Nucleotides Comprise Phosphates and Characteristic Bases and Sugars
A nucleotide is a molecule consisting of three characteristic components: a heterocyclic base, a five-carbon sugar called a pentose, and a phosphate group. (A heterocyclic compound is a cyclic compound with one or more ring structures that contain atoms of at least two different elements.) The same molecule without the phosphate group is called a nucleoside. Each base is a derivative of one of two parent compounds, a purine or a pyrimidine (Figure 6-2a), which are nitrogenous (nitrogen-containing) bases. They are called bases because free purines and pyrimidines are weakly basic compounds. The carbon and nitrogen atoms in the parent structures are numbered according to convention to facilitate the naming and identification of the many derivative compounds. The carbon atoms in the pentose are also numbered; in nucleotides and nucleosides, these numbers are given a prime (′) designation to distinguish the sugar carbons from the numbered carbon and nitrogen atoms of the nitrogenous bases.
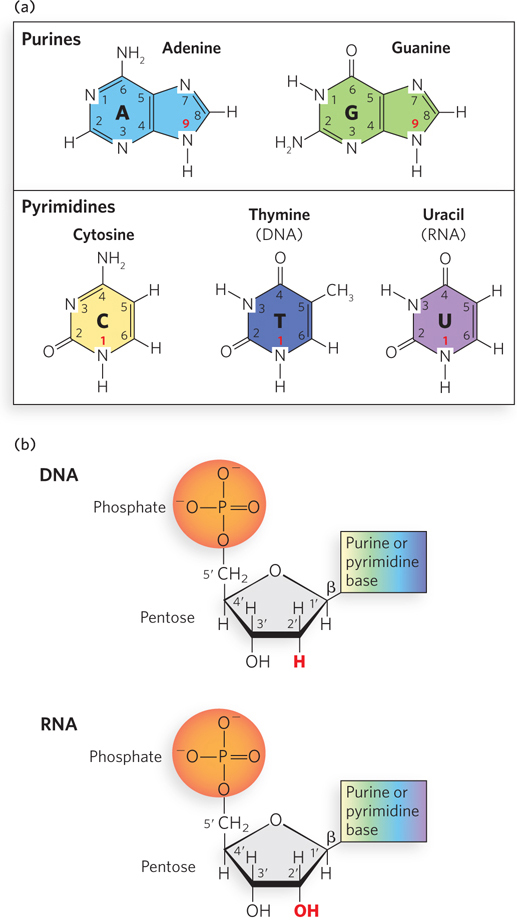
Figure 6-2: The chemical composition of nucleotides. (a) The bases are purines, with nine-membered rings, or pyrimidines, with six-membered rings, with numbering systems as shown. In DNA and RNA, the purines are adenine and guanine; in DNA, the pyrimidines are cytosine and thymine; in RNA, the pyrimidines are cytosine and uracil. The ring atoms in the bases that connect to the ribose (N-9 for purines and N-1 for pyrimidines) are indicated with bold red numbers. (b) Nucleotides consist of a phosphate group, a pentose sugar, and a heterocyclic base; carbons in the pentose rings are numbered as shown, with numbers followed by a prime (′) to distinguish them from the numbered atoms of the bases. In DNA, the pentose is 2′-deoxyribose, which has no hydroxyl group on the 2′ carbon (red); in RNA, the sugar is ribose, which has a 2′ hydroxyl (red). A glycosidic bond links the 1′ carbon of ribose or deoxyribose to the base; β indicates the configuration of the base relative to the pentose ring.
In nucleosides, the covalent joining of a base (at N-9 of purines and N-1 of pyrimidines) to the 1′ carbon (C-1′) of the pentose forms a glycosidic bond (specifically, an N-β-glycosyl bond), which involves the loss of a molecule of water. To form a nucleotide, a phosphate group is covalently joined to the 5′ carbon (C-5′) of the pentose to form an ester, also with the concomitant loss of a water molecule (Figure 6-2b).
Four different bases are found in DNA: two are purines, adenine (A) and guanine (G), and two are pyrimidines, cytosine (C) and thymine (T). RNA also contains four types of bases. The two purines are the same as those in DNA: adenine and guanine; and, as in DNA, one of the pyrimidines is cytosine. However, the second major pyrimidine in RNA is uracil (U) instead of thymine. Only rarely does thymine occur in RNA, or uracil in DNA. The structures of the five major bases are shown in Figure 6-2a; the nomenclature of their corresponding nucleotides and nucleosides was summarized in Chapter 3 (see Table 3-1).
Nucleic acids have two kinds of pentoses. The recurring nucleotide units of DNA contain 2′-deoxy-d-ribose, whereas the nucleotide units of RNA contain d-ribose. The d-ribose has a hydroxyl group attached to the 2′ carbon, whereas 2′-deoxy-d-ribose lacks this functional group (see Figure 6-2b). In nucleotides, both types of pentoses are in their β-furanose (closed five-membered ring) form (Figure 6-3a). As Figure 6-3b shows, the pentose ring is not planar but exists in one of a variety of conformations generally described as “puckered.” The predominant type of sugar pucker that characterizes DNA differs from that found in RNA, resulting in the different shapes and geometries of the DNA and RNA double helices, as we describe later in this chapter.
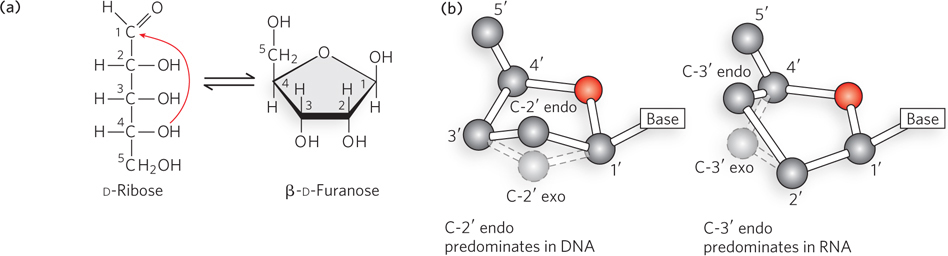
Figure 6-3: Pentose ring structures in nucleic acids. (a) The linear and closed-ring forms of ribose are in equilibrium in solution. When incorporated into nucleosides, nucleotides, or polynucleotides, the pentose exists only in the ring form. The pentose ring is formed by reaction of the hydroxyl group on C-4 with the aldehyde at C-1. (b) The pentose rings in nucleosides and nucleotides can exist in four predominant puckered conformations. In each case, four of the five ring atoms are nearly coplanar, but the fifth ring atom, either C-2′ or C-3′, is out of the plane. The C-2′ endo configuration, in which the C-2′ atom points in the same direction as the C-5′ atom, predominates in DNA. The C-3′ endo configuration, in which the C-3′ atom points in the same direction as the C-5′ atom, predominates in RNA.
Because of their different pentose components, the structural units of DNAs and RNAs are known as deoxyribonucleotides (or deoxyribonucleoside 5′- monophosphates) and ribonucleotides (or ribonucleoside 5′-monophosphates), respectively (Figure 6-4). Although the major purine and pyrimidine nucleotides are the most common, both DNA and RNA molecules also contain some minor bases. In DNA, the minor bases are usually methylated forms of the major bases. These unusual bases in DNA molecules often have roles in regulating or protecting the genetic information. Minor bases of many types are also found in RNA molecules, particularly in tRNAs, rRNAs, and other RNAs whose function requires a specific three-dimensional structure. In cells, minor bases in RNA can be formed by enzymatic modification of one of the common nucleotides to add or remove a functional group, or by complete replacement of a standard base with a less common one. Chemical modifications of DNA and RNA and their effects on nucleotide structure and function are discussed in Section 6.4.
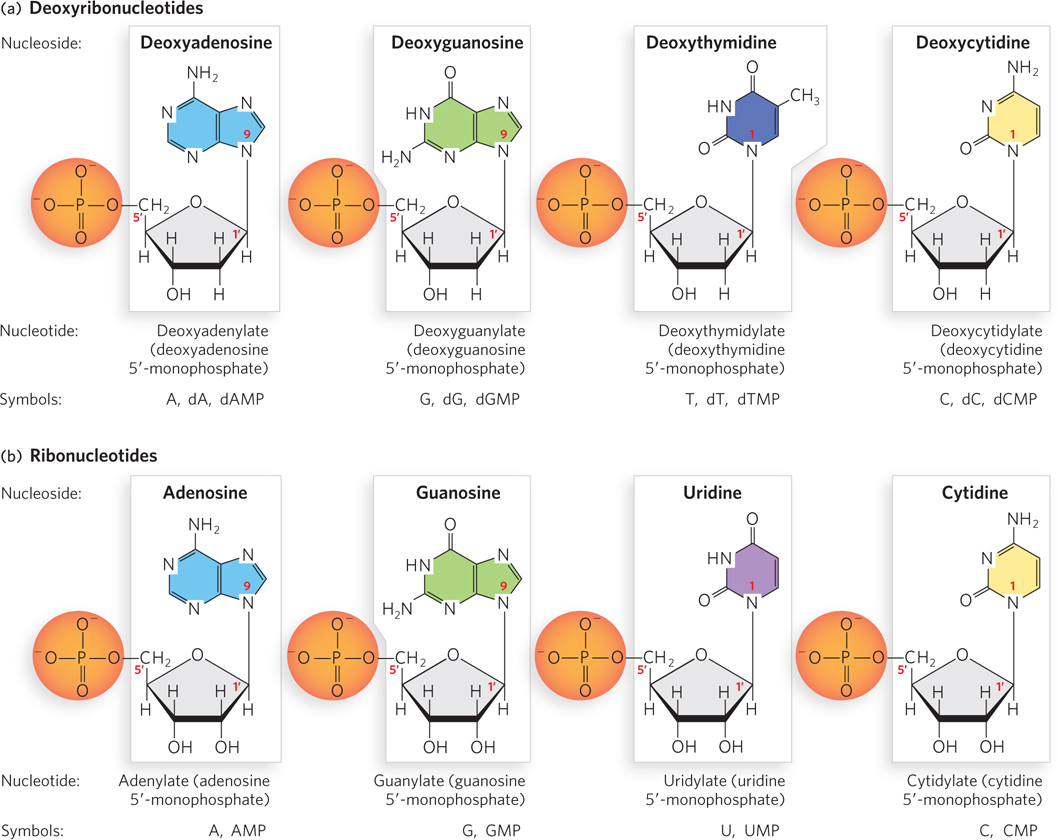
Figure 6-4: Deoxyribonucleotides and ribonucleotides of nucleic acids. All nucleotides are shown in their predominant form at neutral pH. Note that the nucleoside is the boxed portion and the nucleotide is the form with the phosphate group included. (a) Deoxyribonucleotides of DNA. (b) Ribonucleotides of RNA.
Cells also contain nucleotides with phosphate groups in positions other than on the 5′ carbon (Figure 6-5). For example, ribonucleoside 2′,3′-cyclic monophosphates are stable intermediates, and ribonucleoside 2′-monophosphates or ribonucleoside 3′-monophosphates are the end products of the hydrolysis of RNA by enzymes called ribonucleases. Other variations are adenosine 3′,5′-cyclic monophosphate (cAMP) and guanosine 3′,5′-cyclic monophosphate (cGMP), which are important chemical signals of the metabolic state of the cell (further discussed later in this section).
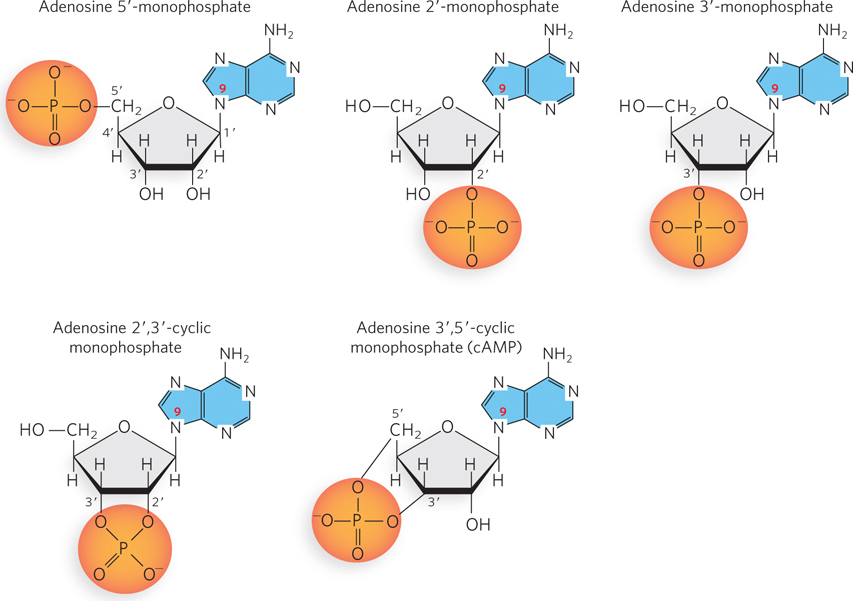
Figure 6-5: Examples of adenosine monophosphates. Adenosine 5′-monophosphate, with a phosphate group on C-5′, is the most common adenine-containing nucleotide and the one found in RNA. Adenosine 2′-monophosphate, adenosine 3′-monophosphate, and adenosine 2′,3′-cyclic monophosphate are formed during enzymatic or alkaline hydrolysis of RNA (see Figure 6-7). Adenosine 3′,5′-cyclic monophosphate (cAMP) is a signaling molecule that accumulates when the cell has a limited supply of nutrients.
Phosphodiester Bonds Link the Nucleotide Units in Nucleic Acids
The successive nucleotides of DNA and RNA are covalently joined through phosphate group “connectors” in which the 5′-phosphate group of one nucleotide unit is linked to the 3′-hydroxyl group of the next nucleotide, creating a phosphodiester bond (Figure 6-6); this involves the loss of water, and the joined nucleotides are therefore referred to as “residues.” As we will see, these 5′-to-3′ links give every DNA or RNA chain a directionality, or polarity. The alternating phosphate and sugar residues form the backbone of the nucleic acid, and the bases can be viewed as side groups joined to this sugar–phosphate backbone at regular intervals.
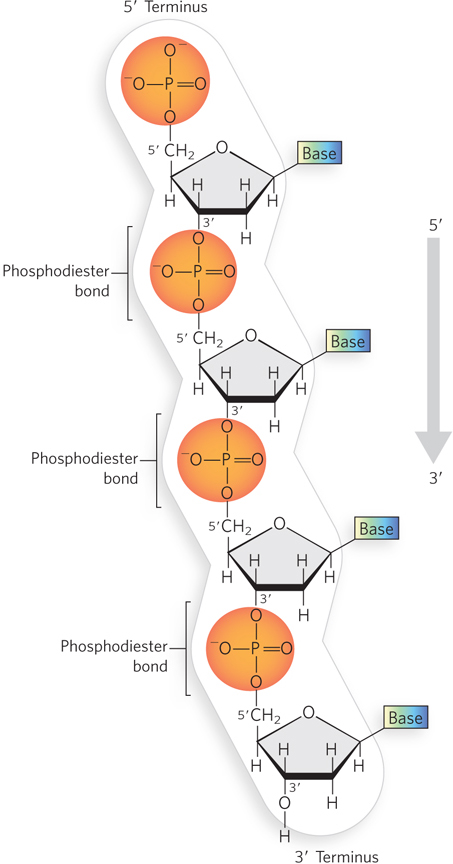
Figure 6-6: The phosphodiester linkages in nucleic acids. Phosphodiester bonds covalently connect the nucleotide units in DNA and RNA. The backbone of alternating sugars and phosphate groups is highly negatively charged. All the phosphodiester linkages in a polynucleotide chain have the same orientation, giving each linear nucleic acid strand a specific polarity and distinct 5′ and 3′ termini. Shown here is a strand of DNA.
KEY CONVENTION
The polarity of a single DNA or RNA chain is defined by the chemical groups—a free 5′ phosphate or 3′ hydroxyl—at the termini of the chain, not by the 5′ and 3′ oxygens of internal phosphodiester bonds. Linear DNA and RNA molecules each have a single unique 5′ terminus and 3′ terminus.
The backbone of both DNA and RNA is hydrophilic. The hydroxyl groups of the sugar residues form hydrogen bonds with water. The phosphate groups, with a pKa near 2, are completely ionized and negatively charged at pH 7, and the negative charges are generally neutralized by ionic interactions with positive charges on proteins, metal ions, or short, linear organic molecules called polyamines, which contain two or more amine groups.
The covalent backbone of DNA and RNA is subject to slow, nonenzymatic hydrolysis of the phosphodiester bonds. In the test tube, RNA is hydrolyzed rapidly under alkaline conditions, but DNA is not; the 2′-hydroxyl group on the sugars in RNA is directly involved in the hydrolytic process. Cyclic 2′,3′-monophosphates are the first products of the action of alkali on RNA, and these are rapidly hydrolyzed further to yield a mixture of nucleoside 2′- and 3′-monophosphates (Figure 6-7). The sugar component of DNA does not have a 2′-hydroxyl group and is not as easily hydrolyzed, making the DNA backbone inherently more stable than that of RNA. The inherent instability of RNA relative to DNA serves a purpose in gene expression: RNA molecules can be synthesized and degraded many times during the life of a cell, whereas the corresponding DNA is maintained during cell division and during extended periods in nonreplicating cells. It is the stability of DNA that allows the recovery and analysis of DNA from historically preserved samples, such as Neanderthal tissues, which in recent years has enabled the sequencing of Neanderthal DNA (see Chapter 8).
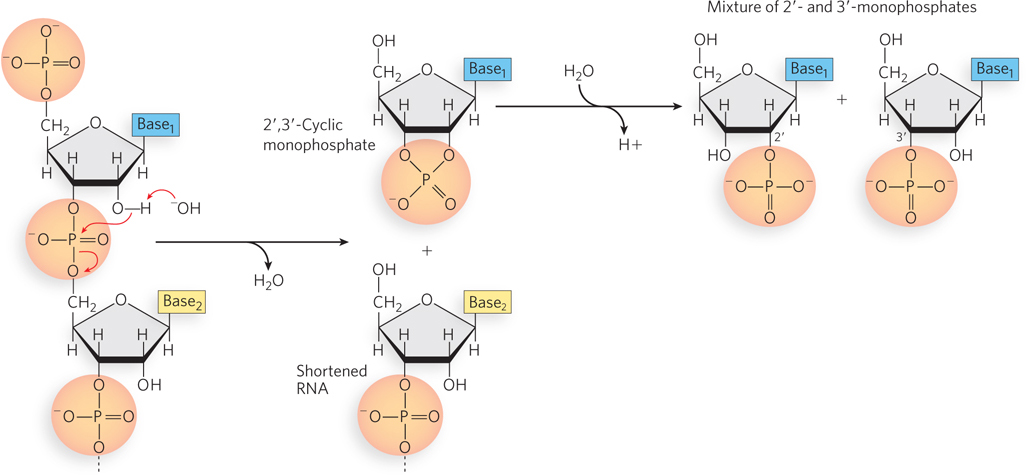
Figure 6-7: The hydrolysis of RNA. The 2′-hydroxyl group can be activated as a nucleophile under alkaline (pH >7) conditions or by ribonucleases. The 2′,3′-cyclic monophosphate product is further hydrolyzed to a mixture of 2′- and 3′-monophosphates.
KEY CONVENTION
The structure of a single strand of nucleic acid is always written with the 5′ terminus at the left and the 3′ terminus at the right—that is, in the 5′→3′ direction. When a double-stranded sequence is shown, the top strand is written in the 5′→3′ direction. The various representations of a nucleotide sequence, using a pentanucleotide as example, are: 5′-ACGTA-3′, ACGTA, pA-C-G-T-AOH, pApCpGpTpA, and pACGTA, where p denotes a monophosphate, and a subscript OH denotes a 3′-hydroxyl group.
A short nucleic acid containing 50 or fewer nucleotides is generally called an oligonucleotide. A longer nucleic acid is called a polynucleotide.
The Properties of Nucleotide Bases Affect the Three-Dimensional Structure of Nucleic Acids
Purines and pyrimidines have a variety of chemical properties that affect the structure, and ultimately the function, of nucleic acids. The purine and pyrimidine bases common in DNA and RNA are conjugated ring systems, with alternating single and double bonds between ring atoms (see Figure 6-2). Resonance among atoms in the rings gives most of the bonds a partial double-bond character. One result is that pyrimidines are planar molecules and purines are very nearly planar, with just a slight pucker. Free pyrimidine and purine bases can exist in two or more forms, called tautomers, depending on pH (Figure 6-8). The structures shown on the left in Figure 6-8 are the tautomers that predominate at physiological pH (pH ∼7). As a result of resonance, delocalized electrons in the conjugated rings are available to absorb ultraviolet (UV) light at wavelengths near 260 nm (Figure 6-9). Ultraviolet light absorbance is used as a method for detecting nucleic acids (see Section 6.4).
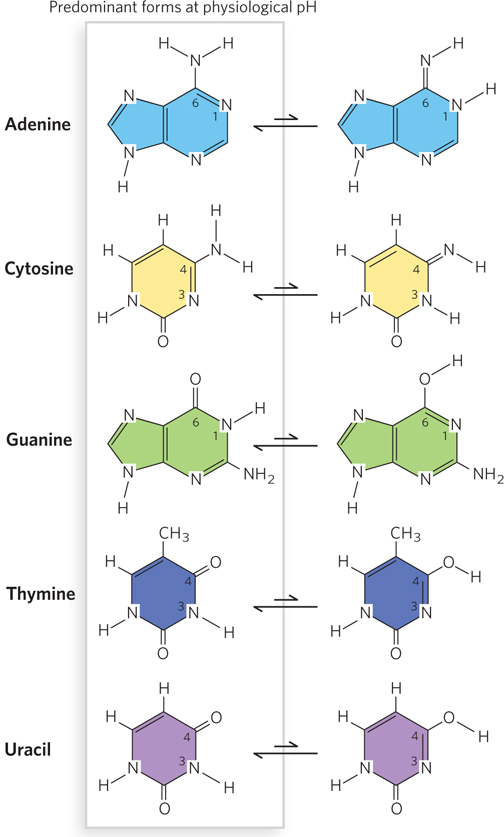
Figure 6-8: Tautomers of pyrimidine and purine bases. Each purine or pyrimidine can exist as one of several isomers that differ in the placement of a hydrogen atom and a double bond (tautomers). Shown here are two tautomers for each of the common bases found in nucleic acids. The predominant tautomer of each base at physiological pH is on the left. These predominant tautomeric forms are found in DNA and RNA and participate in canonical Watson-Crick base pairing (see Figure 6-11).
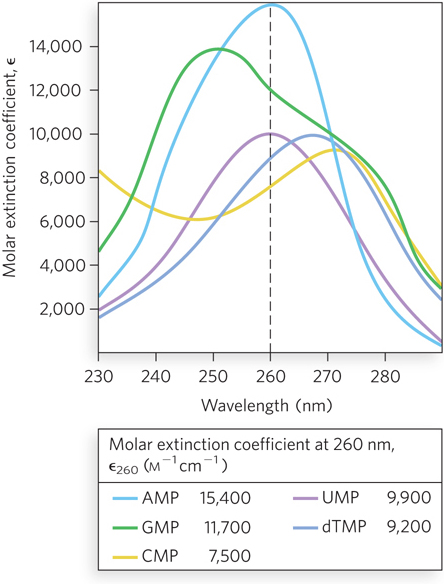
Figure 6-9: Absorption spectra of the common nucleotides. The plots show molar extinction coefficients at pH 7.0 as a function of wavelength for the nucleoside 5’-monophosphates. The molar extinction coefficient, ε (epsilon; units m−1cm−1), measures the amount of light absorbed by a 1 m solution with a light path length of 1 cm. The table shows the molar extinction coefficients at 260 nm for the plotted nucleotides.
The chemical properties of the purines and pyrimidines also give rise to two important modes of interaction between bases in nucleic acids. The first, called hydrophobic stacking, arises because the bases are hydrophobic and thus relatively insoluble in water at the near-neutral pH of the cell. As a result, the bases align such that two or more are positioned with the planes of their rings in parallel, like a stack of coins (Figure 6-10). Base stacking helps minimize the contact of the bases with water, and base-stacking interactions are very important in stabilizing the three-dimensional structure of nucleic acids. Such stacking also involves a combination of van der Waals and electrostatic interactions among the bases.
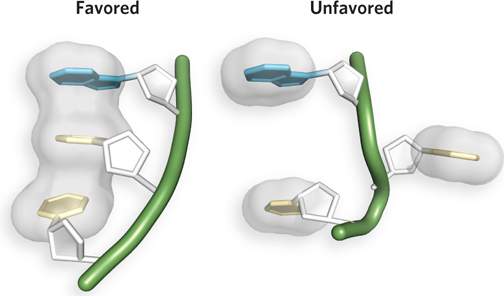
Figure 6-10: Base stacking in nucleic acids. Hydrophobic, van der Waals, and electrostatic interactions favor the alignment of bases in an aqueous solution or within a polynucleotide chain (three nucleotides in an RNA chain are shown here); the unstacked orientation is unfavored. Van der Waals radii are shown in gray.
The second important mode of base interaction in nucleic acids is base pairing, which results from the hydrogen-bonding capacity of the ring nitrogens, ring carbonyl groups, and exocyclic (i.e., outside the ring structure) amino groups of the pyrimidines and purines. Hydrogen bonds between bases, involving the amino and carbonyl groups, permit a complementary association of two (and occasionally three or four) nucleic acid strands. The most important hydrogen-bonding patterns are those defined by Watson and Crick in 1953, in which A hydrogen-bonds specifically with T (or U), and G with C (Figure 6-11). These two types of base pairs predominate in double-stranded DNA and RNA (and thus are considered the canonical base pairs). The purine and pyrimidine tautomers that predominate at physiological pH, shown on the left in Figure 6-8, readily adopt these hydrogen-bonding patterns. It is this specific pairing of bases in the double-stranded DNA helix that permits the duplication of genetic information.
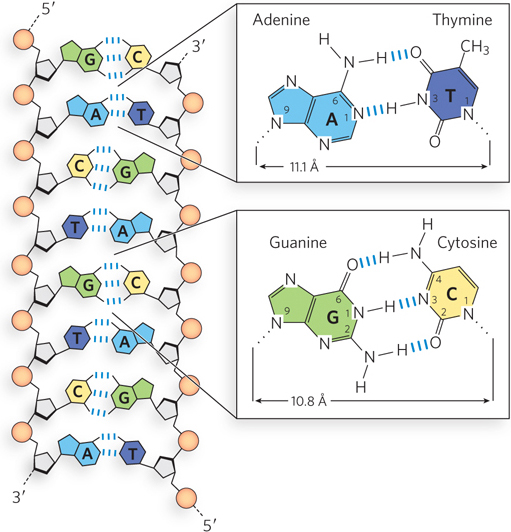
Figure 6-11: Hydrogen-bonding patterns in canonical Watson-Crick base pairs. Hydrogen bonds are represented by three blue lines.
Nucleotides Play Additional Roles in Cells
As we have mentioned, nucleotides have functions in cells beyond providing the building blocks for DNA and RNA. The phosphate group covalently linked to the 5′ hydroxyl of a nucleoside may have one or two additional phosphates attached. The resulting molecules are referred to as nucleoside mono-, di-, and triphosphates (Figure 6-12). Starting from the phosphate closest to the ribose, the three phosphates are generally labeled α, β, and γ. Nucleoside triphosphates are the activated precursors of DNA and RNA synthesis (see Chapters 11 and 15). Furthermore, transfer of the γ-phosphoryl group from a nucleoside 5′-triphosphate (typically ATP) to another molecule provides the chemical energy to drive a wide variety of cellular reactions (as discussed in Chapter 3).
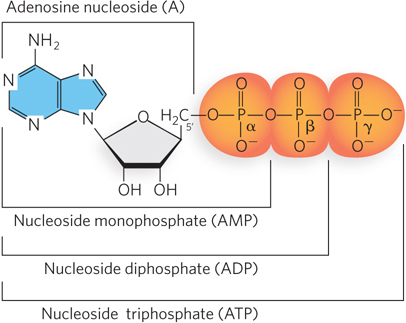
Figure 6-12: Nomenclature for nucleotides. The phosphate group covalently linked to the 5′ carbon of a nucleoside may have one or two additional phosphates attached; the resulting nucleotide molecules are referred to as nucleoside mono-, di-, and triphosphates. Starting from the phosphate closest to the ribose, the three phosphates are designated α, β, and γ.
The nucleoside adenosine also forms part of the structure of otherwise unrelated enzyme cofactors that perform a wide range of chemical functions (Figure 6-13). For example, nicotinamide adenine dinucleotide (NAD+) plays a crucial role in cellular energy production in both animal cells and plant cells. A related cofactor, NADP+, contributes to the synthesis of lipids and nucleic acids, and participates in photosynthesis. Flavin adenine dinucleotide (FAD) is the active form of vitamin B2 (riboflavin), which transfers electrons in some biosynthetic reactions. Enzymatic reactions that involve the transfer of a methyl group from one molecule to another often involve the substrate S-adenosylmethionine (adoMet), which consists of an adenosine linked to a methionine.
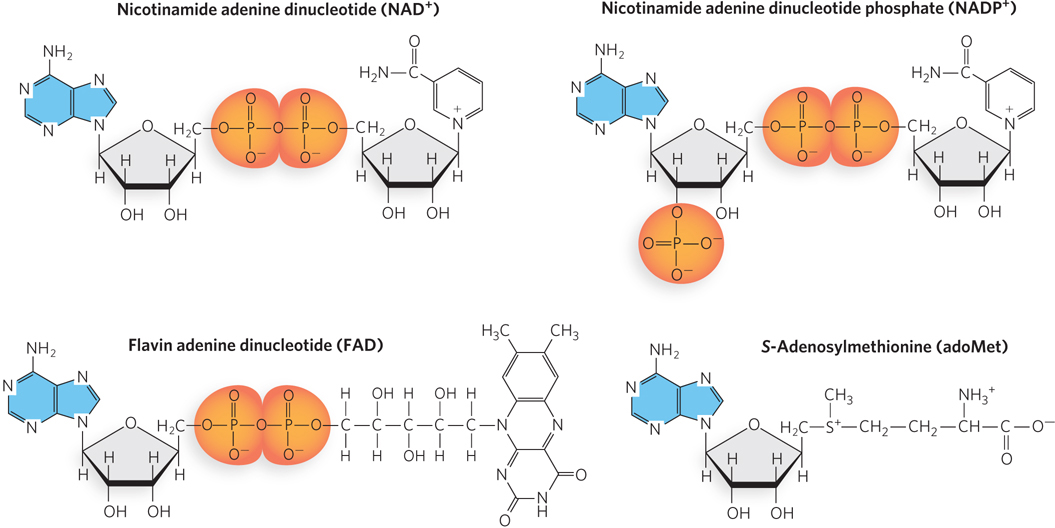
Figure 6-13: Some cofactors and a substrate containing adenosine. The adenine base (blue) and the ribose attached to it form the adenosine portion of each molecule. See text for details.
In these adenosine-containing compounds, the adenosine portion does not participate directly in the molecule’s primary function. Instead, it seems to be a molecular “handle” that allows the cofactor or substrate to bind tightly in an enzyme active site. Adenosine may have taken on this role partly because of the abundance of adenine in the environment of the early Earth (see the How We Know section in Chapter 1). The importance of adenosine probably lies not so much in some special chemical characteristic as in the evolutionary advantage of using one compound for multiple purposes. Once ATP became the universal source of chemical energy, biological systems developed to synthesize ATP in greater abundance than the other nucleotides; because adenosine was abundant, it became the logical choice for incorporation into a wide variety of structures. This economy also extends to protein structure. For example, the Rossmann fold (discussed in Chapter 4; see Figure 4-15), a protein domain that binds adenosine, is found in many enzymes that bind ATP and adenosine-containing enzyme cofactors.
Some nucleotides function as regulatory molecules. One of the most common is adenosine 3′,5′-cyclic monophosphate (cyclic AMP, or cAMP) (see Figure 6-5), formed from ATP in a reaction catalyzed by adenylyl cyclase—an enzyme whose activity is closely linked to the metabolic state of the cell. Cyclic AMP performs regulatory functions in virtually every cell outside the plant kingdom. Guanosine 3′,5′-cyclic monophosphate (cGMP) occurs in many cells and also has regulatory functions.
Both cAMP and cGMP are called second messengers, because they are produced or degraded in response to the interaction of extracellular chemical signals (“first messengers”) with receptors on the cell surface. The second messengers induce adaptive changes in the cell interior. In this way, cells can respond quickly to environmental changes by taking cues from hormones or other external chemical signals. For example, light entering the photoreceptors of the human eye activates an enzyme that degrades cGMP, causing sodium channels in the photoreceptor cell membrane to close and thereby triggering visual information to be sent to the brain. Another regulatory nucleotide, guanosine tetraphosphate (ppGpp), is produced in bacteria in response to a slowdown in protein synthesis during amino acid starvation. This nucleotide inhibits synthesis of the rRNA and tRNA molecules needed for protein synthesis, preventing the unnecessary production of nucleic acids.
SECTION 6.1 SUMMARY
A nucleotide consists of a nitrogenous base (a purine or a pyrimidine), a pentose sugar, and one or more phosphate groups. Nucleic acids are polymers of nucleotide units, joined by phosphodiester linkages between the 3′-phosphate group of one unit and the 5′-hydroxyl group of the next. Polynucleotides have a directionality defined by a 5′ terminus and a 3′ terminus.
DNA and RNA are two types of nucleic acids. The nucleotides in DNA contain 2′-deoxy-d-ribose, whereas the nucleotides in RNA contain d-ribose. The hydroxyl group at the 2′ position in d-ribose makes the RNA backbone more susceptible to hydrolysis than DNA.
Both DNA and RNA contain four different bases, two purines and two pyrimidines. The purines in DNA and RNA are the same: adenine and guanine. DNA contains the pyrimidines cytosine and thymine, and RNA contains the pyrimidines cytosine and uracil.
In addition to A, G, C, T, and U, numerous minor bases occur in nature, often differing from the canonical bases by the presence of a functional group at a particular position on the base; these bases can play central roles in nucleic acid structure and biochemical function.
The chemical properties of the nitrogenous bases affect nucleotide and nucleic acid structure. As a result of resonance, the bases in a nucleotide chain are planar and tend to stack. The hydrogen-bonding capabilities of the conjugated rings allow the formation of specific base-pair interactions: A pairs with T (or U), and C pairs with G.
Adenosine is a building block for some important enzyme cofactors, such as nicotine adenine dinucleotide (NAD+) and flavin adenine dinucleotide (FAD). The presence of an adenosine component in a variety of cofactors enables recognition by enzymes that share common structural features.
Cyclic AMP, formed from ATP in a reaction catalyzed by adenylyl cyclase, is a common second messenger produced in response to hormones and other chemical signals.