crick model of DNA deduced from the diffraction patterns are:
1. Two helical polynucleotide strands are coiled around a common axis with a right-handed screw sense. The strands are antiparallel, meaning that they have opposite directionality.
2. The sugar–phosphate backbones are on the outside and the purine and pyrimidine bases lie on the inside of the helix.
3. The bases are nearly perpendicular to the helix axis, and adjacent bases are separated by approximately 3.4 Å. The helical structure repeats on the order of every 34 Å, with about 10.4 bases per turn of helix. There is a rotation of nearly 36 degrees per base (360 degrees per full turn/10.4 bases per turn).
4. The diameter of the helix is about 20 Å.
How is such a regular structure able to accommodate an arbitrary sequence of bases, given the different sizes and shapes of the purines and pyrimidines? In attempting to answer this question, Watson and Crick discovered that guanine can be paired with cytosine and adenine with thymine to form base pairs that have essentially the same shape (Figure 4.12). These base pairs are held together by specific hydrogen bonds, which, although weak (4–21 kJ mol−1, or 1–5 kcal mol−1), stabilize the helix because of their large numbers in a DNA molecule. These base-pairing rules account for the observation, originally made by Erwin Chargaff in 1950, that the ratios of adenine to thymine and of guanine to cytosine are nearly the same in all species studied, whereas the adenine-to-guanine ratio varies considerably (Table 4.1).
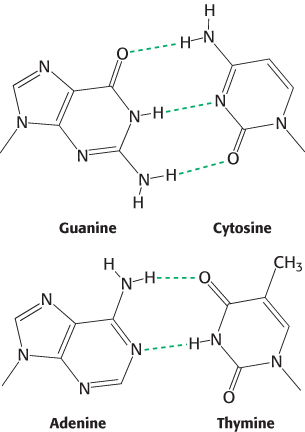
FIGURE 4.12Structures of the base pairs proposed by Watson and Crick.
TABLE 4.1 Base compositions experimentally determined for a variety of organisms
Inside the helix, the bases are essentially stacked one on top of another (Figure 4.11B). The stacking of base pairs contributes to the stability of the double helix in two ways. First, the formation of the double helix is facilitated by the hydrophobic effect. The hydrophobic bases cluster in the interior of the helix away from the surrounding water, whereas the more polar surfaces are exposed to water. This arrangement is reminiscent of protein folding, where hydrophobic amino acids are in the protein’s interior and the hydrophilic amino acids are on the exterior (Section 2.4). Second, the stacked base pairs attract one another through van der Waals forces, appropriately referred to as stacking forces, further contributing to stabilization of the helix (Figure 4.13). The energy associated with a single van der Waals interaction is quite small, typically from 2 to 4 kJ mol−1 (0.5–1.0 kcal mol−1). In the double helix, however, a large number of atoms are in van der Waals contact, and the net effect, summed over these atom pairs, is substantial. In addition, base stacking in DNA is favored by the conformations of the somewhat rigid five-membered rings of the backbone sugars.
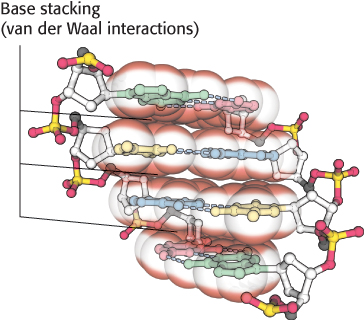
FIGURE 4.13A side view of DNA. Base pairs are stacked nearly one on top of another in the double helix. The stacked bases interact with van der Waals forces. Such stacking forces help stabilize the double helix.
[Source: J. L. Tymoczko, J. Berg, and L. Stryer, Biochemistry: A Short Course, 2nd ed. (W. H. Freeman and Company, 2013), Fig. 33.13.].
DNA can assume a variety of structural forms
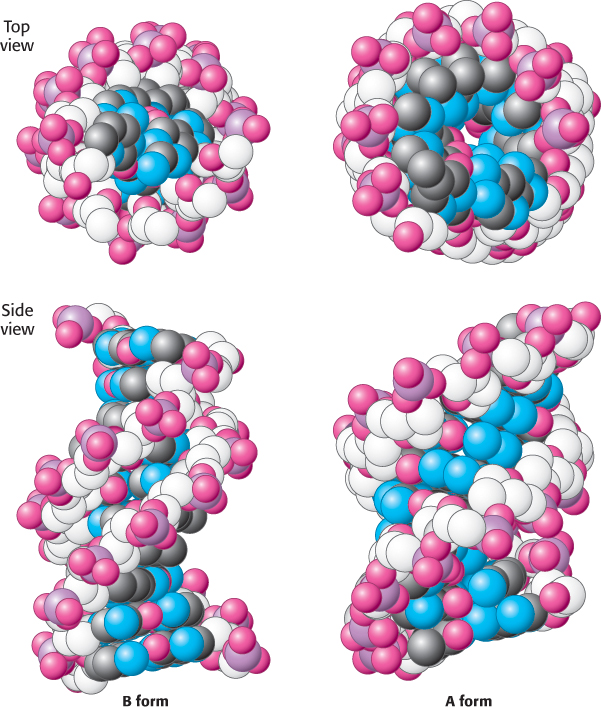
 FIGURE 4.14 B-form and A-form DNA. Space-filling models of 10 base pairs of B-form and A-form DNA depict their right-handed helical structures. Notice that the B-form helix is longer and narrower than the A-form helix. The carbon atoms of the backbone are shown in white.
FIGURE 4.14 B-form and A-form DNA. Space-filling models of 10 base pairs of B-form and A-form DNA depict their right-handed helical structures. Notice that the B-form helix is longer and narrower than the A-form helix. The carbon atoms of the backbone are shown in white.
[Drawn from 1BNA.pdb and 1DNZ.pdb.]
Watson and Crick based their model (known as the B-DNA helix) on x-ray diffraction patterns of highly hydrated DNA fibers, which provided information about properties of the double helix that are averaged over its constituent residues. Under physiological conditions, most DNA is in the B form. X-ray diffraction studies of less-hydrated DNA fibers revealed a different form called A-DNA. Like B-DNA, A-DNA is a right-handed double helix made up of anti-parallel strands held together by Watson–Crick base-pairing. The A-form helix is wider and shorter than the B-form helix, and its base pairs are tilted rather than perpendicular to the helix axis (Figure 4.14).
If the A-form helix were simply a property of dehydrated DNA, it would be of little significance. However, double-stranded regions of RNA and at least some RNA–DNA hybrids adopt a double-helical form very similar to that of A-DNA. What is the biochemical basis for differences between the two forms of DNA? Many of the structural differences between B-DNA and A-DNA arise from different puckerings of their ribose units (Figure 4.15). In A-DNA, C-3′ lies out of the plane (a conformation referred to as C-3′ endo) formed by the other four atoms of the ring; in B-DNA, C-2′ lies out of the plane (a conformation called C-2′ endo). The C-3′-endo puckering in A-DNA leads to an 11-degree tilting of the base pairs away from perpendicular to the helix. RNA helices are further induced to take the A-DNA form because of steric hindrance from the 2′-hydroxyl group: the 2′-oxygen atom would be too close to three atoms of the adjoining phosphoryl group and to one atom in the next base. In an A-form helix, in contrast, the 2′-oxygen atom projects outward, away from other atoms. The phosphoryl and other groups in the A-form helix bind fewer H2O molecules than do those in B-DNA. Hence, dehydration favors the A form.
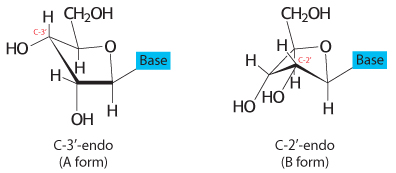
FIGURE 4.15Sugar pucker. In A-form DNA, the C-3′ carbon atom lies above the approximate plane defined by the four other sugar nonhydrogen atoms (called C-3′ endo). In B-form DNA, each deoxyribose is in a C-2′-endo conformation, in which C-2′ lies out of the plane.
Z-DNA is a left-handed double helix in which backbone phosphates zigzag
A third type of double helix is left-handed, in contrast with the right-handed screw sense of the A and B helices. Furthermore, the phosphoryl groups in the backbone are zigzagged; hence, this form of DNA is called Z-DNA (Figure 4.16).
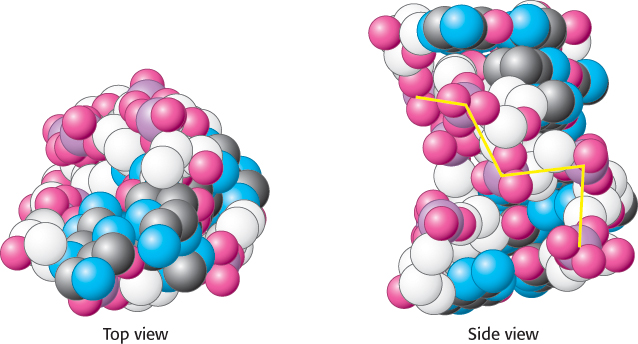
FIGURE 4.16 Z-DNA. DNA oligomers such as CGCGCG adopt an alternative conformation under some conditions. This conformation is called Z-DNA because the phosphoryl groups zigzag along the backbone.
[Drawn from 131D.pdb.]
Although the biological role of Z-DNA is still under investigation, Z-DNA-binding proteins have been isolated, one of which is required for viral pathogenesis of poxviruses, including variola, the agent of smallpox. The existence of Z-DNA shows that DNA is a flexible, dynamic molecule whose parameters are not as fixed as depictions suggest. The properties of A-, B-, and Z-DNA are compared in Table 4.2.
TABLE 4.2 Comparison of A-, B-, and Z-DNA
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Base pairs per turn of helix |
|
|
|
|
|
|
|
|
Tilt of base pairs from perpendicular to helix axis |
|
|
|
*Syn and anti refer to the orientation of the N-glycosidic bond between the base and deoxyribose. In the anti orientation, the base extends away from the deoxyribose. In the syn orientation, the base is above the deoxyribose. Pyrimidines can be in anti orientations only, whereas purines can be anti or syn. |
Some DNA molecules are circular and supercoiled
The DNA molecules in human chromosomes are linear. However, electron microscopic and other studies have shown that intact DNA molecules from bacteria and archaea are circular (Figure 4.17A). The term circular refers to the continuity of the DNA strands, not to their geometric form. DNA molecules inside cells necessarily have a very compact shape. Note that the E. coli chromosome, fully extended, would be about 1000 times as long as the greatest diameter of the bacterium.
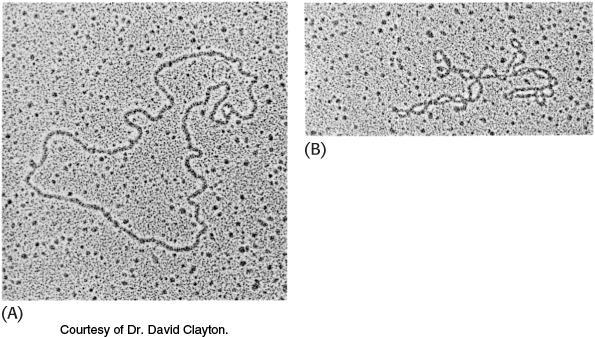
FIGURE 4.17Electron micrographs of circular DNA from mitochondria.
(A) Relaxed form. (B) Supercoiled form [Courtesy of Dr. David Clayton.]
A closed DNA molecule has a property unique to circular DNA. The axis of the double helix can itself be twisted or supercoiled into a superhelix (Figure 4.17B). A circular DNA molecule without any superhelical turns is known as a relaxed molecule. Supercoiling is biologically important for two reasons. First, a supercoiled DNA molecule is more compact than its relaxed counterpart. Second, supercoiling may hinder or favor the capacity of the double helix to unwind and thereby affect the interactions between DNA and other molecules. These topological features of DNA will be considered further in Chapter 28.
Single-stranded nucleic acids can adopt elaborate structures
Single-stranded nucleic acids often fold back on themselves to form well-defined structures. Such structures are especially prominent in RNA and RNA-containing complexes such as the ribosome—a large complex of RNAs and proteins on which proteins are synthesized.
The simplest and most-common structural motif formed is a stem-loop, created when two complementary sequences within a single strand come together to form double-helical structures (Figure 4.18). In many cases, these double helices are made up entirely of Watson–Crick base pairs. In other cases, however, the structures include mismatched base pairs or unmatched bases that bulge out from the helix. Such mismatches destabilize the local structure but introduce deviations from the standard double-helical structure that can be important for higher-order folding and for function (Figure 4.19).
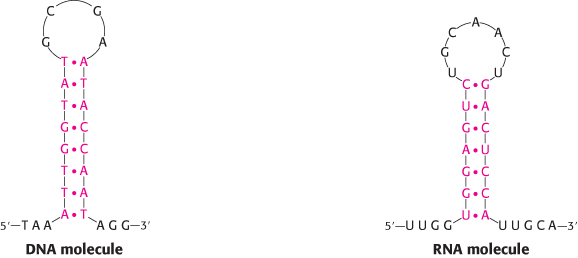
FIGURE 4.18Stem-loop structures. Stem-loop structures can be formed from single-stranded DNA and RNA molecules.
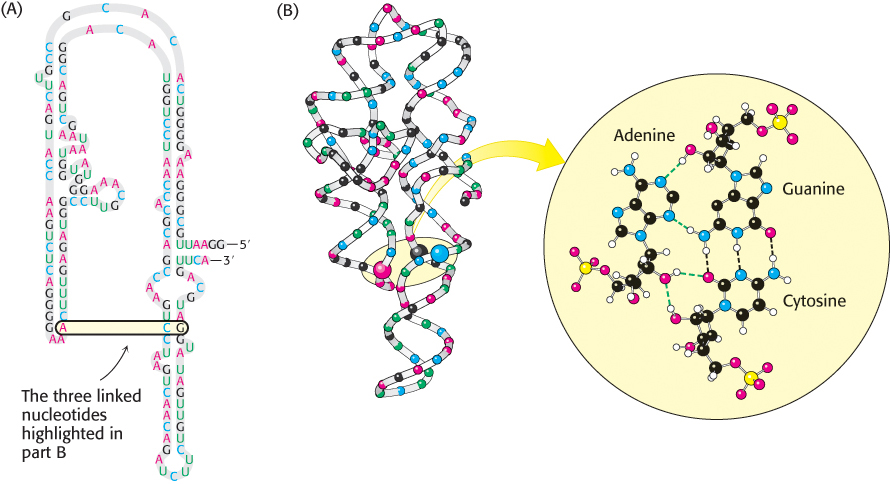
FIGURE 4.19Complex structure of an RNA molecule. A single-stranded RNA molecule can fold back on itself to form a complex structure. (A) The nucleotide sequence showing Watson–Crick base pairs and other nonstandard base pairings in stem-loop structures. (B) The three-dimensional structure and one important long-range interaction between three bases. In the three-dimensional structure at the left, cytidine nucleotides are shown in blue, adenosine in red, guanosine in black, and uridine in green. In the detailed projection, hydrogen bonds within the Watson–Crick base pair are shown as dashed black lines; additional hydrogen bonds are shown as dashed green lines.
Single-stranded nucleic acids can adopt structures that are more complex than simple stem-loops through the interaction of more widely separated bases. Often, three or more bases interact to stabilize these structures. In such cases, hydrogen-bond donors and acceptors that do not participate in Watson–Crick base pairs participate in hydrogen bonds to form nonstandard pairings. Metal ions such as magnesium ion (Mg2+) often assist in the stabilization of these more elaborate structures. These complex structures allow RNA to perform a host of functions that the double-stranded DNA molecule cannot. Indeed, the complexity of some RNA molecules rivals that of proteins, and these RNA molecules perform a number of functions that had formerly been thought the exclusive domain of proteins.