2.4 FOUNDATIONS OF MOLECULAR GENETICS
The union of genetics and cytology in the early 1900s was an exceedingly productive time. Heredity was based in genes, which were located on chromosomes. But what are genes made of? To some scientists, genes were almost unreal, a mental construct to explain real phenomena. We now know, of course, that genes are made of DNA. In fact, DNA was discovered decades before its significance was understood. The recognition of DNA as the genetic material, and the solution of its chemical and three-
DNA Is the Chemical of Heredity


Deoxyribonucleic acid (DNA), as we have noted, was identified long before its importance was recognized. The history begins with Friedrich Miescher, who carried out the first systematic chemical studies of cell nuclei in 1868. Miescher obtained white blood cells from pus that he collected from discarded surgical bandages. He carefully isolated the nuclei and then ruptured the nuclear membranes, releasing an acidic, phosphorus-
By the 1920s, the chemical basis of heredity was thought to lie in chromosomes, but chromosomes are composed of both DNA and protein. Which one is the hereditary chemical? DNA was initially ruled out because it was believed to be too simple—
44
DNA was shown to be the chemical of heredity in the 1940s, by Oswald T. Avery and his colleagues at the Rockefeller Institute in New York City. Their starting point was an observation made in 1928 by English microbiologist Frederick Griffith, who studied the pneumonia-
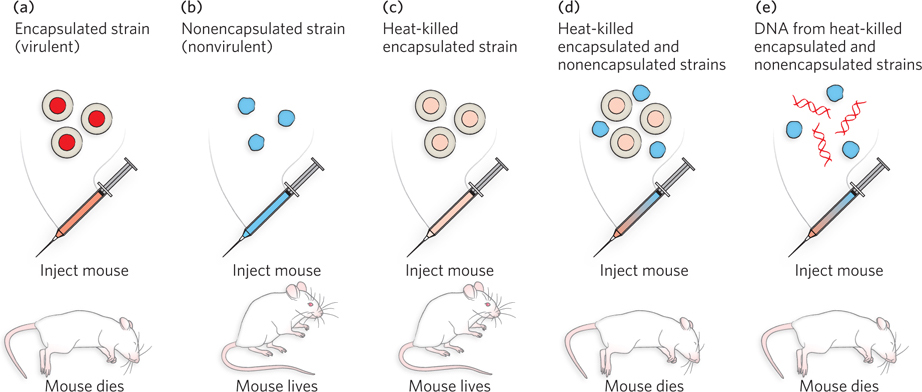
Avery and his colleagues reproduced Griffith’s results, and they analyzed the heat-
45
Genes Encode Polypeptides and Functional RNAs


DNA and protein are chemically very different, and it was puzzling how a DNA sequence could code for a protein sequence. Regardless of the details, however, it now became easy to understand that mutations in a gene could lead to altered enzymes. In fact, even before the DNA structure was solved, the relationship between genes, mutations, and enzymes was well understood.
In 1902, the physician Archibald Garrod studied patients with alkaptonuria, a disease of little consequence for the patients, except that they excreted urine that turned black. Mendel’s work had recently been rediscovered, and by noticing how alkaptonuria was inherited, Garrod realized that this disorder behaved as a recessive trait. It was already known that the synthesis and breakdown of biomolecules occur in multistep pathways, each step requiring a different enzyme—a protein catalyst that facilitates the reaction. Garrod hypothesized that alkaptonuria was caused by a mutation that inactivated a gene required for the production of one enzyme in a metabolic pathway. Without this functional enzyme, the pathway was blocked, resulting in the buildup of an intermediate compound, which was excreted in the urine and turned black. Garrod’s reasoning drew the connection between a mutation in a gene and a mutation in an enzyme.
Formal proof that genes encode enzymes came from a series of elegant experiments in the 1940s by George Beadle and Edward L. Tatum. They introduced a new microorganism into the study of genetics: the bread mold, Neurospora crassa (see the Model Organisms Appendix). This haploid organism can grow on a simple, defined medium, called minimal medium. Minimal medium contains sugar, nitrogen, inorganic salts, and biotin, and the cell must make all the rest of the biochemicals that it needs to live from these simple starting compounds. Beadle and Tatum irradiated Neurospora spores to intentionally produce mutations, then germinated individual spores on a complete medium (i.e., one made with cell extracts that have all the necessary amino acids, nucleotides, and vitamins) to obtain genetically pure colonies and their spores. These spores were then tested for their ability to germinate on the minimal medium. An inability to grow on minimal medium indicates a mutation in one of the metabolic pathways required for growth. These mutants are called auxotrophs. Spores of different auxotrophs were then analyzed for growth on a range of minimal media supplemented with selected compounds, to identify the defective metabolic pathways and the steps affected. An example of one such study is illustrated in Figure 2-23, for auxotrophs of arginine metabolism.
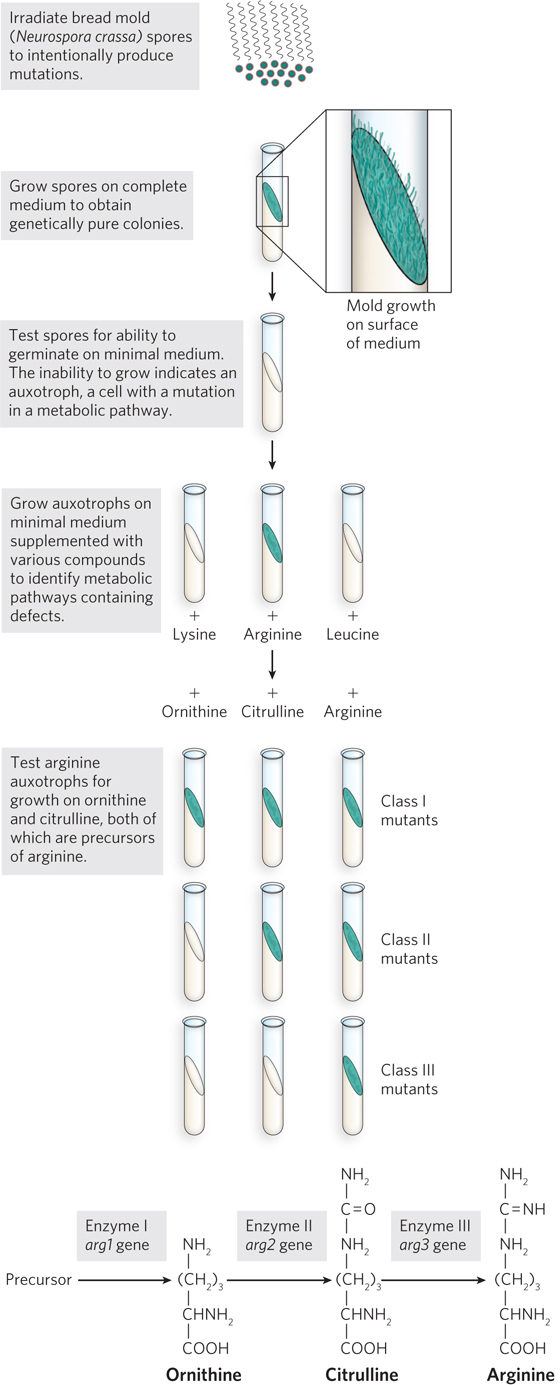
Beadle and Tatum had a collection of Neurospora mutants that were auxotrophic for the amino acid arginine. The arginine synthetic pathway was known to include the intermediate compounds ornithine and citrulline, so they tested their arginine auxotrophs for growth on minimal media containing ornithine, citrulline, or arginine. The arginine auxotrophs fell into three classes, depending on which intermediate(s) they required for growth (see Figure 2-23). Beadle and Tatum also mapped the mutant genes and found that mutants in a particular class of auxotrophs mapped to the same chromosomal location. They concluded that each class of mutant was caused by a single defective gene. Their findings also held true for genes in other metabolic pathways.
On the basis of these experiments, Beadle and Tatum proposed the one gene, one enzyme hypothesis, which stated that each gene codes for one enzyme. We now know that some enzymes are composed of multiple subunits encoded by different genes; furthermore, not all proteins are enzymes. So, the hypothesis was later revised to one gene, one polypeptide. A polypeptide is a chain of amino acids, and a functional protein can be composed of a single polypeptide or multiple polypeptide subunits. For a large number of genes, one gene, one polypeptide holds true. But as we will see throughout this textbook, even this hypothesis is not entirely accurate. Some genes code for functional RNAs rather than for protein. And through a process called alternative splicing (see Chapter 16), some genes code for more than one type of polypeptide.
46
The Central Dogma: Information Flows from DNA to RNA to Protein—Usually
Watson and Crick’s determination of DNA structure was a turning point in understanding how information flows in biological systems. Their model of DNA structure, which they reasoned from data collected by other scientists—
The double-
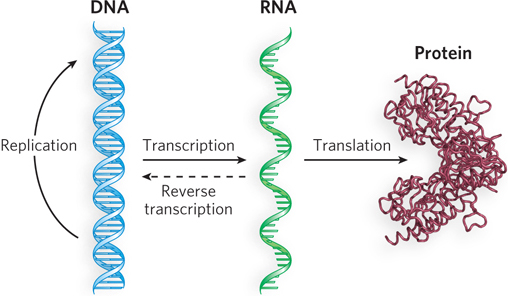
With discovery of the DNA structure, genetics could now be described in chemical terms. Both DNA and proteins are linear polymers, so the sequence of nucleotides in DNA must somehow be converted to a sequence of amino acids. But DNA is located in the nucleus, whereas proteins are synthesized in the cytoplasm. Therefore, there must be an intermediary molecule to shuttle information between the two locations. RNA was believed to play a role in this, and the similarities between DNA and RNA made it a simple matter to understand how an RNA molecule could be made from a DNA template. Crick proposed that biological information flows in the direction DNA→RNA→protein and that DNA acts as a template for its own synthesis (DNA→DNA) (Figure 2-24). Crick’s proposal is known as the central dogma of information flow.
47
Over the years, it has become obvious that the nice and tidy linear flow of information in Crick’s central dogma is not really all that simple after all. Several different paths of information flow are now known to exist. Among these different pathways are the ability of some enzymes to synthesize DNA from RNA (RNA→DNA) and the ability of some viruses to use RNA as a template to make more RNA (RNA→RNA). But the most profound change in what we know about information flow is the finding that the cell makes a huge amount of RNA that is not translated into protein, and it is not just tRNA and rRNA (whose functions we describe below). Indeed, much of the mammalian genome is transcribed into RNA that does not code for protein. We discuss this topic briefly at the end of this section.
RNA was widely expected to be the molecule that mediates the transfer of information from DNA in the nucleus to the site of protein synthesis in the cytoplasm. However, no one imagined that three different types of RNA would be required for the process.
Ribosomal RNA In the early 1950s, Paul Zamecnik and his colleagues identified the site of protein synthesis as particles in the cytoplasm called ribosomes. Ribosomes are large structures composed of both protein and RNA. The RNA component is called ribosomal RNA (rRNA). In bacteria and eukaryotes, ribosomes consist of a large subunit and a small subunit.
Messenger RNA The combined findings that ribosomes are the site of protein synthesis and that rRNA is the most abundant RNA (>80%) in the cell led most researchers to believe that rRNA was the carrier of information from DNA to protein. However, some features of rRNA are incompatible with its function as an information carrier. For example, rRNA is an integral part of the ribosome, so there would have to be specific ribosomes to make each specific protein. Further, the nucleotide composition of rRNAs from different organisms was relatively constant, whereas the nucleotide composition of chromosomal DNA varied considerably from one organism to the next.
Studies by Sydney Brenner, Jacques Monod, and Matthew Meselson in the early 1960s, using Escherichia coli (see the Model Organisms Appendix), suggested that another type of RNA carries the message from DNA to protein. They discovered a class of RNA that targets preexisting ribosomes, and the nucleotide composition of this RNA was more similar to chromosomal DNA than was rRNA. These properties are exactly those expected for a true messenger between DNA and protein. The investigators called this RNA messenger RNA (mRNA) and concluded that ribosomes are protein-
RNA synthesis is carried out by the enzyme RNA polymerase, which synthesizes RNA by reading one strand of the duplex DNA, pairing RNA bases to the bases in the DNA strand, to synthesize a single-
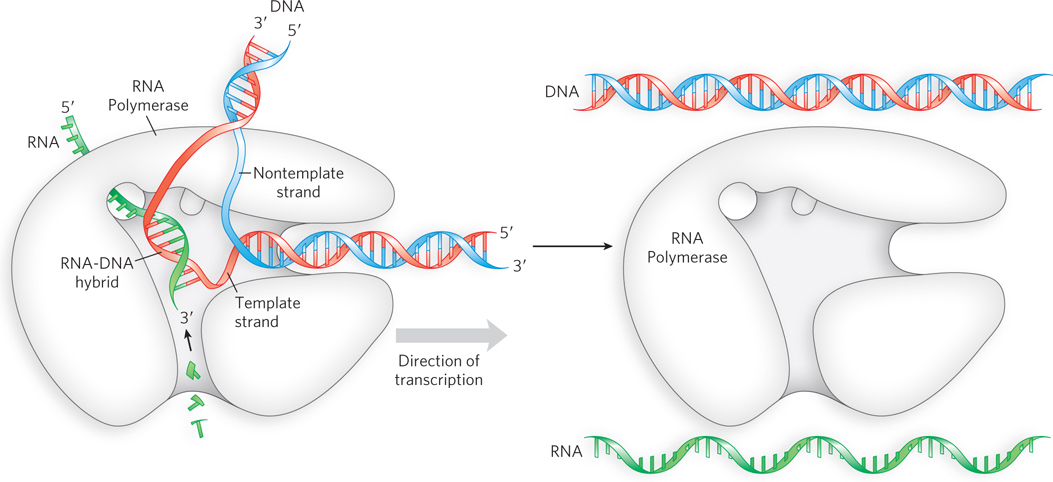
Transfer RNA The discovery of mRNA was a crucial piece of the information puzzle. But a problem remained: how is a sequence of nucleotides in mRNA converted to a sequence of amino acids in protein? Furthermore, DNA and RNA each consist of only four different nucleotides, whereas proteins have 20 different amino acids. Hence, one must assume the existence of a code that uses combinations of nucleotides to specify amino acids. Combinations of two nucleotides yield only 16 permutations (42). Combinations of three nucleotides yield 64 permutations (43), more than enough to specify a code for 20 amino acids.
In 1955, Crick hypothesized the existence of an adaptor molecule, perhaps a small RNA, that could read three nucleotides and also carry amino acids. It was not long after Crick’s adaptor hypothesis (see Chapter 17) that Paul Zamecnik and Mahlon Hoagland discovered a small RNA to which amino acids could attach. This small RNA, later called transfer RNA (tRNA), was the adaptor between nucleic acid and protein.
48
The discovery of tRNA, combined with the idea of a three-
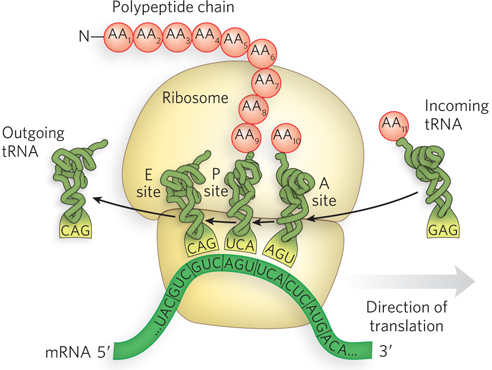
Functional RNAs All RNAs, whether they code for protein or not, are transcribed from DNA genes. Messenger RNA is needed only transiently, to instruct the synthesis of proteins. But the end products of tRNA and rRNA genes are the RNA molecules themselves. These functional RNAs fold into specific three-
49
There is an abundance of other functional RNAs besides tRNA and rRNA, some of which have known functions. For example, some small nuclear RNAs (<150 nucleotides) associate with protein to form ribonucleoprotein particles that process the introns from mRNAs (see Chapters 16 and 22). Other types of small RNA, the microRNAs (miRNA) and the short interfering RNAs (siRNA), have important gene regulatory functions. MicroRNAs anneal to particular mRNAs, usually causing their degradation and thereby effectively turning off, or silencing, the gene (see Chapter 22). Perhaps the most mysterious of the non-
There are yet other types of information flow, besides the use of RNAs, that fall outside the classic central dogma. Notable among these is the epigenetic control of gene regulation, based in specific chemical modifications of particular nucleotides and of the proteins that package DNA (in structures called nucleosomes). Combinations of these chemical changes can program the transcriptional control of a cell and can be inherited in cell divisions during an organism’s development (see Chapter 10). This epigenetic inheritance falls outside the domain of DNA sequence. There are also many other types of protein modifications that transduce the flow of information within the cell and from one cell to another. Suffice it to say that the new dogma is that there is no simple “central dogma.” The flow of information is so vital to life and evolution that it takes many forms, some hard to recognize, and scientists have no shortage of work ahead of them to elucidate these important mechanisms.
Mutations in DNA Give Rise to Phenotypic Change
Most cellular functions are carried out by proteins. The precise sequence of amino acids in each protein molecule and the specific rules governing the timing and quantity of its production are programmed into an organism’s DNA. When changes in the DNA sequence occur, cellular function can be altered. Mutations in DNA can be beneficial or harmful to an organism, or can have no effect at all. For example, if the mutation does not change the sequence of a protein or how the protein is regulated, the mutation has no effect and is said to be silent. Evolution depends on mutations that are beneficial, and these usually alter the sequence or regulation of a protein in a way that enhances its function or confers a new, beneficial function that increases the viability of the organism. However, most mutations that change a protein sequence are harmful, because they lead to altered proteins with decreased function or new, detrimental function, and give rise to various diseases. When these DNA mutations occur in germ-
Hemophilia afflicted the interrelated royal families of England, Russia, Spain, and Prussia in the 1800s. At the root of this malady is an inability of the blood to clot, resulting in excessive bleeding from even the slightest injury. The disease typically results in death at an early age. Tracing hemophilia through the royal families of Europe indicates that it originated with Queen Victoria (Figure 2-27a). It is interesting that none of the current family members are carriers, presumably the result of natural selection against this trait.
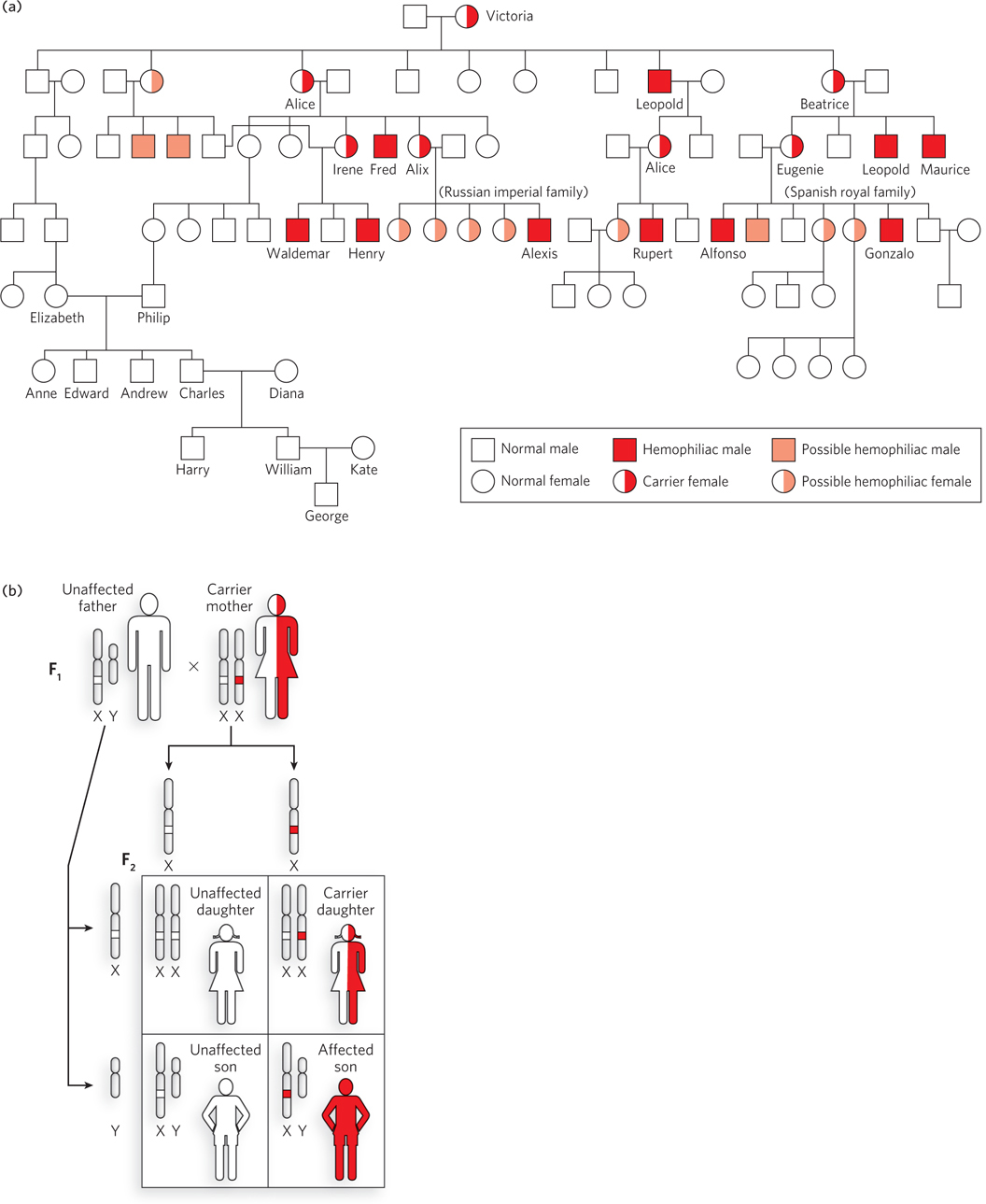
Hemophilia is about 10,000 times more common in males than in females. This is because the blood-
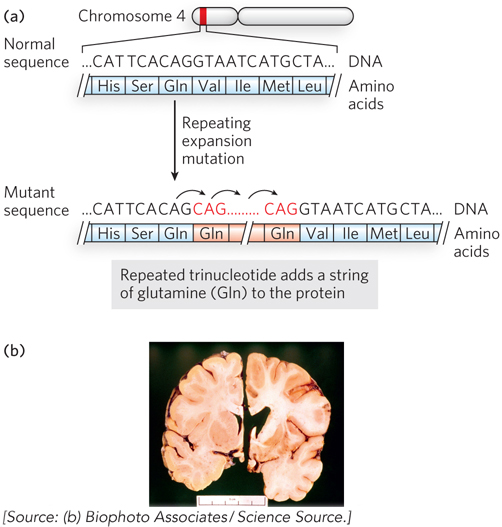
Many other inherited diseases have been mapped to their particular genes. One of the first to be identified was the gene involved in Huntington disease (Figure 2-28). The gene, HTT, is located on chromosome 4. The disease is associated with a region of the HTT gene that can have a variable number of repeats of the triplet nucleotide sequence CAG (encoding the amino acid glutamine). The HTT gene in healthy individuals has about 27 or fewer of these repeats, but when the number exceeds 36, it is often associated with disease. The likelihood of having Huntington disease increases with the number of trinucleotide repeats in the HTT gene. The function of the protein encoded by HTT is unknown, but the disease results in the degeneration of neurons in areas of the brain that affect motor coordination, memory, and cognitive function.
50
51
The number of triplet repeats in HTT can increase during gamete production, resulting in earlier onset and increased severity of the disease over successive generations. This is thought to occur by template slippage (the same segment of DNA replicated more than once) during DNA synthesis due to the repetitive nature of the sequence. Other diseases caused by “triplet expansion” of this type have now been identified. These include Kennedy disease, spinocerebellar ataxia, and Machado-
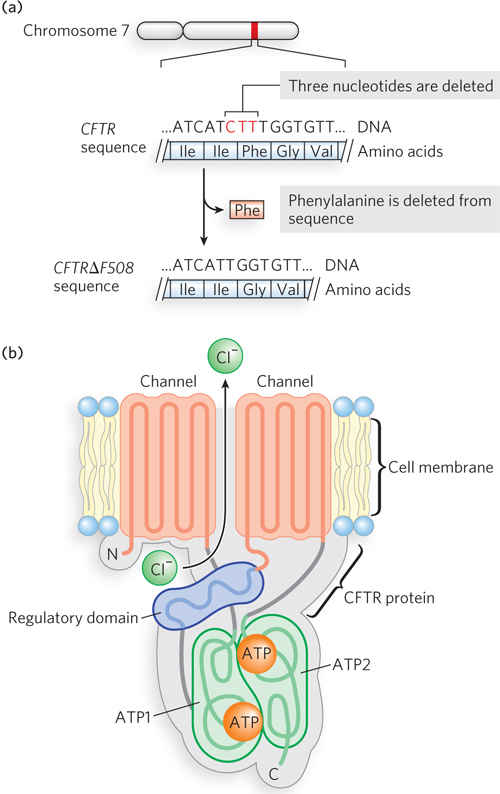
Cystic fibrosis is another genetic disease that has been identified at the molecular level. The gene (CFTR) is on chromosome 7 and encodes a chloride channel protein, the cystic fibrosis transmembrane conductance regulator (Mr 168,173). The protein contains five domains: two domains that span the cytoplasmic membrane for chloride transport; two domains that bind and use ATP, the energy that fuels transport of the chloride ions; and a regulatory domain (Figure 2-29). The most common mutation (occurring in about 60% of cases) is CFTRΔF508, in which three nucleotides are deleted (denoted by Δ), resulting in the deletion of phenylalanine (denoted by F) at position 508 in the amino acid sequence. This amino acid residue is located in the first of the ATP-
52
KEY CONVENTION
The molecular mass of a molecule is commonly expressed in one of two ways, and these are used interchangeably in this book. The first is molecular weight, also called relative molecular mass (Mr). The relative molecular mass of a molecule is the ratio of the mass of that molecule to one-
The ΔF508 mutation in CFTR is autosomal recessive, and therefore an individual must inherit two copies of the mutant allele to develop cystic fibrosis, one from each parent. Without functional CFTR chloride channels, individuals with cystic fibrosis develop abnormally high sweat and mucus production, and a major complication is the buildup of mucus in the lungs. Patients experience breathing difficulties and often have pneumonia. Individuals with cystic fibrosis have typically had an average life span of about 30 years, but as new treatments are developed, survival is increasing greatly.
Although many mutations are detrimental, other mutations can be beneficial. For example, the protein CCR5 is a coreceptor for HIV, the AIDS virus. There is much speculation about a 32 amino acid deletion mutation of CCR5 (due to the CCR5Δ32 mutation), which is widely dispersed among people of European descent (an occurrence of 5% to 14% in these groups), although much rarer among Asians and Africans. Researchers speculate that this mutation may have conferred resistance to the bubonic plague or smallpox, thereby becoming enriched in the population, by natural selection, in endemic areas. Although the allele has a negative effect on T-
HIGHLIGHT 2-1 MEDICINE: The Molecular Biology of Sickle-Cell Anemia, a Recessive Genetic Disease of Hemoglobin
Genetics, molecular biology, and evolution by natural selection all converge in a striking fashion in sickle-
Sickle-
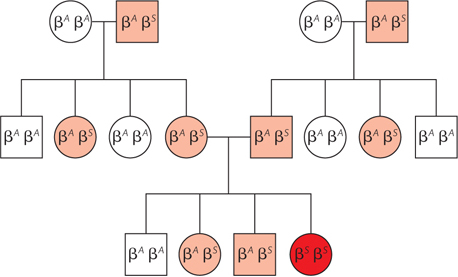
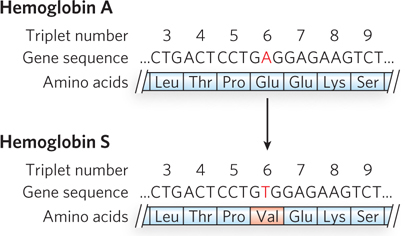
The nucleotide sequence of the sickle-
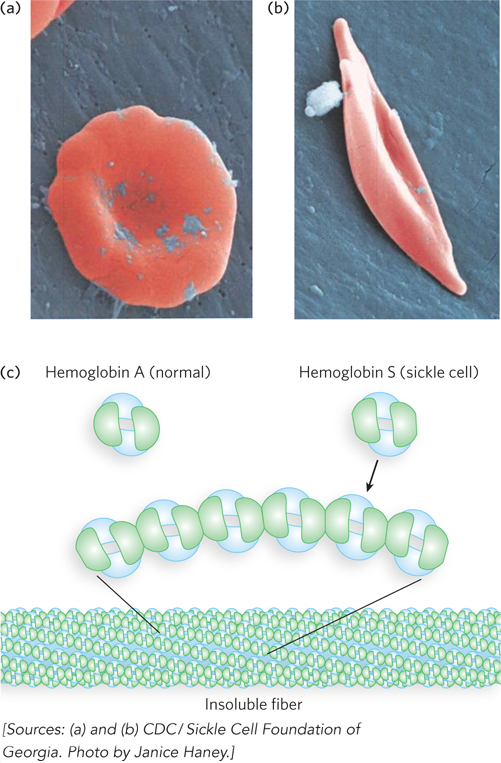
When capillaries become blocked, the condition is much more serious. Capillary blockage causes pain and interferes with organ function—
53
Another example of a mutation that confers some benefit is the one that causes sickle-
Discovery of DNA as the hereditary material, and the understanding of how it is transcribed and translated into RNA and protein, is a most fascinating story in science. Darwin’s theory of the origin of species through evolution by natural selection was compelling, but the mechanism that drove the variation on which natural selection could act remained a mystery in his lifetime. Yet, the key to understanding this mystery had already been discovered by Mendel. Mutations create the natural variation needed for the forces of natural selection to mold new species. It seems almost ludicrous that Mendel and Darwin were alive at the same time and separately uncovered secrets that together explained the diversity of planetary life. Lack of a robust means of communication kept these two vital pieces of information segregated for decades—
54
SECTION 2.4 SUMMARY
Nucleic acids (DNA and RNA) are composed of repeating units called nucleotides. Each nucleotide contains a phosphate group, a ribose sugar, and a nitrogenous base. Four different bases are found in DNA: adenine, guanine, cytosine, and thymine. RNA also contains adenine (A), guanine (G), and cytosine (C), but uracil (U) instead of thymine (T). Information is encoded by the specificity of pairing of G with C, and of A with T (or U).
Identification of DNA as the chemical of heredity was determined in experiments using virulent and nonvirulent bacteria. The DNA of virulent bacteria transforms nonvirulent bacteria into a virulent form.
Even before the DNA structure was solved, studies of mutants drew the connection between genes and enzymes, as in the investigations of defective enzymes in the biosynthetic pathways of auxotrophic mutants of Neurospora crassa.
Information flow in the direction DNA→RNA→protein is known as the central dogma. RNA is synthesized from a DNA template in the process of transcription. In translation, the RNA sequence is converted to protein. The duplication of DNA is replication. Exceptions to the central dogma exist (RNA→DNA, and RNA→RNA).
Three types of RNA are required for DNA→RNA→protein. Ribosomal RNA combines with proteins to form ribosomes, which are factories for protein synthesis. Transfer RNAs are small adaptor RNAs to which amino acids become attached. Messenger RNAs encode proteins and are read by tRNAs in groups of three nucleotides, each of which specifies an amino acid.
Functional RNAs are RNA sequences that are not translated into protein. Rather, the RNA sequences themselves perform functions in the cell. Both rRNA and tRNA are functional RNAs.
Mutations are changes in DNA sequence. When a mutation affects the function of a protein or functional RNA, it results in a phenotypic change. Changes in the DNA sequence of germ-
line cells underlie inherited human diseases, including hemophilia, Huntington disease, cystic fibrosis, and sickle- cell anemia. Mutations are not always deleterious— sometimes they can be beneficial and, indeed, are vital in creating the diversity needed for the evolution of new species.
55
Chromosome Pairs Segregate during Gamete Formation in a Way That Mirrors the Mendelian Behavior of Genes
Boveri, T. 1902. Ueber mehropolige Mitosen als Mittel zur Analyse des Zellkerns. Verh. Phys. Med. Ges. Wurzburg 35:67–
Sutton, W. S. 1902. On the morphology of the chromosome group in Brachystola magna. Biol. Bull. 4:24–
Sutton, W. S. 1903. The chromosomes in heredity. Biol. Bull. 4:231–

Walter Sutton was only a graduate student when, in 1902, he made observations that led to some of the most profound conclusions in biology. At the time of Sutton’s studies at Columbia University, Mendel’s laws had just been rediscovered by genetic methods similar to the ones used by Mendel 35 years earlier. But now there were new ways of looking at organisms—

The behavior of chromosomes mimicked the Mendelian behavior of segregation of traits, but on a subcellular level. Sutton hypothesized that paternal and maternal chromosomes exist in pairs and separate into gametes during meiosis, explaining the diploid particles of heredity in Mendel’s laws.
Today, a scientist making a groundbreaking discovery of this caliber would have established a solid reputation in science. But in Sutton’s day, there were no graduate student stipends or regular sources of scientific funding. So Sutton became a physician and went back to his hometown in Kansas to practice medicine.
Theodor Boveri, a talented German scientist, worked completely independent of Sutton yet reached similar conclusions in the same year as Sutton. Boveri studied the behavior of chromosomes in sea urchin eggs. Although sea urchin chromosomes are small and thus cannot be distinguished by their shape, their number can be observed during fertilization and cell division. Boveri’s studies reached the same conclusions as Sutton’s, linking chromosomes with the particles of Mendelian inheritance. He also observed that eggs from which the nucleus was removed could be fertilized and then develop into normal—
56
Corn Crosses Uncover the Molecular Mechanism of Crossing Over
Creighton, H., and B. McClintock. 1931. A correlation of cytological and genetical crossing-

Fruit flies have taught us how our body plan is determined. Who would have guessed that fruit flies would teach us so much? Among the many fruitful (pun intended) discoveries by Thomas Hunt Morgan, who developed the fly as a model for genetic study, was the finding that genes cross over between chromosomes. Although researchers presumed that genetic recombination occurred through material exchange between homologous chromosomes, there was no proof that this was indeed the case. Direct proof came in 1931 from a now classic study in corn (maize) by Harriet Creighton and Barbara McClintock.
The insightful experiments of Creighton and McClintock combined genetics and cytologic methods. To visualize crossing over between two homologous chromosomes, one first needs to find two homologous chromosomes that look different—
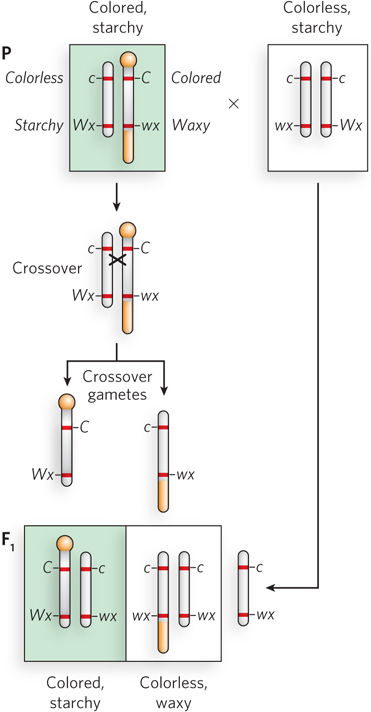
57
Hershey and Chase Settle the Matter: DNA Is the Genetic Material
Hershey, A.D. and M. Chase, 1952. Independent functions of viral protein and nucleic acid in growth of bacteriophage. J. Gen. Physiol. 36:39–

In 1952, Martha Chase and Alfred Hershey performed a now classic experiment, the results of which would convince the world that DNA is the genetic material. They used a bacterial virus, mainly composed of protein and DNA, and set out to determine which of these components carries the hereditary material. Bacteriophage T2, or T2 phage, like other bacterial viruses, consists of a protein coat and a DNA core. Hershey and Chase took advantage of a key chemical difference between these two macromolecules. Using the fact that sulfur is found in proteins but not in DNA, and that phosphorus is found in DNA but not in proteins, they prepared radiolabeled T2 phage using either 35S (only protein is radioactively labeled) or 32P (only DNA is radioactively labeled). The two T2 phage samples were allowed to attach to their bacterial host, Escherichia coli, in two separate flasks (Figure 3). After infection, the bacteria were transferred to a kitchen blender and agitated to strip away any T2 phage material from the outside of the bacterial cell walls. Cells were collected by centrifugation, leaving unattached phage in the supernatant. The results were clear: 32P-
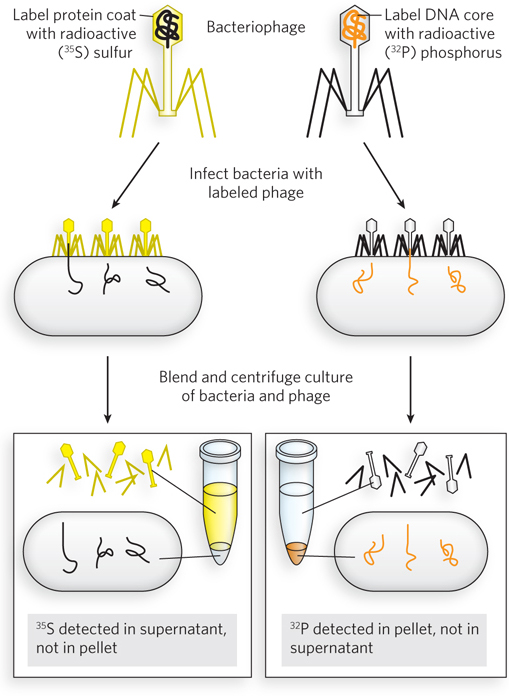
Although earlier experiments by Avery had suggested that DNA was the genetic material, the Hershey and Chase experiment finalized this important conclusion and inspired Watson and Crick in their quest to determine the structure of DNA. Hershey shared the 1969 Nobel Prize in Physiology or Medicine with Max Delbrück and Salvador E. Luria for their discoveries on the replication mechanism of viruses.
58