Nucleic Acids Carry Coded Information for Making Proteins at the Right Time and Place
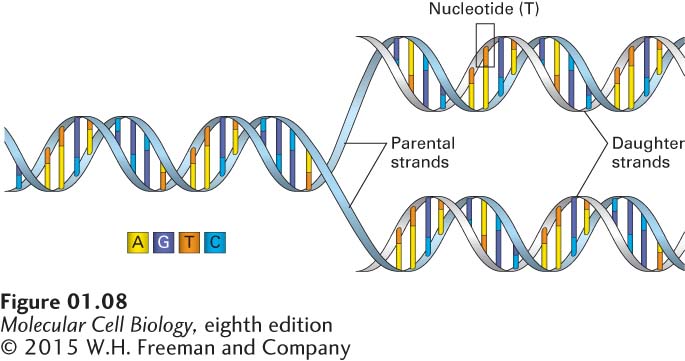
The macromolecule that garners the most public attention is deoxyribonucleic acid (DNA), whose functional properties make it the cell’s “master molecule.” The three-dimensional structure of DNA, first proposed by James D. Watson and Francis H. C. Crick in 1953, consists of two long helical strands that are coiled around a common axis to form a double helix (Figure 1-8). The double-helical structure of DNA, one of nature’s most magnificent constructions, is critical to the phenomenon of heredity, the transfer of genetically determined characteristics from one generation to the next.
FIGURE 1-8DNA consists of two complementary strands wound around each other to form a double helix. The double helix is stabilized by weak hydrogen bonds between the A and T bases and between the C and G bases. During replication, the two strands are unwound and used as templates to produce complementary strands. The outcome is two identical copies of the original double helix, each containing one of the original strands and one new daughter (complementary) strand.
Page 8
DNA strands are composed of monomers called nucleotides; these monomers are often referred to as bases because they contain cyclic organic bases (see Chapter 5). Four different nucleotides, abbreviated A, T, C, and G, are joined to form a DNA strand, with the base parts projecting inward from the backbone of the strand. Two strands bind together via the bases and twist to form a double helix. Each DNA double helix has a simple construction: wherever one strand has an A, the other strand has a T, and each C is matched with a G (see Figure 1-8). This complementary matching of the two strands is so strong that if complementary strands are separated under the right salt concentration and temperature conditions, they will spontaneously zip back together. This property is critical for DNA replication and inheritance, as we will learn in Chapter 5, and also underlies many of the techniques for studying DNA molecules that are detailed in Chapter 6.
The genetic information carried by DNA resides in its sequence, the linear order of nucleotides along a strand. Specific segments of DNA, termed genes, carry instructions for making specific proteins. Commonly, genes contain two parts: the coding region specifies the amino acid sequence of a protein; the regulatory region binds specific proteins and controls when and in which cells the gene’s protein is made.
Most bacteria have a few thousand protein-coding genes; yeasts and other unicellular eukaryotes have about 5000. Humans and other metazoans have between 13,000 and 23,000, while many plants have more. As we discuss later in this chapter, many of the genes in bacteria specify the sequences of proteins that catalyze reactions that occur universally, such as the metabolism of glucose and the synthesis of nucleic acids and proteins. These genes, and the proteins encoded by them, are conserved throughout all living organisms, and thus studies on the functions of these genes and proteins in bacterial cells have yielded profound insights into these basic life processes. Similarly, many genes in unicellular eukaryotes such as yeasts encode proteins that are conserved throughout all eukaryotes; we will see how yeasts have been used in studies of processes such as cell division that have yielded profound insights into human diseases such as cancer.
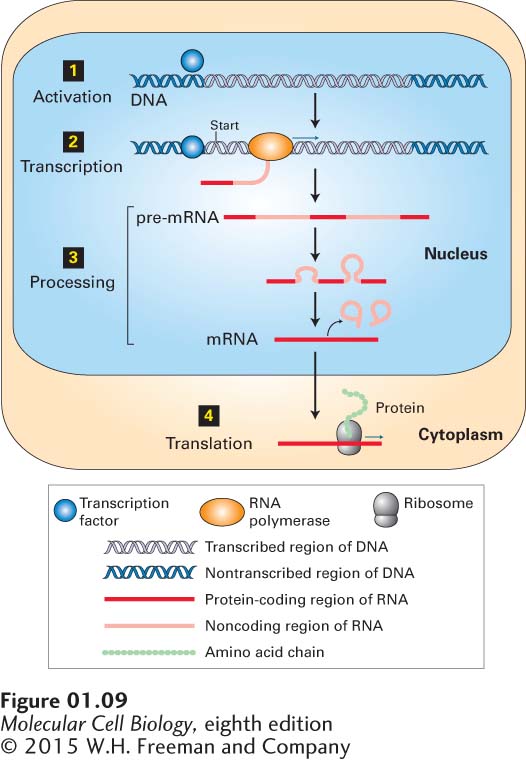
How is information stored in the sequence of DNA used? Cells use two processes in series to convert the coded information in DNA into proteins (Figure 1-9). In the first process, called transcription, the protein-coding region of a gene is copied into a single-stranded ribonucleic acid (RNA) whose sequence is the same as one of the two in the double-stranded DNA. A large enzyme, RNA polymerase, catalyzes the linkage of nucleotides into an RNA chain using DNA as a template. In eukaryotic cells, the initial RNA product is processed into a smaller messenger RNA (mRNA) molecule, which moves out of the nucleus to the cytoplasm, the region of the cell outside of the nucleus. Here the ribosome, an enormously complex molecular machine composed of both RNA and proteins, carries out the second process, called translation. During translation, the ribosome assembles and links together amino acids in the precise order dictated by the mRNA sequence according to the nearly universal genetic code. We examine the cell components that carry out transcription and translation in detail in Chapter 5.
FIGURE 1-9The information encoded in DNA is converted into the amino acid sequences of proteins by a multistep process. Step 1: Transcription factors and other proteins bind to the regulatory regions of the specific genes they control to activate those genes. Step 2: RNA polymerase begins transcription of an activated gene at a specific location, the start site. The polymerase moves along the DNA, linking nucleotides into a single-stranded pre-mRNA transcript using one of the DNA strands as a template. Step 3: The transcript is processed to remove noncoding sequences. Step 4: In a eukaryotic cell, the mature mRNA moves to the cytoplasm, where it is bound by ribosomes that read its sequence and assemble a protein by chemically linking amino acids into a linear chain.
In addition to its role in transferring information from nucleus to cytoplasm, RNA can serve as a framework for building a molecular machine. The ribosome, for example, is built of four RNA chains that bind to more than 50 proteins to make a remarkably precise and efficient mRNA reader and protein synthesizer. While most chemical reactions in cells are catalyzed by proteins, a few, such as the formation by ribosomes of the peptide bonds that connect amino acids in proteins, are catalyzed by RNA molecules.
Well before the entire human genome was sequenced, it was apparent that only about 10 percent of human DNA consists of protein-coding genes, and for many years the remaining 90 percent was considered “junk DNA”! In recent years, we’ve learned that much of the so-called junk DNA is actually copied into thousands of RNA molecules that, though they do not encode proteins, serve equally important purposes in the cell (see Chapter 10). At present, however, we know the function of only a very few of these abundant noncoding RNAs.
Like enzymes, certain RNA molecules, termed ribozymes, catalyze chemical reactions, as exemplified by the RNA inside a ribosome. Many scientists support the RNA world hypothesis, which proposes that RNA molecules that could replicate themselves were the precursors of current life forms; billions of years ago, the RNA world gradually evolved into the DNA, RNA, and protein world of today’s organisms.
Page 9
All organisms must control when and where their genes are transcribed. Nearly all the cells in our bodies contain the full set of human genes, but in each cell type only some of these genes are active, or turned on, and used to make proteins. For instance, liver cells produce some proteins that are not produced by kidney cells, and vice versa. Moreover, many cells respond to external signals or changes in external conditions by turning specific genes on or off, thereby adapting their repertoire of proteins to meet current needs. Such control of gene activity depends on DNA-binding proteins called transcription factors, which bind to specific sequences of DNA and act as switches, either activating or repressing transcription of particular genes, as discussed in Chapter 9.