8.3 Transcription in Eukaryotes
As described in Chapter 7, the replication of DNA in eukaryotes, although more complicated, is very similar to the replication of DNA in prokaryotes. In some ways, the same can be said for transcription, because eukaryotes retain many of the events associated with initiation, elongation, and termination in prokaryotes. Transcription is more complicated in eukaryotes for three primary reasons.
The larger eukaryotic genomes have many more genes to be recognized and transcribed. Whereas bacteria usually have a few thousand genes, eukaryotes have tens of thousands of genes. Furthermore, there is much more noncoding DNA in eukaryotes. Noncoding DNA originates by a variety of mechanisms that will be discussed in Chapter 15. So, even though eukaryotes have more genes than prokaryotes do, their genes are, on average, farther apart. For example, whereas the gene density (average number of genes per length of DNA) in E. coli is 1 gene per 1400 bp, that number drops to 1 gene per 9000 bp for the fruit fly Drosophila, and it is only 1 gene per 100,000 bp for humans. This low gene density makes the initiation step of transcription a much more complicated process. In the genomes of multicellular eukaryotes, finding the start of a gene can be like finding a needle in a haystack.
Page 302As you will see, eukaryotes deal with this situation in several ways. First, they have divided the job of transcription among three different polymerases.
a. RNA polymerase I transcribes rRNA genes (excluding 5S rRNA).
b. RNA polymerase II transcribes all protein-
encoding genes, for which the ultimate transcript is mRNA, and transcribes some snRNAs. c. RNA polymerase III transcribes the small functional RNA genes (such as the genes for tRNA, some snRNAs, and 5S rRNA).
In this section, we will focus our attention on RNA polymerase II.
Second, eukaryotes require the assembly of many proteins at a promoter before RNA polymerase II can begin to synthesize RNA. Some of these proteins, called general transcription factors (GTFs), bind before RNA polymerase II binds, whereas others bind afterward. The role of the GTFs and their interaction with RNA polymerase II will be described in the next section, on transcription initiation in eukaryotes.
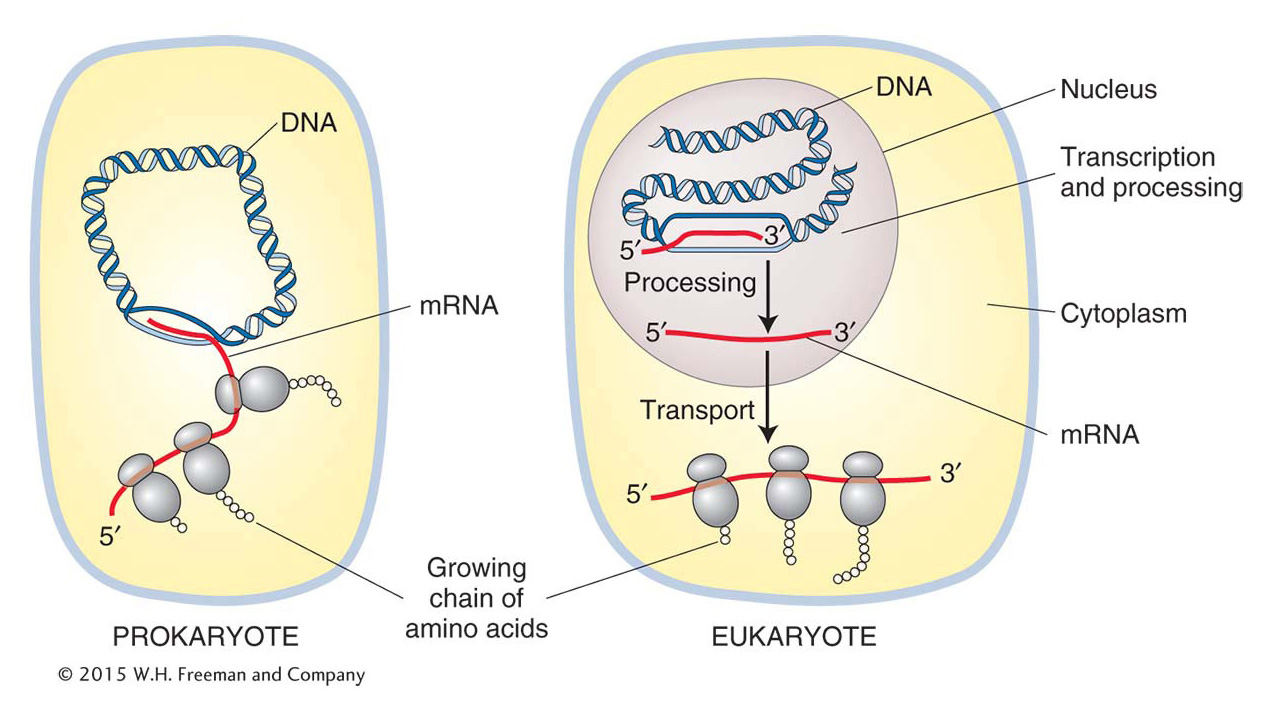
A significant difference between eukaryotes and prokaryotes is the presence of a nucleus in eukaryotes. In prokaryotes, which lack a nuclear membrane, the information in RNA is almost immediately translated into an amino acid chain (polypeptide), as we will see in Chapter 9. In eukaryotes, transcription and translation are spatially separated—
transcription takes place in the nucleus and translation in the cytoplasm (Figure 8-11). In eukaryotes, RNA is synthesized in the nucleus where the DNA is located and exported out of the nucleus into the cytoplasm for translation. Page 303Before the RNA leaves the nucleus, it must be modified in several ways. These modifications are collectively referred to as RNA processing. To distinguish the RNA before and after processing, newly synthesized RNA is called the primary transcript or pre-mRNA, and the term mRNA is reserved for the fully processed transcript that can be exported out of the nucleus. As you will see, the 5′ end of the RNA undergoes processing while the 3′ end is still being synthesized. Thus, RNA polymerase II must synthesize RNA while simultaneously coordinating a diverse array of processing events. For this reason, among others, RNA polymerase II is a more complicated multisubunit enzyme than prokaryotic RNA polymerase. In fact, it is considered to be another molecular machine. The coordination of RNA processing and synthesis by RNA polymerase II will be discussed in the section on transcription elongation in eukaryotes.
Finally, the template for transcription, genomic DNA, is organized into chromatin in eukaryotes (see Chapter 1), whereas it is virtually “naked” in prokaryotes. As you will learn in Chapter 12, certain chromatin structures can block the access of RNA polymerase to the DNA template. This feature of chromatin has evolved into a very sophisticated mechanism for regulating eukaryotic gene expression. However, a discussion of the influence of chromatin on the ability of RNA polymerase II to initiate transcription will be put aside until Chapter 12 as we focus on the events that take place after RNA polymerase II gains access to the DNA template.
Transcription initiation in eukaryotes
As stated earlier, transcription starts in prokaryotes when the σ subunit of the RNA polymerase holoenzyme recognizes the −10 and −35 regions in the promoter of a gene. After transcription begins, the σ subunit dissociates and the core polymerase continues to synthesize RNA within a transcription bubble that moves along the DNA. Similarly, in eukaryotes, the core of RNA polymerase II also cannot recognize promoter sequences on its own. However, unlike bacteria, where σ factor is an integral part of the polymerase holoenzyme, eukaryotes require GTFs to bind to regions in the promoter before the binding of the core enzyme.
The initiation of transcription in eukaryotes has some features that are reminiscent of the initiation of DNA replication at origins of replication. Recall from Chapter 7 that proteins that are not part of the replisome initiate the assembly of the replication machine. DnaA in E. coli and the origin recognition complex (ORC) in yeast, for example, first recognize and bind to origin DNA sequences. These proteins serve to attract replication proteins, including DNA polymerase III, through protein–
The GTFs and the RNA polymerase II core constitute the preinitiation complex (PIC). This complex is quite large: it contains six GTFs, each of which is a multiprotein complex, plus the RNA polymerase II core, which is made up of a dozen or more protein subunits. The sequence of amino acids of some of the RNA polymerase II core subunits is conserved from yeast to humans. This conservation can be dramatically demonstrated by replacing some yeast RNA polymerase II subunits with their human counterparts to form a chimeric RNA polymerase II complex (named after a fire-
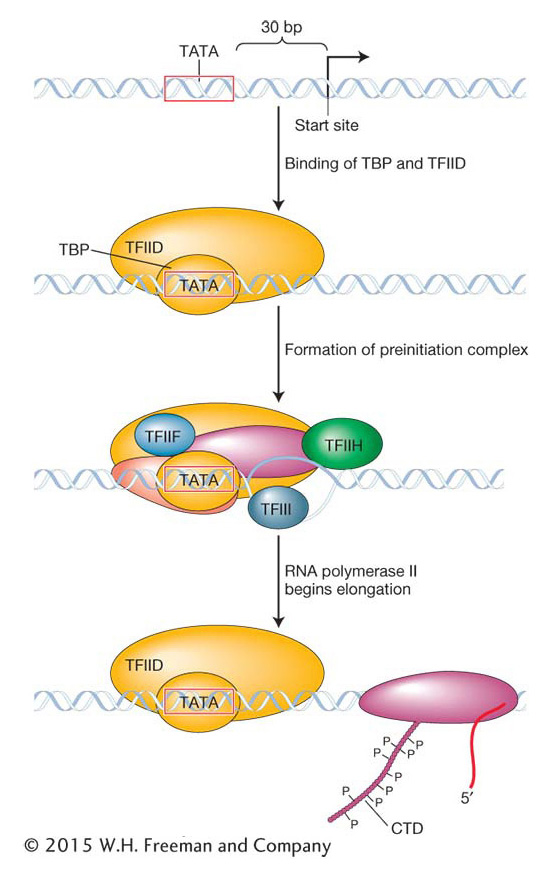
Like prokaryotic promoters, eukaryotic promoters are located on the 5′ side (upstream) of the transcription start site. When eukaryotic promoter regions from different species are aligned, the sequence TATA can often be seen to be located about 30 base pairs (−30 bp) from the transcription start site (Figure 8-12). This sequence, called the TATA box, is the site of the first event in transcription: the binding of the TATA-binding protein (TBP). The TBP is part of the TFIID complex, one of the six GTFs. When bound to the TATA box, TBP attracts other GTFs and the RNA polymerase II core to the promoter, thus forming the PIC. After transcription has been initiated, RNA polymerase II dissociates from most of the GTFs to elongate the primary RNA transcript. Some of the GTFs remain at the promoter to attract the next RNA polymerase core. In this way, multiple RNA polymerase II enzymes can simultaneously synthesize transcripts from a single gene.
How is the RNA polymerase II core able to separate from the GTFs and start transcription? Although the details of this process are still being worked out, what is known is that the β subunit of RNA polymerase II contains a protein tail, called the carboxy terminal domain (CTD), that plays a key role. The CTD is strategically located near the site at which nascent RNA will emerge from the polymerase. The initiation phase ends and the elongation phase begins after the CTD has been phosphorylated by one of the GTFs. This phosphorylation is thought to somehow weaken the connection of RNA polymerase II to the other proteins of the PIC and permit elongation. The CTD also participates in several other critical phases of RNA synthesis and processing.
KEY CONCEPT
Eukaryotic promoters are first recognized by general transcription factors (GTFs). The function of GTFs is to attract the core RNA polymerase II so that it is positioned to begin RNA synthesis at the transcription start site.Elongation, termination, and pre-mRNA processing in eukaryotes
Elongation takes place inside the transcription bubble essentially as described for the synthesis of prokaryotic RNA. However, nascent RNA has very different fates in prokaryotes and eukaryotes. In prokaryotes, translation begins at the 5′ end of the nascent RNA while the 3′ half is still being synthesized. In contrast, the RNA of eukaryotes must undergo further processing before it can be translated. This processing includes (1) the addition of a cap at the 5′ end, (2) splicing to eliminate introns, and (3) the addition of a 3′ tail of adenine nucleotides (polyadenylation).
Like DNA replication, the synthesis and processing of pre-
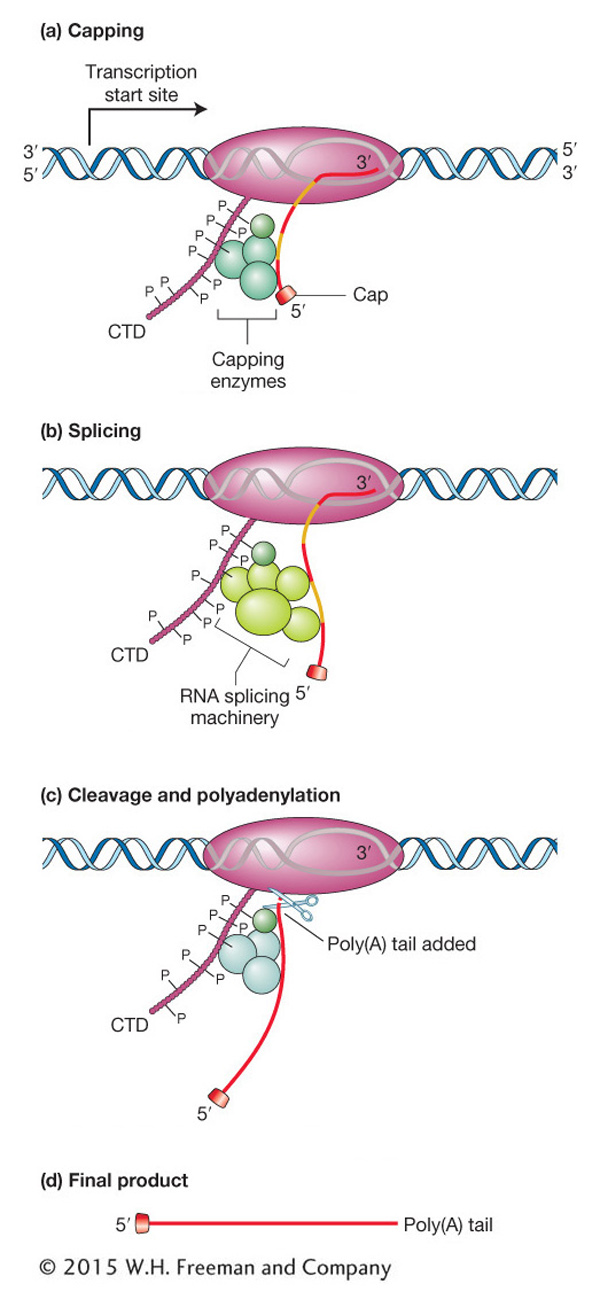
The CTD of eukaryotic RNA polymerase II plays a central role in coordinating all processing events. The CTD is composed of many repeats of a sequence of seven amino acids. These repeats serve as binding sites for some of the enzymes and other proteins that are required for RNA capping, splicing, and cleavage followed by polyadenylation. The CTD is located near the site where nascent RNA emerges from the polymerase, and so it is in an ideal place to orchestrate the binding and release of proteins needed to process the nascent RNA transcript while RNA synthesis continues. In the various phases of processing, the amino acids of the CTD are reversibly modified—
Processing 5′ and 3′ ends Figure 8-13a depicts the processing of the 5′ end of the transcript of a protein-
RNA elongation continues until the conserved sequence AAUAAA or AUUAAA is reached, marking the 3′ end of the transcript. An enzyme recognizes that sequence and cuts off the end of the RNA approximately 20 bases farther down. To this cut end, a stretch of 150 to 200 adenine nucleotides called a poly(A) tail is added (see Figure 8-13c). Hence, the AAUAAA sequence of the mRNA from protein-
RNA splicing, the removal of introns In 1977, a scientific study appeared titled “An amazing sequence arrangement at the 5′ end of adenovirus 2 messenger RNA.”1 Scientists are usually understated, at least in their publications, and the use of the word “amazing” indicated that something truly unexpected had been found. The laboratories of Richard Roberts and Phillip Sharp had independently discovered that the information encoded by eukaryotic genes (in their case, the gene of a virus that infects eukaryotic cells) can be fragmented into pieces of two types, exons and introns. As stated earlier, pieces that encode parts of proteins are exons, and pieces that separate exons are introns. Introns are present not only in protein-
Introns are removed from the primary transcript while RNA is still being transcribed and after the cap has been added but before the transcript is transported into the cytoplasm. The removal of introns and the joining of exons is called splicing because it is reminiscent of the way in which videotape or movie film can be cut and rejoined to delete a specific segment. Splicing brings together the coding regions, or exons, so that the mRNA now contains a coding sequence that is completely colinear with the protein that it encodes.
The number and size of introns vary from gene to gene and from species to species. For example, only about 200 of the 6300 genes in yeast have introns, whereas typical genes in mammals, including humans, have several. The average size of a mammalian intron is about 2000 nucleotides, and the average exon is about 200 nucleotides; thus, a larger percentage of the DNA in mammals encodes introns than exons. An extreme example is the human Duchenne muscular dystrophy gene. This gene has 79 exons and 78 introns spread across 2.5 million base pairs. When spliced together, its 79 exons produce an mRNA of 14,000 nucleotides, which means that introns account for the vast majority of the 2.5 million base pairs.
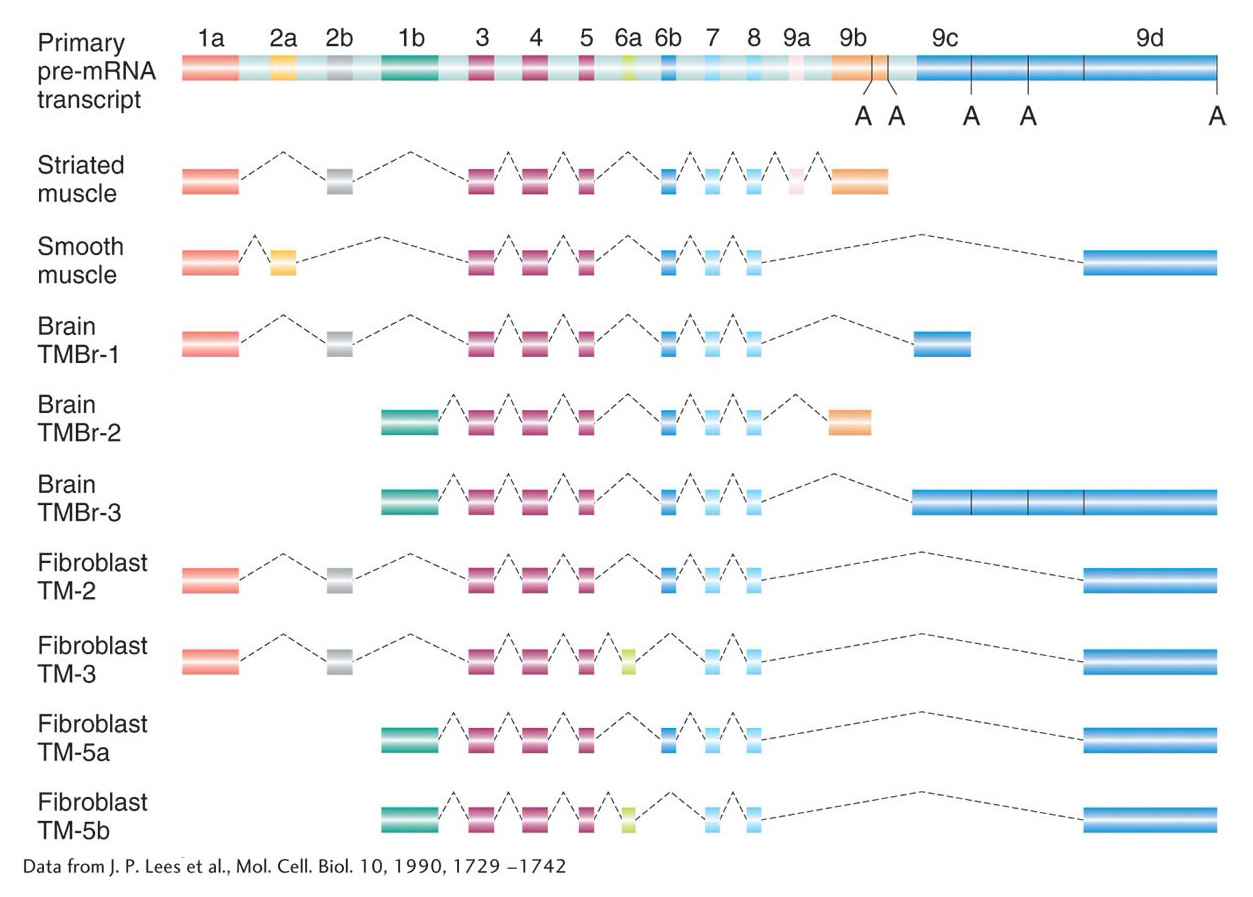
Alternative splicing At this point, you might be wondering about the utility of having genes organized into exons and introns. Recall that this chapter began with a discussion of the number of genes in the human genome. This number (now estimated at ~21,000 genes) is less than twice the number of genes in the roundworm, yet the spectrum of human proteins (called the proteome; see Chapter 9) is in excess of 70,000. That proteins so outnumber genes indicates that a gene can encode the information for more than one protein. One way that a gene can encode multiple proteins is through a process called alternative splicing. In this process, different mRNAs and, subsequently, different proteins are produced from the same primary transcript by splicing together different combinations of exons. For reasons that are currently unknown, the proportion of alternatively spliced genes varies from species to species. Although alternative splicing is rare in plants, more than 70 percent of human genes are alternatively spliced. Many mutations with serious consequences for the organism are due to splicing defects.
The consequences of alternative splicing on protein structure and function will be presented later in the book. For now, suffice it to say that proteins produced by alternative splicing are usually related (because they usually contain subsets of the same exons from the primary transcript) and that they are often used in different cell types or at different stages of development. Figure 8-14 shows the myriad combinations produced by alternative splicing of the primary RNA transcript of the α-tropomyosin gene. The mechanism of splicing is considered in the next section.