11.2 One-Way Between-Groups ANOVA
The talking-
Everything About ANOVA but the Calculations
To introduce the steps of hypothesis testing for a one-
EXAMPLE 11.1
The researchers studied people in 15 societies from around the world. For teaching purposes, we’ll look at data from four types of societies—
Foraging. Several societies, including ones in Bolivia and Papua New Guinea, were categorized as foraging societies. They acquired most of their food through hunting and gathering.
Farming. Some societies, including ones in Kenya and Tanzania, primarily practiced farming and tended to grow their own food.
Natural resources. Other societies, such as in Colombia, built their economies by extracting natural resources, such as trees and fish. Most food was purchased.
Industrial. In industrial societies, which include the major city of Accra in Ghana as well as rural Missouri in the United States, most food was purchased.
The researchers wondered which groups would behave more or less fairly toward others—

This research design would be analyzed with a one-
Foraging: 28, 36, 38, 31
Farming: 32, 33, 40
Natural resources: 47, 43, 52
Industrial: 40, 47, 45
Let’s begin by applying a familiar framework: the six steps of hypothesis testing. We will learn the calculations in the next section.
STEP 1: Identify the populations, distribution, and assumptions.
The first step of hypothesis testing is to identify the populations to be compared, the comparison distribution, the appropriate test, and the assumptions of the test. Let’s summarize the fairness study with respect to this first step of hypothesis testing.
Summary: The populations to be compared: Population 1: All people living in foraging societies. Population 2: All people living in farming societies. Population 3: All people living in societies that extract natural resources. Population 4: All people living in industrial societies.
The comparison distribution and hypothesis test: The comparison distribution will be an F distribution. The hypothesis test will be a one-
Assumptions: (1) The data are not selected randomly, so we must generalize only with caution. (2) We do not know if the underlying population distributions are normal, but the sample data do not indicate severe skew. (3) We will test homoscedasticity when we calculate the test statistics by checking to see whether the largest variance is not more than twice the smallest. (Note: Don’t forget this step just because it comes later in the analysis.)
STEP 2: State the null and research hypotheses.
The second step is to state the null and research hypotheses. As usual, the null hypothesis posits no difference among the population means. The symbols are the same as before, but with more populations: H0: μ1 = μ2 = μ3 = μ4. However, the research hypothesis is more complicated because we can reject the null hypothesis if only one group is different, on average, from the others. The research hypothesis that μ1 ≠ μ2 ≠ μ3 ≠ μ4 does not include all possible outcomes, such as the hypothesis that the mean fairness scores for groups 1 and 2 are greater than the mean fairness scores for groups 3 and 4. The research hypothesis is that at least one population mean is different from at least one other population mean, so H1 is that at least one µ is different from another µ.
Summary: Null hypothesis: People living in societies based on foraging, farming, the extraction of natural resources, and industry all exhibit, on average, the same fairness behaviors—
STEP 3: Determine the characteristics of the comparison distribution.
The third step is to explicitly state the relevant characteristics of the comparison distribution. This step is an easy one in ANOVA because most calculations are in step 5. Here we merely state that the comparison distribution is an F distribution and provide the appropriate degrees of freedom. As we discussed, the F statistic is a ratio of two independent estimates of the population variance, between-
MASTERING THE FORMULA
11-
dfbetween = Ngroups − 1 = 4 − 1 = 3
Because there are four groups (foraging, farming, the extraction of natural resources, and industry), the between-
MASTERING THE FORMULA
11-
The sample within-
df1 = n1 − 1 = 4 − 1 = 3
n represents the number of participants in the particular sample. We would then do this for the remaining samples. For this example, there are four samples, so the formula would be:
dfwithin = df1 + df2 + df3 + df4
For this example, the calculations would be:
df1 = 4 − 1 = 3
df2 = 3 − 1 = 2
df3 = 3 − 1 = 2
df4 = 3 − 1 = 2
dfwithin = 3 + 2 + 2 + 2 = 9
Summary: We would use the F distribution with 3 and 9 degrees of freedom.
STEP 4: Determine the critical value, or cutoff.
The fourth step is to determine a critical value, or cutoff, indicating how extreme the data must be to reject the null hypothesis. For ANOVA, we use an F statistic, for which the critical value on an F distribution will always be positive (because the F is based on estimates of variance and variances are always positive). We determine the critical value by examining the F table in Appendix B (excerpted in Table 11-3). The between-
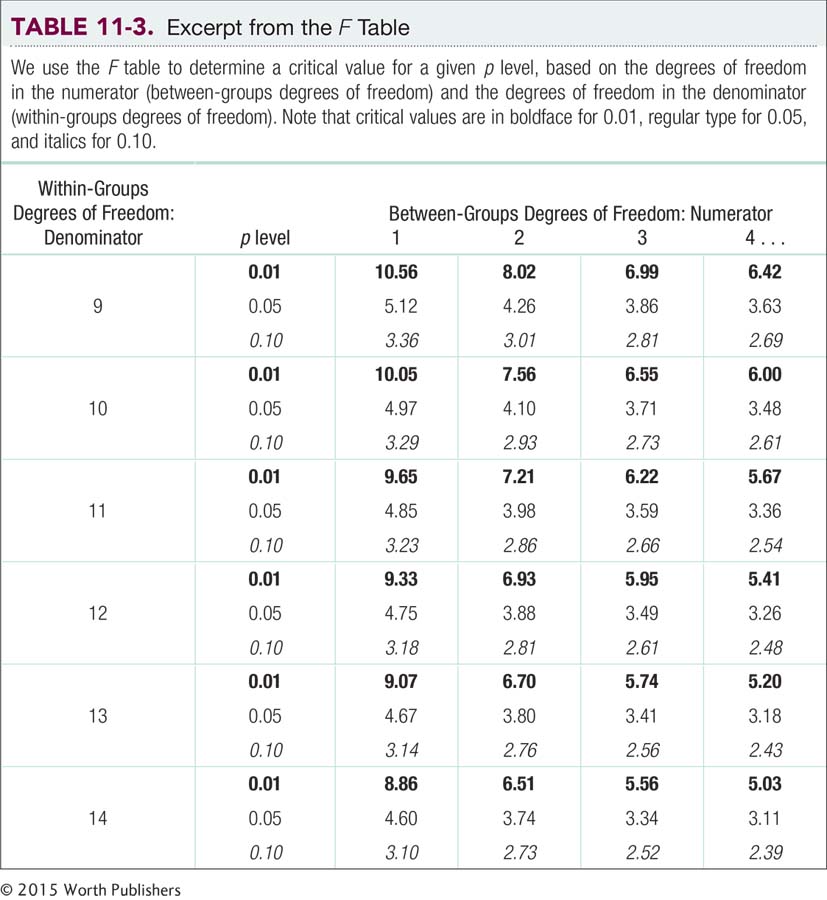
Use the F table by first finding the appropriate within-
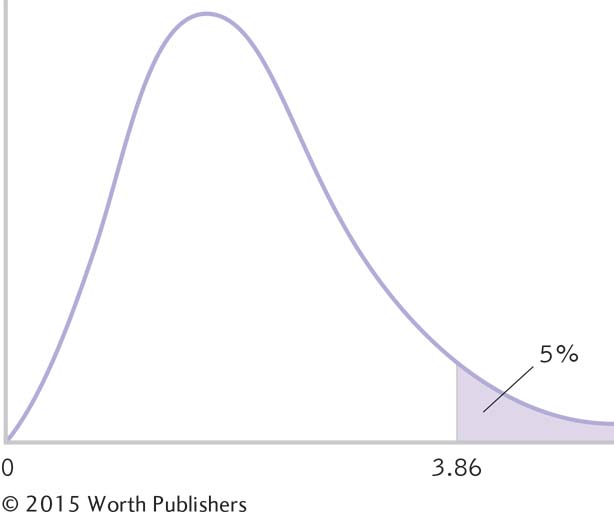
Determining Cutoffs for an F Distribution
We determine a single critical value on an F distribution. Because F is a squared version of a z (or t in some circumstances), we have only one cutoff for a two-
Summary: The cutoff, or critical value, for the F statistic for a p level of 0.05 is 3.86, as displayed in the curve in Figure 11-2.
STEP 5: Calculate the test statistic.
In the fifth step, we calculate the test statistic. We use the two estimates of the between-
Summary: To be calculated in the next section.
STEP 6: Make a decision.
In the final step, we decide whether to reject or fail to reject the null hypothesis. If the F statistic is beyond the critical value, then we know that it is in the most extreme 5% of possible test statistics if the null hypothesis is true. We can then reject the null hypothesis and conclude, “It seems that people exhibit different fairness behaviors, on average, depending on the type of society in which they live.” ANOVA only tells us that at least one mean is significantly different from another; it does not tell us which societies are different.
MASTERING THE CONCEPT
11-
If the test statistic is not beyond the critical value, then we must fail to reject the null hypothesis. The test statistic would not be very rare if the null hypothesis were true. In this circumstance, we report only that there is no evidence from the present study to support the research hypothesis.
Summary: Because the decision we will make must be evidence-
The Logic and Calculations of the F Statistic
In this section, we first review the logic behind ANOVA’s use of between-
As we noted before, grown men, on average, are slightly taller than grown women, on average. We call that “between-

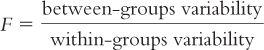
Quantifying Overlap with ANOVA On average, men are taller than women; however, many women are taller than many men, so their distributions overlap. The amount of overlap is influenced by the distance between the means (between-
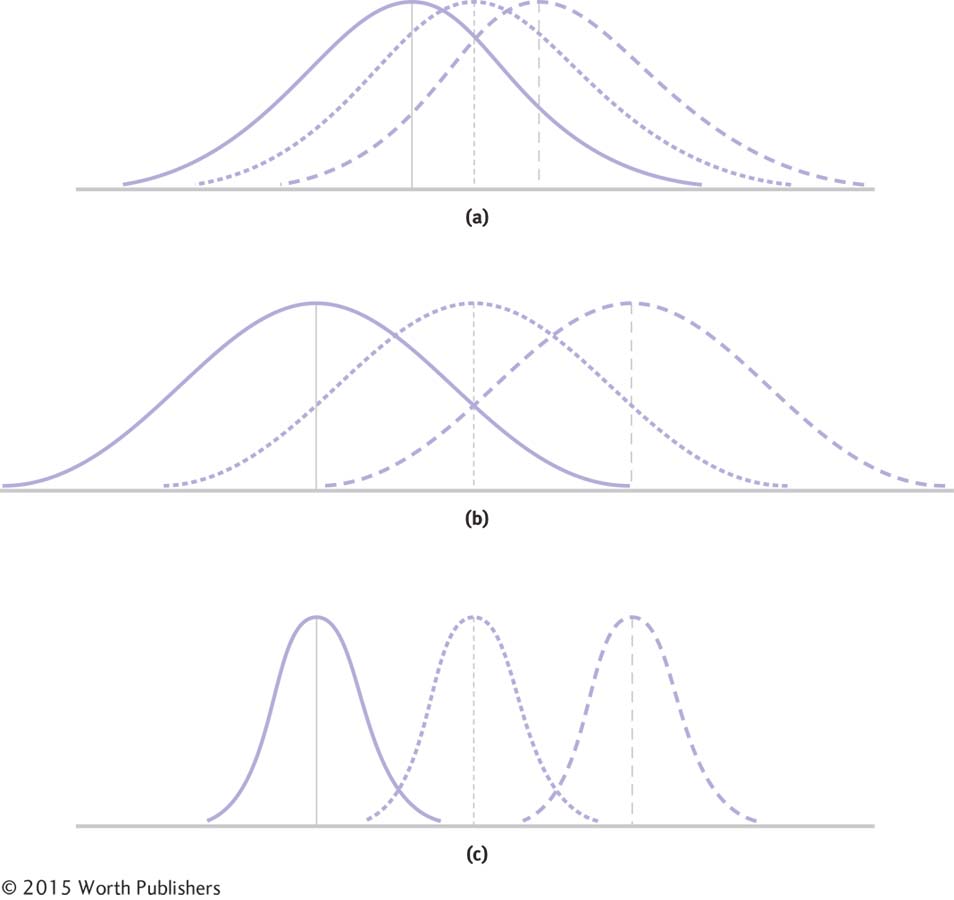
The Logic of ANOVA
Compare the top (a) and middle (b) sets of sample distributions. As the variability between means increases, the F statistic becomes larger. Compare the middle (b) and bottom (c) sets of sample distributions. As the variability within the samples themselves decreases, the F statistic becomes larger because there is less overlap between the three curves. Both the increased spread among the sample means and the decreased spread within each sample contribute to this increase in the F statistic.
There is less overlap in the second set of distributions (see Figure 11-3b), but only because the means are farther apart; the within-
There is even less overlap in the third set of distributions (see Figure 11-3c) because the numerator representing the between-
Two Ways to Estimate Population Variance Between-
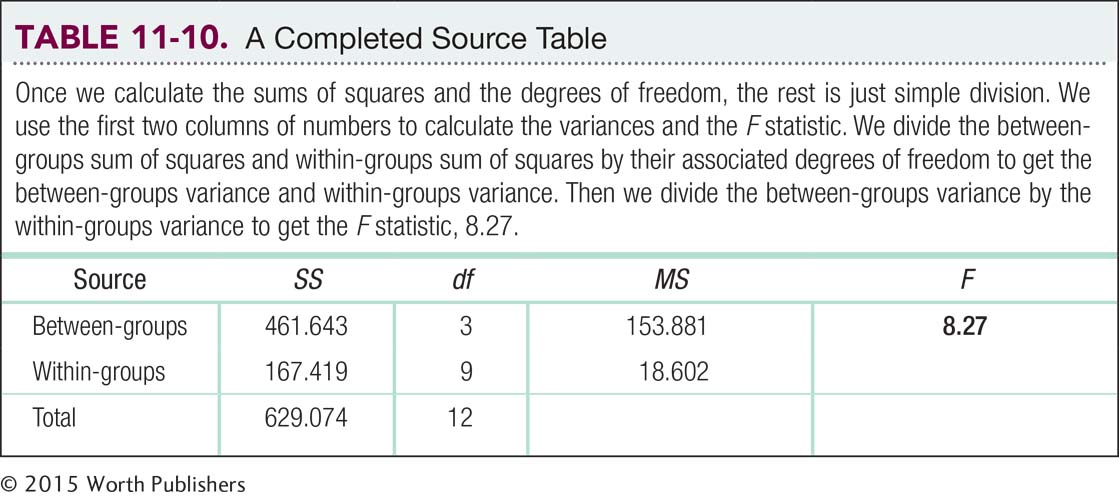
A source table presents the important calculations and final results of an ANOVA in a consistent and easy-
to- read format.
Calculating the F Statistic with the Source Table The goal of any statistical analysis is to understand the sources of variability in a study. We achieve that in ANOVA by calculating many squared deviations from the mean and three sums of squares. We organize the results into a source table that presents the important calculations and final results of an ANOVA in a consistent and easy-
Column 1: “Source.” One possible source of population variance comes from the spread between means; a second source comes from the spread within each sample. In this chapter, the row labeled “Total” allows us to check the calculations of the sum of squares (SS) and degrees of freedom (df). Now let’s work backward through the source table to learn how it describes these two familiar sources of variability.
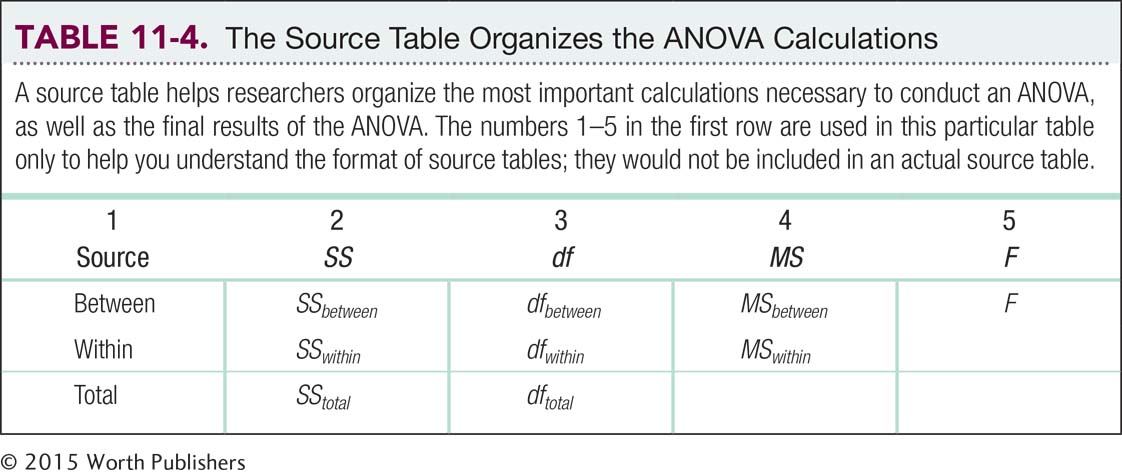
Column 5: “F.” We calculate F using simple division: between-
Column 4: “MS.” MS is the conventional symbol for variance in ANOVA. It stands for “mean square” because variance is the arithmetic mean of the squared deviations for between-
MASTERING THE FORMULA
11-
Column 3: “df.” We calculate the between-
dftotal = dfbetween + dfwithin
In our version of the fairness study, dftotal = 3 + 9 = 12. A second way to calculate dftotal is:
dftotal = Ntotal − 1
Ntotal refers to the total number of people in the entire study. In our abbreviated version of the fairness study, there were four groups, with 4, 3, 3, and 3 participants in the groups, and 4 + 3 + 3 + 3 = 13. We calculate total degrees of freedom for this study as dftotal = 13 − 1 = 12. If we calculate degrees of freedom both ways and the answers don’t match up, then we know we have to go back and check the calculations.
Column 2: “SS.” We calculate three sums of squares. One SS represents between-
The source table is a convenient summary because it describes everything we have learned about the sources of numerical variability. Once we calculate the sums of squares for between-
Step 1: Divide each sum of squares by the appropriate degrees of freedom—
Step 2: Calculate the ratio of MSbetween and MSwithin to get the F statistic. Once we have the sums of squared deviations, the rest of the calculation is simple division.
Sums of Squared Deviations Language Alert! The term “deviations” is another word used to describe variability. ANOVA analyzes three different types of statistical deviations: (1) deviations between groups, (2) deviations within groups, and (3) total deviations. We begin by calculating the sum of squares for each type of deviation, or source of variability: between, within, and total.
It is easiest to start with the total sum of squares, SStotal. Organize all the scores and place them in a single column with a horizontal line dividing each sample from the next. Use the data (from our version of the fairness study) in the column labeled “X” of Table 11-5 as a model; X stands for each of the 13 individual scores listed below. Each set of scores is next to its sample; the means are underneath the names of each respective sample. (We have included subscripts on each mean in the first column—
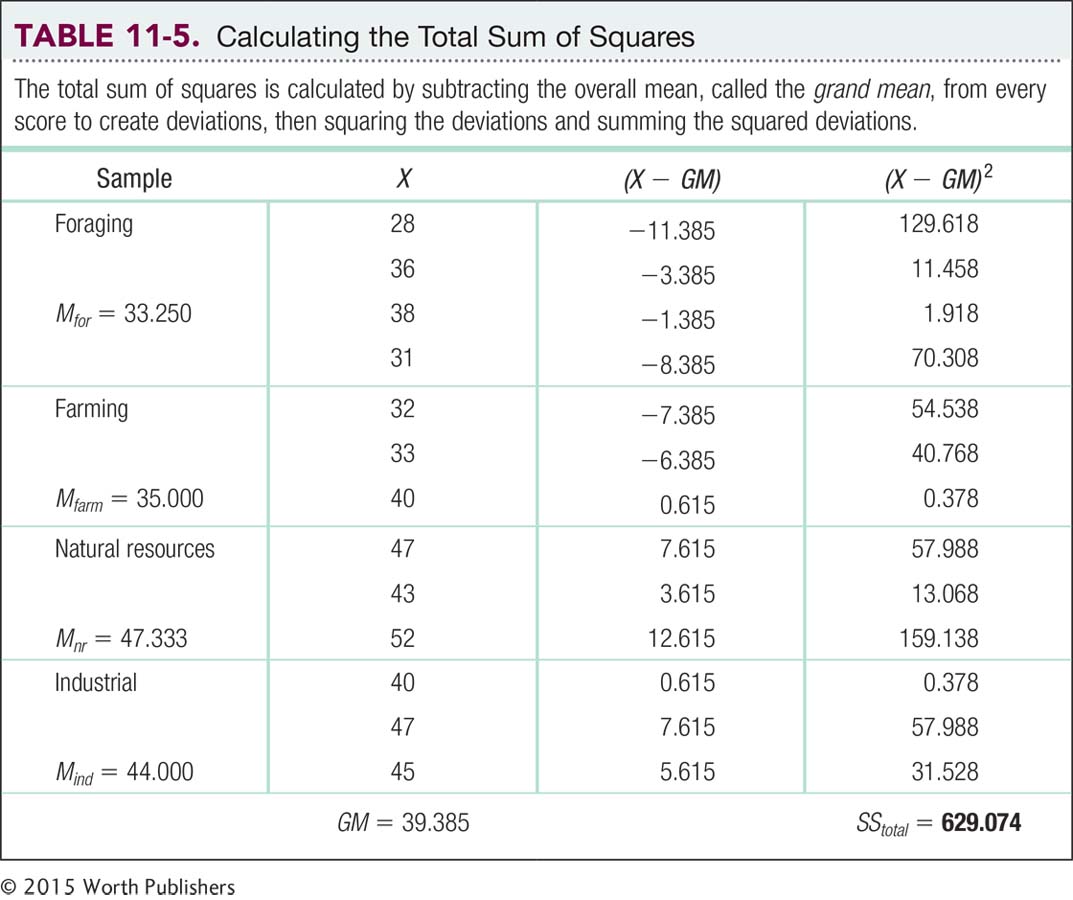
The grand mean is the mean of every score in a study, regardless of which sample the score came from.
To calculate the total sum of squares, subtract the overall mean from each score, including everyone in the study, regardless of sample. The mean of all the scores is called the grand mean, and its symbol is GM. The grand mean is the mean of every score in a study, regardless of which sample the score came from:
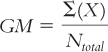
MASTERING THE FORMULA
11-
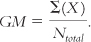
We add up everyone’s score, then divide by the total number of people in the study.
The grand mean of these scores is 39.385. (As usual, we write each number to three decimal places until we get to the final answer, F. We report the final answer to two decimal places.)
The third column in Table 11-5 shows the deviation of each score from the grand mean. The fourth column shows the squares of these deviations. For example, for the first score, 28, we subtract the grand mean:
28 − 39.385 = −11.385
Then we square the deviation:
MASTERING THE FORMULA
11-
(−11.385)2 = 129.618
Below the fourth column, we have summed the squared deviations: 629.074. This is the total sum of squares, SStotal. The formula for the total sum of squares is:
SStotal = Σ(X − GM)2
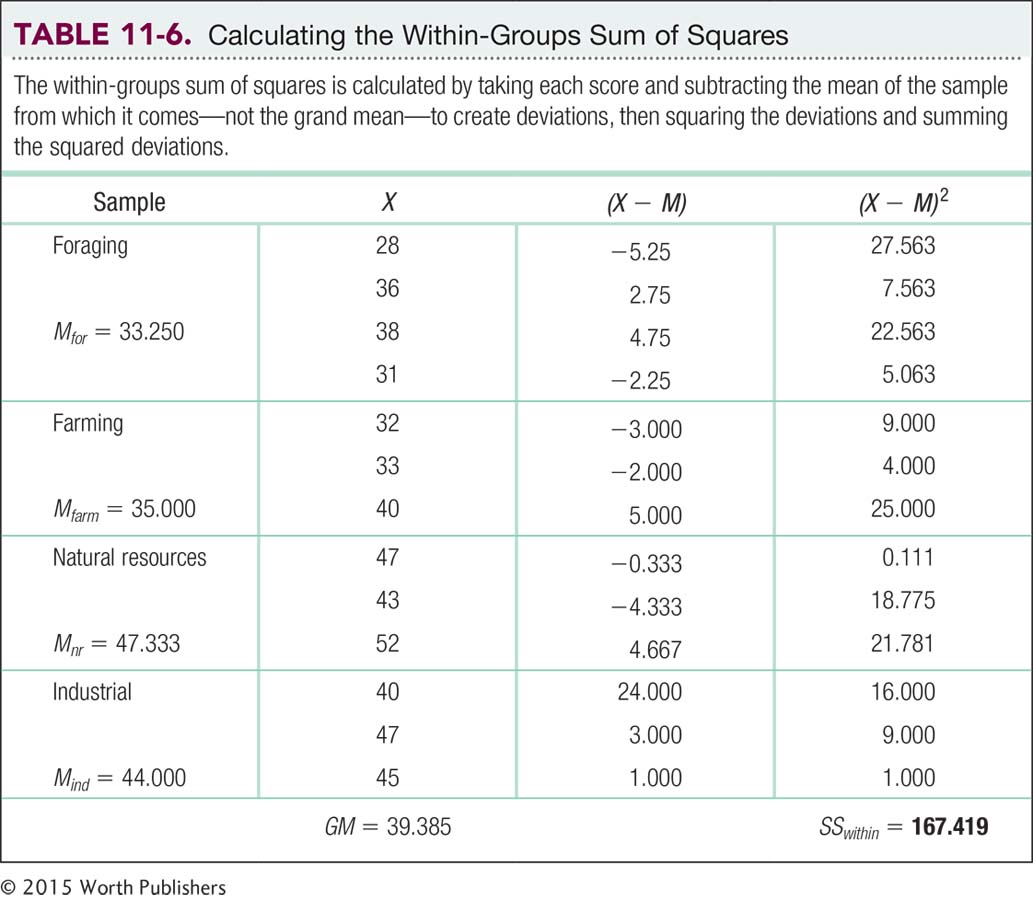
The model for calculating the within-
(28 − 33.25)2 = 27.563
MASTERING THE FORMULA
11-
For the three scores in the second sample, we subtract their sample mean, 35.0. And so on for all four samples. (Note: Don’t forget to switch means when you get to each new sample!)
Once we have all the deviations, we square them and sum them to calculate the within-
SSwithin = Σ(X − M)2
Notice how the weighting for sample size is built into the calculation: The first sample has four scores and contributes four squared deviations to the total. The other samples have only three scores, so they only contribute three squared deviations.
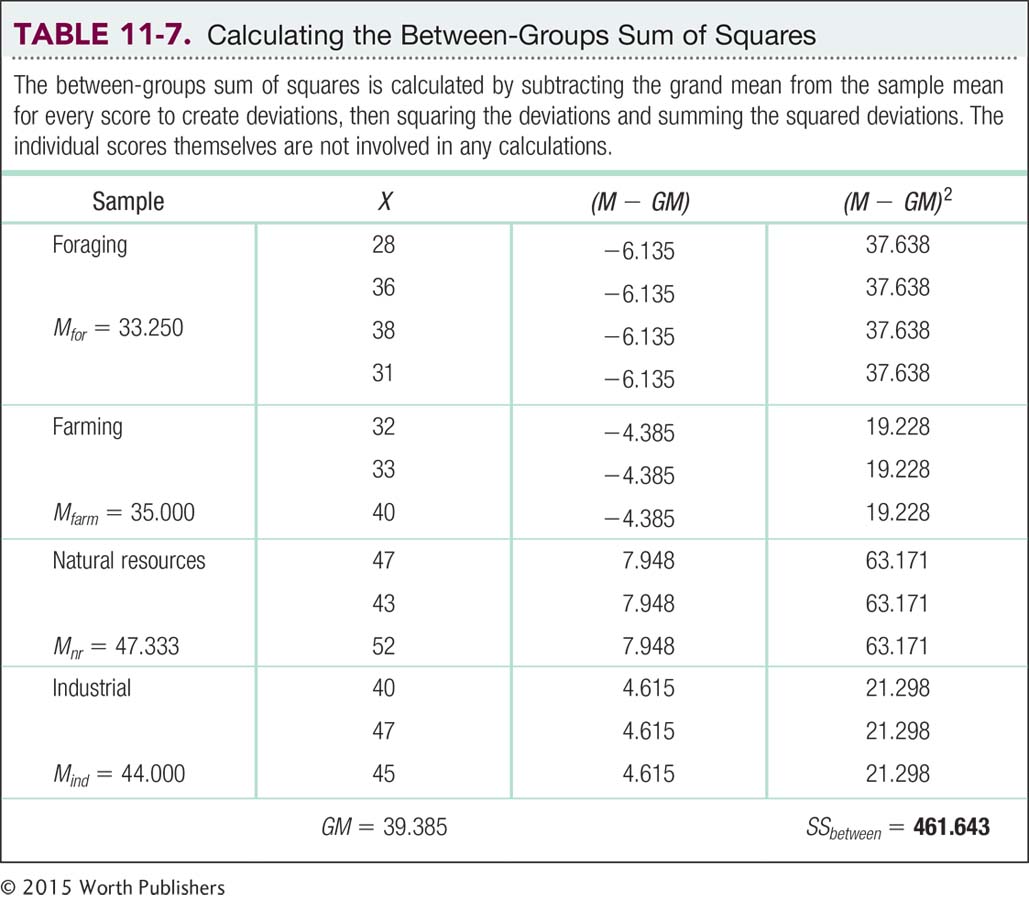
Finally, we calculate the between-
For example, the first person has a score of 28 and belongs to the group labeled “foraging,” which has a mean score of 33.25. The grand mean is 39.385. We ignore this person’s individual score and subtract 39.385 (the grand mean) from 33.25 (the group mean) to get the deviation score, −6.135. The next person, also in the group labeled “foraging,” has a score of 36. The group mean of that sample is 33.25. Once again, we ignore that person’s individual score and subtract 39.385 (the grand mean) from 33.25 (the group mean) to get the deviation score, also −6.135.
In fact, we subtract 39.385 from 33.25 for all four scores, as you can see in Table 11-7. When we get to the horizontal line between samples, we look for the next sample mean. For all three scores in the next sample, we subtract the grand mean, 39.385, from the sample mean, 35.0, and so on.
MASTERING THE FORMULA
11-
Notice that individual scores are never involved in the calculations, just sample means and the grand mean. Also notice that the first group (foraging), with four participants, has more weight in the calculation than the other three groups, which each have only three participants. The third column of Table 11-7 includes the deviations and the fourth includes the squared deviations. The between-
SSbetween = Σ (M − GM)2
Now is the moment of arithmetic truth. Were the calculations correct? To find out, we add the within-
SStotal = SSwithin + SSbetween = 629.062 = 167.419 + 461.643
Indeed, the total sum of squares, 629.074, is almost equal to the sum of the other two sums of squares, 167.419 and 461.643, which is 629.062. The slight difference is due to rounding decisions. So the calculations were correct.
MASTERING THE FORMULA
11-
To recap (Table 11-8), for the total sum of squares, we subtract the grand mean from each individual score to get the deviations. For the within-

MASTERING THE FORMULA
11-
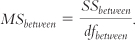
For the within-
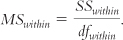
Now we insert these numbers into the source table to calculate the F statistic. See Table 11-9 for the source table that lists all the formulas and Table 11-10 for the completed source table. We divide the between-


MASTERING THE FORMULA
11-
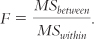
We divide the between-
We then divide the between-
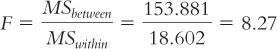
Making a Decision
Now we have to come back to the six steps of hypothesis testing for ANOVA to fill in the gaps in steps 1 and 6. We finished steps 2 through 5 in the previous section.
Step 1: ANOVA assumes that participants were selected from populations with equal variances. Statistical software, such as SPSS, tests this assumption while analyzing the overall data. For now, we can use the last column from the within-
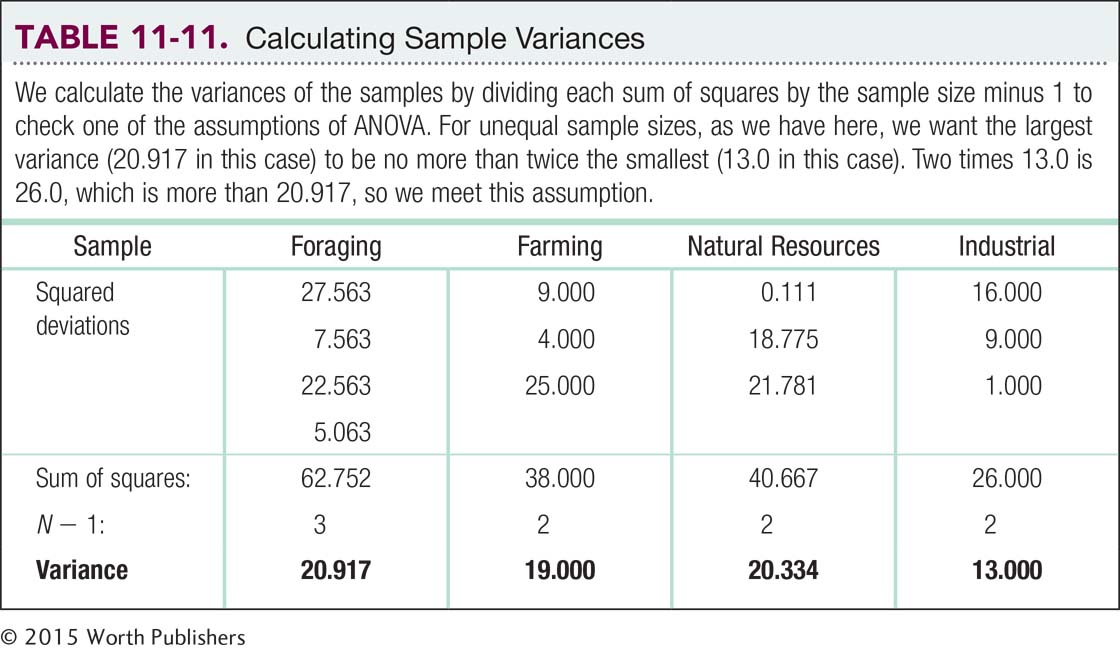
Step 6: Now that we have the test statistic, we compare it with 3.86, the critical F value that we identified in step 4. The F statistic we calculated was 8.27, and Figure 11-4 demonstrates that the F statistic is beyond the critical value: We can reject the null hypothesis. It appears that people living in some types of societies are fairer, on average, than are people living in other types of societies. And congratulations on making your way through your first ANOVA! Statistical software will do all of these calculations for you, but understanding how the computer produced those numbers adds to your overall understanding.
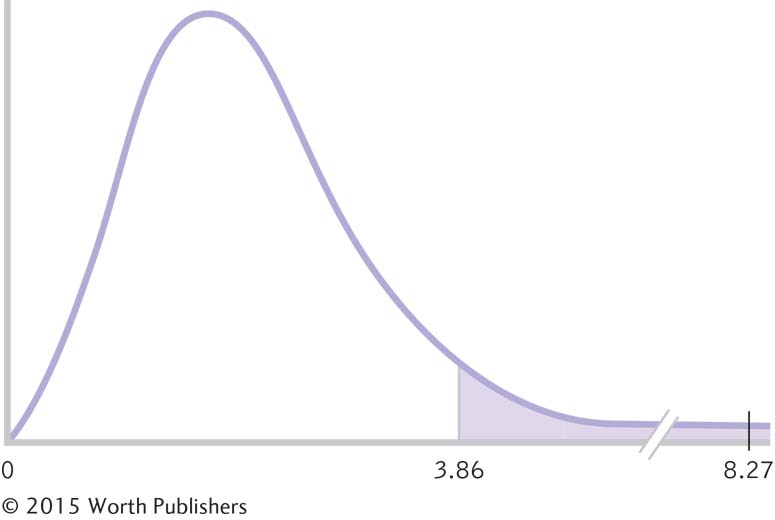
Making a Decision with an F Distribution
We compare the F statistic that we calculated for the samples to a single cutoff, or critical value, on the appropriate F distribution. We can reject the null hypothesis if the test statistic is beyond—
The ANOVA, however, only allows us to conclude that at least one mean is different from at least one other mean. The next section describes how to determine which groups are different.
Summary: We reject the null hypothesis. It appears that mean fairness levels differ based on the type of society in which a person lives. In a scientific journal, these statistics are presented in a similar way to the z and t statistics but with separate degrees of freedom in parentheses for between-
CHECK YOUR LEARNING
| Reviewing the Concepts |
|
|
| Clarifying the Concepts | 11- |
If the F statistic is beyond the cutoff, what does that tell us? What doesn’t that tell us? |
| 11- |
What is the primary subtraction that enters into the calculation of SSbetween? | |
| Calculating the Statistics | 11- |
Calculate each type of degrees of freedom for the following data, assuming a between- Group 1: 37, 30, 22, 29 Group 2: 49, 52, 41, 39 Group 3: 36, 49, 42
|
| 11- |
Using the data in Check Your Learning 11- |
|
| 11- |
Using the data in Check Your Learning 11-
|
|
| 11- |
Using all of your calculations in Check Your Learning 11- |
|
| Applying the Concepts | 11- |
Let’s create a context for the data provided above. Hollon, Thase, and Markowitz (2002) reviewed the efficacy of different treatments for depression, including medications, electroconvulsive therapy, psychotherapy, and placebo treatments. These data re- Group 1 (psychodynamic therapy): 37, 30, 22, 29 Group 2 (interpersonal therapy): 49, 52, 41, 39 Group 3 (cognitive-
|
Solutions to these Check Your Learning questions can be found in Appendix D.