15.2 The Pearson Correlation Coefficient
The Pearson correlation coefficient is a statistic that quantifies a linear relation between two scale variables.
The most widely used correlation coefficient is the Pearson correlation coefficient, a statistic that quantifies a linear relation between two scale variables. In other words, a single number is used to describe the direction and strength of the relation between two variables when their overall pattern indicates a straight-
Calculating the Pearson Correlation Coefficient
The correlation coefficient can be used as a descriptive statistic that describes the direction and strength of an association between two variables. However, it can also be used as an inferential statistic that relies on a hypothesis test to determine whether the correlation coefficient is significantly different from 0 (no correlation). In this section, we construct a scatterplot from the data and learn how to calculate the correlation coefficient. Then we walk through the steps of hypothesis testing.
EXAMPLE 15.3
Every couple of semesters, we have a student who avows that she does not have to attend statistics classes regularly to do well because she can learn it all from the book. What do you think? Table 15-2 displays the data for 10 students in one of our recent statistics classes. The second column shows the number of absences over the semester (out of 29 classes total) for each student, and the third column shows each student’s final exam grade.
| Student | Absences | Exam Grade |
|---|---|---|
| 1 | 4 | 82 |
| 2 | 2 | 98 |
| 3 | 2 | 76 |
| 4 | 3 | 68 |
| 5 | 1 | 84 |
| 6 | 0 | 99 |
| 7 | 4 | 67 |
| 8 | 8 | 58 |
| 9 | 7 | 50 |
| 10 | 3 | 78 |
398
MASTERING THE CONCEPT
15.4: A scatterplot can indicate whether two variables are linearly related. It can also give us a sense of the direction and strength of the relation between the two variables.
Let’s begin with a visual exploration of the scatterplot in Figure 15-6. The data, overall, have a pattern through which we could imagine drawing a straight line, so it makes sense to use the Pearson correlation coefficient. Look more closely at the scatterplot. Are the dots clustered closely around the imaginary line? If they are, then the correlation is probably close to 1.00 or −1.00; if they are not, then the correlation is probably closer to 0.00.
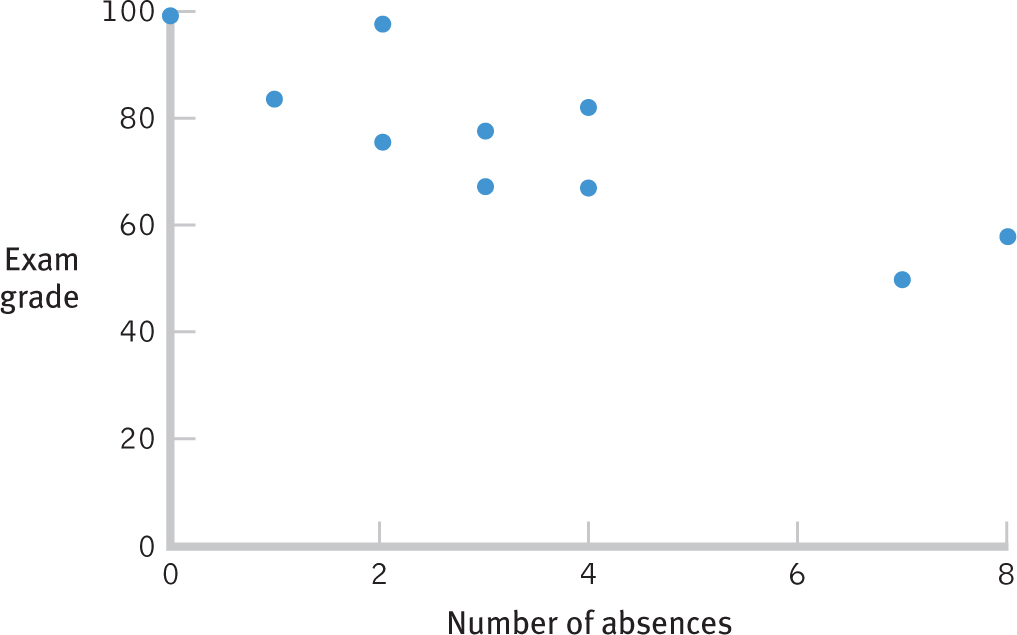
Figure 15-
A positive correlation results when a high score (above the mean) on one variable tends to indicate a high score (also above the mean) on the other variable. A negative correlation results when a high score (above the mean) on one variable tends to indicate a low score (below the mean) on the other variable. We can determine whether an individual falls above or below the mean by calculating deviations from the mean for each score. If participants tend to have two positive deviations (both scores above the mean) or two negative deviations (both scores below the mean), then the two variables are likely to be positively correlated. If participants tend to have one positive deviation (above the mean) and one negative deviation (below the mean), then the two variables are likely to be negatively correlated. That’s a big part of how the formula for the correlation coefficient does its work.
Think about why calculating deviations from the mean makes sense. With a positive correlation, high scores are above the mean and so would have positive deviations. The product of a pair of high scores would be positive. Low scores are below the mean and would have negative deviations. The product of a pair of low scores would also be positive. When we calculate a correlation coefficient, part of the process involves adding up the products of the deviations. If most of these are positive, we get a positive correlation coefficient.
Let’s consider a negative correlation. High scores, which are above the mean, would have positive deviations. Low scores, which are below the mean, would have negative deviations. The product of one positive deviation and one negative deviation would be negative. If most of the products of the deviations are negative, we would get a negative correlation coefficient.
The process we just described is the calculation of the numerator of the correlation coefficient. Table 15-3 shows us the calculations. The first column has the number of absences for each student. The second column shows the deviations from the mean, 3.40. The third column has the exam grade for each student. The fourth column shows the deviations from the mean for that variable, 76.00. The fifth column shows the products of the deviations. Below the fifth column, we see the sum of the products of the deviations, −304.0.
| Absences (X) | (X − MX) | Exam Grade (Y) | (Y − MY) | (X − MX)(Y − MY) |
|---|---|---|---|---|
| 4 | 0.6 | 82 | 6 | 3.6 |
| 2 | −1.4 | 98 | 22 | −30.8 |
| 2 | −1.4 | 76 | 0 | 0.0 |
| 3 | −0.4 | 68 | −8 | 3.2 |
| 1 | −2.4 | 84 | 8 | −19.2 |
| 0 | −3.4 | 99 | 23 | −78.2 |
| 4 | 0.6 | 67 | −9 | −5.4 |
| 8 | 4.6 | 58 | −18 | −82.8 |
| 7 | 3.6 | 50 | −26 | −93.6 |
| 3 | −0.4 | 78 | 2 | −0.8 |
| MX = 3.400 MY = 76.000 Σ[(X 2 MX)(Y 2 MY)] = −304.0 | ||||
As we see in Table 15-3, the pairs of scores tend to fall on either side of the mean—
399
You might have noticed that this number, −304.0, is not between −1.00 and 1.00. The problem is that this number is influenced by two factors—
It makes sense that we would have to correct for variability. In Chapter 6, we learned that z scores provide an important function in statistics by allowing us to standardize. You may remember that the formula for the z score that we first learned was 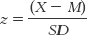 . In the calculations in the numerator for correlation, we already subtracted the mean from the scores when we created deviations, but we didn’t divide by the standard deviation. If we correct for variability in the denominator, that takes care of one of the two factors for which we have to correct.
. In the calculations in the numerator for correlation, we already subtracted the mean from the scores when we created deviations, but we didn’t divide by the standard deviation. If we correct for variability in the denominator, that takes care of one of the two factors for which we have to correct.
But we also have to correct for sample size. You may remember that when we calculate standard deviation, the last two steps are (1) dividing the sum of squared deviations by the sample size, N, to remove the influence of the sample size and to calculate variance; and (2) taking the square root of the variance to get the standard deviation. So to factor in sample size along with standard deviation (which we just mentioned allows us to factor in variability), we can go backward in the calculations. If we multiply variance by sample size, we get the sum of squared deviations, or sum of squares. Because of this, the denominator of the correlation coefficient is based on the sums of squares for both variables. To make the denominator match the numerator, we multiply the two sums of squares together, and then we take their square root, as we would with standard deviation. Table 15-4 shows the calculations for the sum of squares for the two variables, absences and exam grades.
| Absences (X) | (X − MX) | (X − MX)2 | Exam Grade (Y) | (Y − MY) | (Y − MY)2 |
|---|---|---|---|---|---|
| 4 | 0.6 | 0.36 | 82 | 6 | 36 |
| 2 | −1.4 | 1.96 | 98 | 22 | 484 |
| 2 | −1.4 | 1.96 | 76 | 0 | 0 |
| 3 | −0.4 | 0.16 | 68 | −8 | 64 |
| 1 | −2.4 | 5.76 | 84 | 8 | 64 |
| 0 | −3.4 | 11.56 | 99 | 23 | 529 |
| 4 | 0.6 | 0.36 | 67 | −9 | 81 |
| 8 | 4.6 | 21.16 | 58 | −18 | 324 |
| 7 | 3.6 | 12.96 | 50 | −26 | 676 |
| 3 | −0.4 | 0.16 | 78 | 2 | 4 |
| ∑ (X − MX)2 = 56.4 ∑ (Y − MY)2 = 2262 | |||||
We now have all of the ingredients necessary to calculate the correlation coefficient. Here’s the formula:
MASTERING THE FORMULA
15-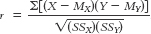 . We divide the sum of the products of the deviations for each variable by the square root of the products of the sums of squares for each variable. This calculation has a built-
. We divide the sum of the products of the deviations for each variable by the square root of the products of the sums of squares for each variable. This calculation has a built-
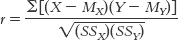
The numerator is the sum of the products of the deviations for each variable (see Table 15-3).
400
STEP 1: For each score, calculate the deviation from its mean.
STEP 2: For each participant, multiply the deviations for his or her two scores.
STEP 3: Sum the products of the deviations.
The denominator is the square root of the product of the two sums of squares. The sums of squares calculations are in Table 15-4.
STEP 1: Calculate a sum of squares for each variable.
STEP 2: Multiply the two sums of squares.
STEP 3: Take the square root of the product of the sums of squares.
Let’s apply the formula for the correlation coefficient to the data:
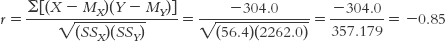
So the Pearson correlation coefficient, r, is −0.85. This is a very strong negative correlation. If we examine the scatterplot in Figure 15-6 carefully, we notice that there aren’t any glaring individual exceptions to this rule. The data tell a consistent story. So what should our students learn from this result? Go to class!
401
Hypothesis Testing with the Pearson Correlation Coefficient
We said earlier that correlation could be used as a descriptive statistic to simply describe a relation between two variables, and as an inferential statistic.
EXAMPLE 15.4
Here we outline the six steps for hypothesis testing with a correlation coefficient. Usually, when we conduct hypothesis testing with correlation, we want to test whether a correlation is statistically significantly different from no correlation—
MASTERING THE CONCEPT
15.5: As with other statistics, we can conduct hypothesis testing with the correlation coefficient. We compare the correlation coefficient to critical values on the r distribution.
STEP 1: Identify the populations, distribution, and assumptions.
Population 1: Students like those whom we studied in Example 15.3. Population 2: Students for whom there is no correlation between number of absences and exam grade.
The comparison distribution is a distribution of correlations taken from the population, but with the characteristics of our study, such as a sample size of 10. In this case, it is a distribution of all possible correlations between the numbers of absences and exam grades when 10 students are considered.
The first two assumptions are like those for other parametric tests. (1) The data must be randomly selected, or external validity will be limited. In this case, we do not know how the data were selected, so we should generalize with caution. (2) The underlying population distributions for the two variables must be approximately normal. In our study, it’s difficult to tell if the distribution is normal because we have so few data points.
The third assumption is specific to correlation: Each variable should vary equally, no matter the magnitude of the other variable. That is, number of absences should show the same amount of variability at each level of exam grade; conversely, exam grade should show the same amount of variability at each number of absences. You can get a sense of this by looking at the scatterplot in Figure 15-7. In our study, it’s hard to determine whether the amount of variability is the same for each variable across all levels of the other variable because we have so few data points. But it seems as if there’s variability of between 10 and 20 points on exam grade at each number of absences. The center of that variability decreases as we increase in number of absences, but the range stays roughly the same. It also seems that there’s variability of between 2 and 3 absences at each exam grade. Again, the center of that variability decreases as exam grade increases, but the range stays roughly the same.
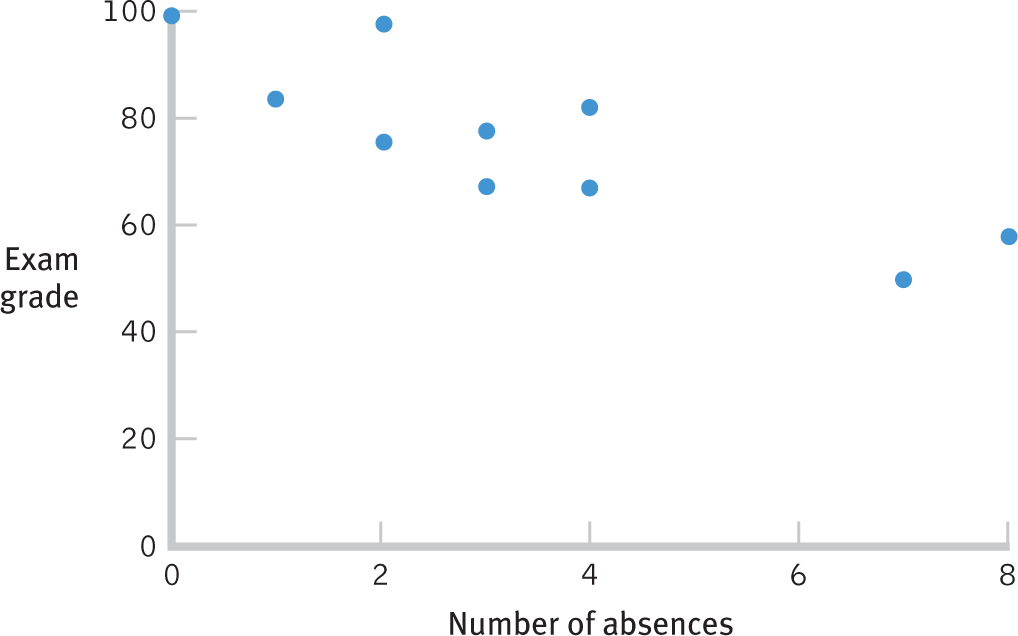
Figure 15-
402
STEP 2: State the null and research hypotheses.
Null hypothesis: There is no correlation between number of absences and exam grade—
STEP 3: Determine the characteristics of the comparison distribution.
The comparison distribution is an r distribution with degrees of freedom calculated by subtracting 2 from the sample size, which for Pearson correlation is the number of participants rather than the number of scores:
MASTERING THE FORMULA
15-
dfr = N − 2
In our study, degrees of freedom are calculated as follows:
dfr = N − 2 = 10 − 2 = 8
So the comparison distribution is an r distribution with 8 degrees of freedom.
STEP 4: Determine the critical values, or cutoffs.
Now we can look up the critical values in the r table in Appendix B. Like the z table and the t table, the r table includes only positive values. For a two-
STEP 5: Calculate the test statistic.
We already calculated the test statistic, r, in the preceding section. It is −0.85.
STEP 6: Make a decision.
The test statistic, r = −0.85, is larger in magnitude than the critical value of −0.632. We can reject the null hypothesis and conclude that number of absences and exam grade seem to be negatively correlated.
CHECK YOUR LEARNING
Reviewing the Concepts
- The Pearson correlation coefficient allows us to quantify the relations that we observe.
- Before we calculate a Pearson correlation coefficient, we should always construct a scatterplot to be sure the two variables are linearly related.
- The Pearson correlation coefficient is calculated in three basic steps. (1) Calculate the deviation of each score from its mean, multiply the two deviations for each person, and sum the products of the deviations. (2) Calculate a sum of squares for each variable, multiply the sums of squares, and take the square root. (3) Divide the sum from step 1 by the square root in step 2.
- We use the six steps of hypothesis testing to determine whether the correlation coefficient is statistically significantly different from 0 on an r distribution.
Clarifying the Concepts
- 15-
6 Define the Pearson correlation coefficient. - 15-
7 The denominator of the correlation equation corrects for which two issues present in the calculation of the numerator?
403
Calculating the Statistics
- 15-
8 Create a scatterplot for the following data:Variable A Variable B 8.0 14.0 7.0 13.0 6.0 10.0 5.0 9.5 4.0 8.0 5.5 9.0 6.0 12.0 8.0 11.0 - 15-
9 Calculate the correlation coefficient for the data provided in Check Your Learning 15-8.
Applying the Concepts
- 15-
10 According to social learning theory, children exposed to aggressive behavior, including family violence, are more likely to engage in aggressive behavior than are children who do not witness such violence. Let’s assume the data you worked with in Check Your Learning 15-8 and 15- 9 represent exposure to violence as the first variable, (A), and aggressive behavior as the second variable, (B). For both variables, higher values indicate higher levels, either of exposure to violence or of incidents of aggressive behavior. You computed the correlation coefficient, step 5 in hypothesis testing, in Check Your Learning 15- 9. Now, complete steps 1, 2, 3, 4, and 6 of hypothesis testing.
Solutions to these Check Your Learning questions can be found in Appendix D.