17.3 CRACKING THE CODE
Cracking the genetic code was one of the most significant scientific milestones of the last half of the twentieth century. Today, it would be a simple matter of comparing the sequences of nucleic acids and their corresponding proteins. But in the early 1960s, nucleic acid sequencing had not yet been invented, and although protein sequencing methods were firmly established, the process was laborious. Given the state of sequencing methodology, it is surprising that new and ingenious ways of studying and deciphering the code in its entirety were developed at all. Here we briefly review the major experimental strategies that enabled investigators to crack the code.
Random Synthetic RNA Polymers Direct Protein Synthesis in Cell Extracts

First, Marshall Nirenberg and Heinrich Matthaei made a simple but remarkable discovery that set in motion the cracking of the genetic code: they found that they could use the enzyme polynucleotide phosphorylase to synthesize RNA templates that would code for protein polymers in cell extracts of E. coli. To prepare the cell extracts, endogenous mRNA had to be removed, to allow the translation machinery to work on the synthetic RNA templates. To do this, the extracts were preincubated so that the endogenous ribonuclease (RNase) activity would destroy all existing mRNA, and deoxyribonuclease (DNase) was added to the extracts to prevent further mRNA production. With these treatments, protein synthesis in the cell extracts (or “translation extracts”) was dependent on the addition of exogenous synthetic RNA.
Polynucleotide phosphorylase does not require a template; it uses ribonucleoside diphosphates (NDPs) to make random polymers of RNA:
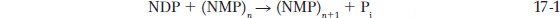
The intracellular role of polynucleotide phosphorylase is to catalyze the reverse reaction to degrade RNA, using inorganic phosphate to yield NDPs. In vitro, the enzyme can be made to synthesize RNA by the addition of excess NDPs, which at sufficient concentration are polymerized. However, because polynucleotide phosphorylase is not template-
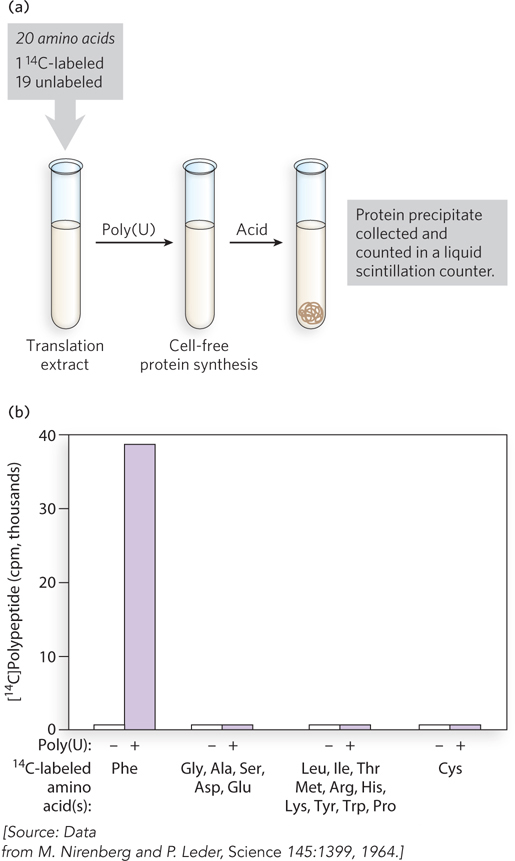
Using UDP as the only ribonucleoside diphosphate substrate, polynucleotide phosphorylase catalyzes the synthesis of poly(U) RNA. To determine what type of protein synthesis poly(U) directs, Nirenberg and Matthaei added poly(U) to reaction mixtures with the E. coli translation extracts and amino acid mixtures, but using only one radioactively labeled amino acid (Figure 17-14). At the end of the incubation, the reaction mixtures were treated with acid, which precipitates protein polymers but leaves free amino acids in solution. Precipitates were collected and counted in a liquid scintillation counter, which measures radioactivity in counts per minute (cpm). The results showed that poly(U) directed the synthesis of polyphenylalanine, poly(Phe), and therefore the codon for phenylalanine must be UUU. The other homopolymers were synthesized and tested by similar methods. Poly(A) specified the synthesis of poly(Lys), identifying AAA as a codon for lysine. Poly(C) resulted in the production of poly(Pro), and thus CCC is a codon for proline. Unfortunately, poly(G) forms intramolecular hydrogen-
601

The use of polynucleotide phosphorylase was extended to copolymers, RNAs containing more than one type of nucleotide. As an example of this type of analysis, Table 17-2 shows the results obtained by Severo Ochoa’s group, using ADP and CDP in a 5:1 molar ratio. Polynucleotide phosphorylase incorporates NDPs into RNA randomly, so these conditions produced RNA with five times more A than C. All possible codons containing A and C were generated in the random RNA copolymer, in the following distribution (setting AAA at 100): AAA (100), A2C (60), AC2 (12), and CCC (0.8). (Note the use of A2C and AC2 to indicate that the order of nucleotides is unknown.) Use of this heterogeneous RNA copolymer in translation extracts directed the synthesis of polypeptides containing asparagine, glutamine, histidine, lysine, proline, and threonine. From the relative amounts of these amino acids in the precipitated protein product, the investigators could deduce the respective codon compositions specifying each amino acid. No amino acid was observed at the low frequency expected of a CCC codon (0.8) relative to an AAA codon (100). But proline was observed to be incorporated at a relative frequency of 4.7, which is close to the expected frequency for two codons, CCC and AC2.
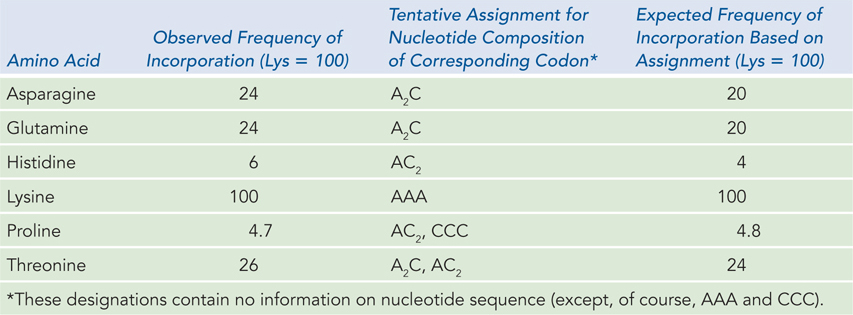
The researchers could infer from this result that proline is specified by two codons having the compositions AC2 and CCC, reflecting the degenerate nature of the genetic code. The result was supported by experiments using poly(C), which identified CCC as a codon specifying proline. The other codon, AC2, could have the sequence ACC, CCA, or CAC. Because polynucleotide phosphorylase polymerizes NDPs randomly, one can assign only codon compositions from these results, not codon sequences (except, of course, for codons with only one type of nucleotide).
602
Numerous experiments were performed using random RNA copolymers, and in this way the nucleotide composition of about 40 codons could be assigned to particular amino acids. However, to identify the nucleotide sequence of codons, RNA molecules of defined sequence were required.
RNA Polymers of Defined Sequence Complete the Code
Chemical synthesis of short nucleic acids of specific sequence was needed to define the complete genetic code. In 1964, Nirenberg and his coworkers at the National Institutes of Health discovered a novel method to identify an amino acid associated with a short synthetic codon. They found that during protein synthesis in E. coli (using translation extracts and 14C-
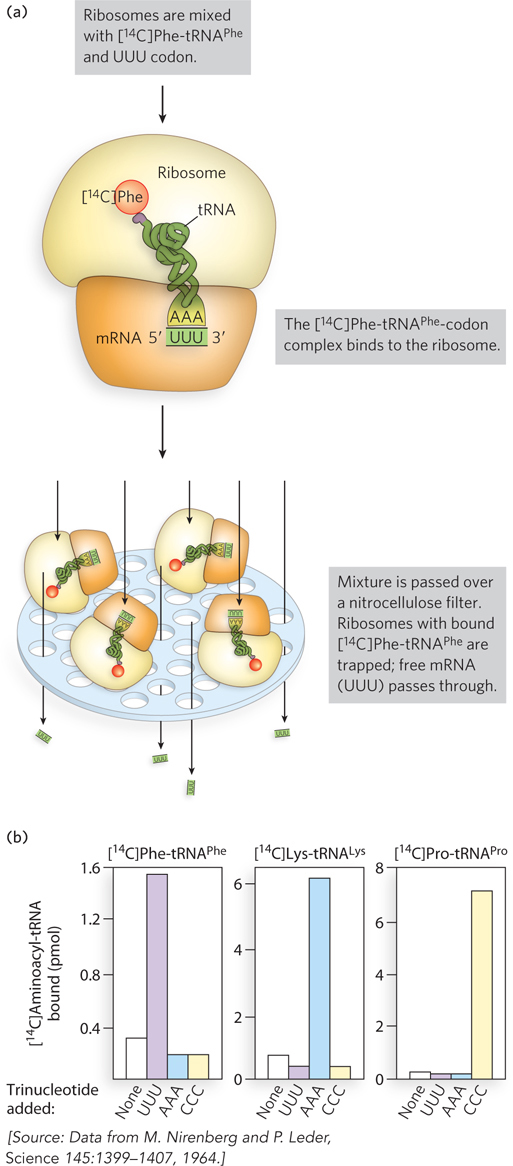
Results from Nirenberg’s initial study, using three different [14C]aminoacyl-

Another breakthrough came from H. Gobind Khorana, who developed chemical methods to synthesize short polyribonucleotides with defined sequences of two, three, or four nucleotide repeats. These short RNAs were then amplified by polymerases to produce long polymers of defined repeating sequence. Results obtained with these long RNA polymers, combined with the earlier results from trinucleotide-
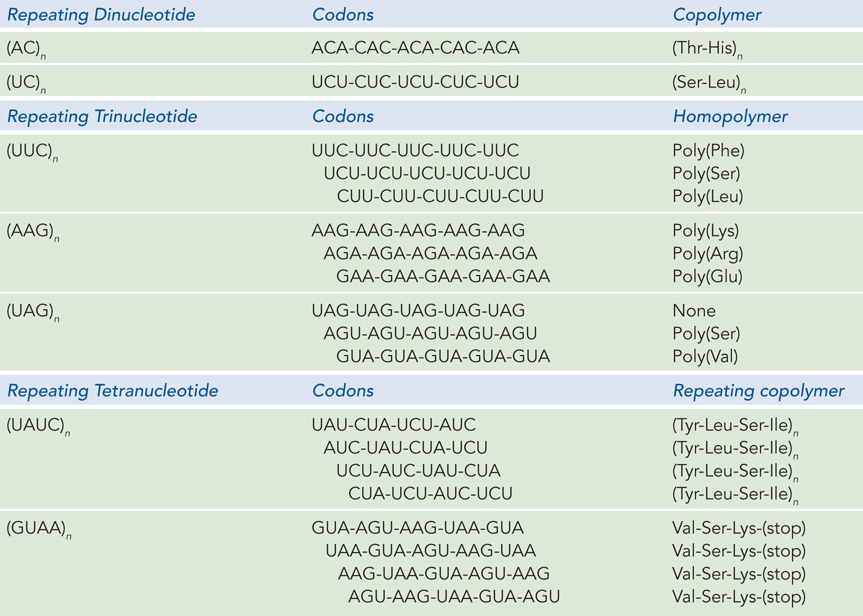
603
Repeating trinucleotide sequences yield three types of homopolymeric peptides. For example, for a repeating sequence of UUCs, the mRNA triplets can be read as repeating UUC, or UCU, or CUU codons. Poly(UUC) produced poly(Phe), poly(Lys), and poly(Leu). The ribosome-
Consolidation of the results from many different experiments permitted the assignment of 61 of the 64 possible codons. The other three were identified as termination codons, in part because of the results obtained with synthetic RNAs in which the codons disrupted the amino acid coding patterns. Meanings for all the triplet codons were firmly established by 1966, and they have been verified numerous times, in many different ways. In retrospect, the experiments of Nirenberg and Khorana that identified codons in translation extracts should not have worked in the absence of initiation codons. Serendipitously, with the high magnesium concentration used in their in vitro experiments, the normal initiation requirement for protein synthesis was relaxed.
604
The Genetic Code Is Validated in Living Cells
We now know the sequences of entire genomes of organisms ranging from bacteria to humans, and this enormous body of information confirms that the genetic code determined in the translation extract experiments is indeed interpreted in the same way in all living organisms. Even in the 1960s, however, there was evidence that the genetic code was the same in cells as in cell extracts.
By the mid-
SECTION 17.3 SUMMARY
Researchers cracked the genetic code in experiments that used radioactively labeled amino acids and cell extracts that translate synthetic RNA templates.
The compositions of many codons specifying amino acids were assigned on the basis of experiments using random RNA polymers synthesized by polynucleotide phosphorylase.
Two techniques that used RNAs of defined sequence completed the codon table. An assay that induced the binding of [14C]aminoacyl-
tRNAs and their cognate synthetic trinucleotide RNAs to ribosomes allowed the identification of most of the codons. With the availability of long, synthetic RNA polymers of defined repeating sequence, researchers used the in vitro protein synthesis assay to assign the remaining codons. Studies of amino acid replacements in mutant proteins confirmed that the genetic code in living cells is the same as that determined in cell extracts.