7.2 Operant Conditioning: Reinforcements from the Environment
The study of classical conditioning is the study of behaviours that are already in an organism’s repertoire. The animal already knows how to salivate, or feel anxious, fearful, or nauseated. Classical conditioning allows these behaviours to be triggered by new stimuli in the environment, but does not change the form of the behaviour. Classical conditioning is all about the stimuli (like CSs and USs) that come before a response and trigger it; it has nothing to say about how stimuli that come after a response (such as rewards, and punishments) might exert control over behaviour. So how does an animal learn new behaviours?
We turn now to a different form of learning: operant conditioning a type of learning in which the consequences of an organism’s behaviour determine the likelihood of that behaviour being repeated in the future. The study of operant conditioning is the exploration of the powerful effects of reward and punishment on behaviour.
7.2.1 The Development of Operant Conditioning: The Law of Effect

The study of how active behaviour affects the environment began at about the same time as classical conditioning. In fact, Edward L. Thorndike (1874–
What is the relationship between behaviour and reward?
Fairly quickly, the cats became quite skilled at triggering the lever for their release. Notice what is going on. At first, the cat enacts any number of likely (but ultimately ineffective) behaviours, but only one behaviour leads to freedom and food. Over time, the ineffective behaviours become less and less frequent, and the one instrumental behaviour (going right for the latch) becomes more frequent (see FIGURE 7.6). From these observations, Thorndike developed the law of effect: Behaviours that are followed by a “satisfying state of affairs” tend to be repeated and those that produce an “unpleasant state of affairs” are less likely to be repeated.
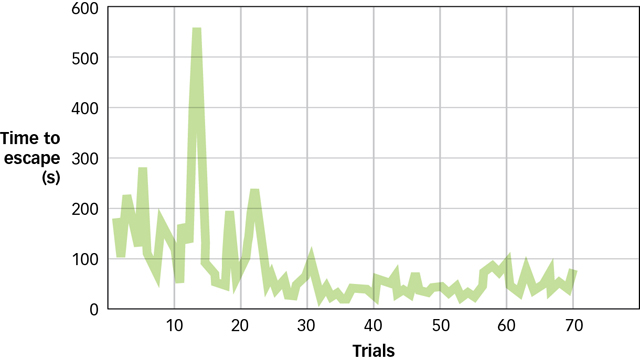
The circumstances that Thorndike used to study learning were very different from those in studies of classical conditioning. Remember that in classical conditioning experiments, the experimenter provides the stimuli (CS and/or US) and then the animal responds. But in Thorndike’s work, the behaviour of the animal determined what happened next. If the behaviour was “correct” (i.e., the latch was triggered), the animal was rewarded with food. Incorrect behaviours produced no results and the animal was stuck in the box until it performed the correct behaviour. Although different from classical conditioning, Thorndike’s work resonated with most behaviourists at the time: It was still observable, quantifiable, and free from explanations involving the mind (Galef, 1998).
7.2.2 B. F. Skinner: The Role of Reinforcement and Punishment

Several decades after Thorndike’s work, B. F. Skinner (1904–
In order to study operant behaviour scientifically, Skinner developed a variation on Thorndike’s puzzle box. The operant conditioning chamber, or Skinner box, as it is commonly called (shown in FIGURE 7.7 on the next page), allows a researcher to study the behaviour of small organisms in a controlled environment.

Skinner’s approach to the study of learning focused on reinforcement and punishment. These terms, which have commonsense connotations, turned out to be rather difficult to define. For example, some people love roller coasters, whereas others find them horrifying; the chance to go on one will be reinforcing for one group but punishing for another. Dogs can be trained with praise and a good belly rub—
Whether a particular stimulus acts as a reinforcer or a punisher depends in part on whether it increases or decreases the likelihood of a behaviour. Presenting food is usually reinforcing and produces an increase in the behaviour that led to it; removing food is often punishing and leads to a decrease in the behaviour. Turning on an electric shock is typically punishing (and decreases the behaviour that led to it); turning it off is rewarding (and increases the behaviour that led to it).
To keep these four possibilities distinct, Skinner used the term positive for situations in which a stimulus was presented and negative for situations in which it was removed. Consequently, there is both positive reinforcement (where a rewarding stimulus is presented) and negative reinforcement (where an unpleasant stimulus is removed), as well as positive punishment (where an unpleasant stimulus is administered) and negative punishment (where a rewarding stimulus is removed). Here the words positive and negative mean, respectively, something that is added or something that is taken away, but do not mean “good” or “bad” as they do in everyday speech. As you can see from TABLE 7.1, positive and negative reinforcement increase the likelihood of the behaviour; positive and negative punishment decrease the likelihood of the behaviour.
|
|
Increases the Likelihood of Behaviour |
Decreases the Likelihood of Behaviour |
|---|---|---|
|
Stimulus is presented |
Positive reinforcement |
Positive punishment |
|
Stimulus is removed |
Negative reinforcement |
Negative punishment |
These distinctions can be confusing at first; after all, “negative reinforcement” and “punishment” both sound like they should be “bad” and produce the same type of behaviour. However, negative reinforcement involves something “good”: it is the removal of something unpleasant, like a shock, and the absence of a shock is indeed pleasant.
Why is reinforcement more constructive than punishment in learning desired behaviour?
Reinforcement is generally more effective than punishment in promoting learning. There are many reasons (Gershoff, 2002), but one reason is this: Punishment signals that an unacceptable behaviour has occurred, but it does not specify what should be done instead. Spanking a young child for starting to run into a busy street certainly stops the behaviour, but it does not promote any kind of learning about the desired behaviour such as teaching the child to look both ways before stepping into the street.
7.2.2.1 Primary and Secondary Reinforcement and Punishment

Reinforcers and punishers often gain their functions from basic biological mechanisms. A pigeon that pecks at a target in a Skinner box is usually reinforced with food pellets, just as an animal who learns to escape a mild electric shock has avoided the punishment of tingly paws. Food, comfort, shelter, or warmth are examples of primary reinforcers because they help satisfy biological needs. However, the vast majority of reinforcers or punishers in our daily lives have little to do with biology: Verbal approval, a bronze trophy, or money all serve powerful reinforcing functions, yet none of them taste very good or help keep you warm at night. The point is, we learn to perform a lot of behaviours based on reinforcements that have little or nothing to do with biological satisfaction.
These secondary reinforcers derive their effectiveness from their associations with primary reinforcers through classical conditioning. For example, money starts out as a neutral CS that, through its association with primary USs like acquiring food or shelter, takes on a conditioned emotional element. Flashing lights, originally a neutral CS, acquire powerful negative elements through association with a speeding ticket and a fine.
7.2.2.2 Immediate versus Delayed Reinforcement and Punishment
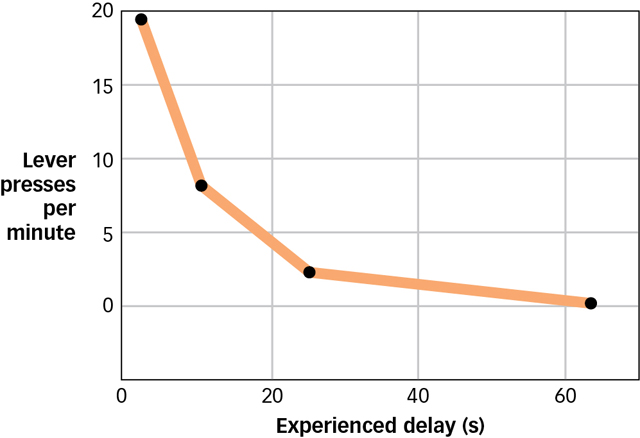
A key determinant of the effectiveness of a reinforcer is the amount of time between the occurrence of a behaviour and the reinforcer: The more time that elapses, the less effective the reinforcer (Lattal, 2010; Renner, 1964). This was dramatically illustrated in experiments with hungry rats in which food reinforcers were given at varying times after the rat pressed the lever (Dickinson, Watt, & Griffiths, 1992). Delaying reinforcement by even a few seconds led to a reduction in the number of times the rat subsequently pressed the lever, and extending the delay to a minute rendered the food reinforcer completely ineffective (see FIGURE 7.8). The most likely explanation for this effect is that delaying the reinforcer made it difficult for the rats to figure out exactly what behaviour they needed to perform in order to obtain it. In the same way, parents who wish to reinforce their children for playing quietly with a piece of candy should provide the candy while the child is still playing quietly; waiting until later when the child may be engaging in other behaviours—
How does the concept of delayed reinforcement relate to difficulties with quitting smoking?
The greater potency of immediate versus delayed reinforcers may help us to appreciate why it can be difficult to engage in behaviours that have long-
CULTURE & COMMUNITY: Are There Cultural Differences in Reinforcers?
Reinforcers play a critical role in operant conditioning, and operant approaches that use positive reinforcement have been applied extensively in everyday settings such as behaviour therapy (see Treatment of Psychological Disorders). Surveys designed to assess what kinds of reinforcers are rewarding to individuals have revealed that there can be wide differences among various groups (Dewhurst, & Cautela, 1980; Houlihan et al., 1991).
Recently, 750 high school students from America, Australia, Denmark, Honduras, Korea, Spain, and Tanzania were surveyed in order to evaluate possible cross-
These results should be taken with a grain of salt because the researchers did not control for variables other than culture that could influence their results, such as economic status. Nonetheless, they suggest that cultural differences should be considered in the design of programs or interventions that rely on the use of reinforcers to influence the behaviour of individuals who come from different cultures.
Similar considerations apply to punishment: As a general rule, the longer the delay between a behaviour and the administration of punishment, the less effective the punishment will be in suppressing the targeted behaviour (Kamin, 1959; Lerman & Vorndran, 2002). The reduced effectiveness of delayed punishment can be a serious problem in non-

7.2.3 The Basic Principles of Operant Conditioning
After establishing how reinforcement and punishment produced learned behaviour, Skinner and other scientists began to expand the parameters of operant conditioning. This took the form of investigating some phenomena that were well known in classical conditioning (such as discrimination, generalization, and extinction) as well as some practical applications, such as how best to administer reinforcement or how to produce complex learned behaviours in an organism. Let us look at some of these basic principles of operant conditioning.
7.2.3.1 Discrimination, Generalization, and the Importance of Context
What does it mean to say that learning takes place in contexts?
We all take off our clothes at least once a day, but usually not in public. We scream at rock concerts, but not in libraries. We say, “Please pass the gravy,” at the dinner table, but not in a classroom. Although these observations may seem like nothing more than common sense, Thorndike was the first to recognize the underlying message: Learning takes place in contexts, not in the free range of any plausible situation. As Skinner rephrased it later, most behaviour is under stimulus control, which develops when a particular response only occurs when an appropriate discriminative stimulus, a stimulus that indicates that a response will be reinforced, is present. Skinner (1972) discussed this process in terms of a “three-

Stimulus control, perhaps not surprisingly, shows both discrimination and generalization effects similar to those we saw with classical conditioning. To demonstrate this, researchers used either a painting by the French Impressionist Claude Monet or one of Pablo Picasso’s paintings from his Cubist period for the discriminative stimulus (Watanabe, Sakamoto, & Wakita, 1995). Participants in the experiment were only reinforced if they responded when the appropriate painting was presented. After training, the participants discriminated appropriately; those trained with the Monet painting responded when other paintings by Monet were presented and those trained with a Picasso painting reacted when other Cubist paintings by Picasso were shown. And as you might expect, Monet-
7.2.3.2 Extinction
In classical conditioning, a CR extinguishes when the animal learns that the CS no longer predicts the US. Similarly, an operant behaviour undergoes extinction when the behaviour no longer predicts reward; in other words, when the reinforcements stop. Pigeons cease pecking at a key if food is no longer presented following the behaviour. You would not put more money into a vending machine if it failed to give you its promised chocolate bar or pop. Warm smiles that are are not returned will quickly disappear. On the surface, extinction of operant behaviour looks like that of classical conditioning: The response rate drops off fairly rapidly and, if a rest period is provided, spontaneous recovery is typically seen.
How is the concept of extinction different in operant conditioning versus classical conditioning?
However, there is an important difference. In operant conditioning, the reinforcements only occur when the proper response has been made, and they do not always occur even then. Not every trip into the forest produces nuts for a squirrel, auto salespeople do not sell to everyone who takes a test drive, and researchers run many experiments that do not work out and never get published. Yet these behaviours do not weaken and gradually extinguish. In fact, they typically become stronger and more resilient. Curiously, then, extinction is a bit more complicated in operant conditioning than in classical conditioning because it depends, in part, on how often reinforcement is received. In fact, this principle is an important cornerstone of operant conditioning that we will examine next.
7.2.3.3 Schedules of Reinforcement
Skinner was intrigued by the apparent paradox surrounding extinction, and in his autobiography, he described how he began studying it (Skinner, 1979). He was labouriously rolling ground rat meal and water to make food pellets to reinforce the rats in his early experiments. It occurred to him that perhaps he could save time and effort by not giving his rats a pellet for every bar press but instead delivering food on some intermittent schedule. The results of this hunch were dramatic. Not only did the rats continue bar pressing, but they also shifted the rate and pattern of bar pressing depending on the timing and frequency of the presentation of the reinforcers. Unlike classical conditioning, where the sheer number of learning trials was important, in operant conditioning the pattern with which reinforcements appeared was crucial.
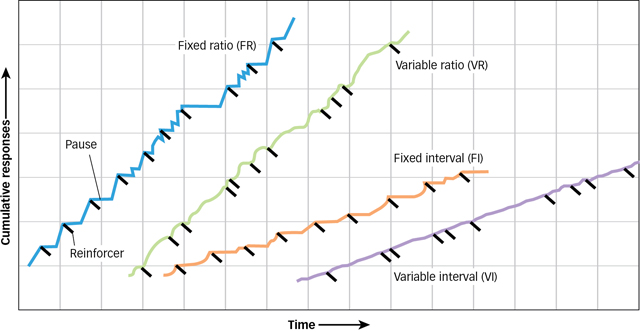
Skinner explored dozens of what came to be known as schedules of reinforcement (Ferster & Skinner, 1957) (see FIGURE 7.9 on the next page). The two most important are interval schedules, based on the time intervals between reinforcements, and ratio schedules, based on the ratio of responses to reinforcements.
7.2.3.3.1 Interval Schedules

Under a fixed-interval schedule (FI), reinforcers are presented at fixed-

How does a radio station use scheduled reinforcements to keep you listening?
Under a variable-interval schedule (VI), a behaviour is reinforced based on an average time that has expired since the last reinforcement. For example, on a 2-
Both fixed-
7.2.3.3.2 Ratio Schedules

Under a fixed-ratio schedule (FR), reinforcement is delivered after a specific number of responses have been made. One schedule might present reinforcement after every fourth response, a different schedule might present reinforcement after every 20 responses; the special case of presenting reinforcement after each response is called continuous reinforcement, and it is what drove Skinner to investigate these schedules in the first place. Notice that, in each example, the ratio of reinforcements to responses, once set, remains fixed.
How do ratio schedules work to keep you spending your money?
There are many situations in which people, sometimes unknowingly, find themselves being reinforced on a fixed-

Under a variable-ratio schedule (VR) the delivery of reinforcement is based on a particular average number of responses. For example, if a laundry worker was following a 10-
Not surprisingly, variable-

For example, if you have just put a dollar into a pop machine that, unbeknownst to you, is broken, no pop comes out. Because you are used to getting your pops on a continuous reinforcement schedule—
This relationship between intermittent reinforcement schedules and the robustness of the behaviour they produce is called the intermittent reinforcement effect, the fact that operant behaviours that are maintained under intermittent reinforcement schedules resist extinction better than those maintained under continuous reinforcement. In one extreme case, Skinner gradually extended a variable-
7.2.3.4 Shaping through Successive Approximations
Have you ever been to Marineland and wondered how the dolphins learn to jump up in the air, twist around, splash back down, do a somersault, and then jump through a hoop, all in one smooth motion? Well, they do not. Wait—
How can operant conditioning produce complex behaviours?
Skinner noted that the trial-

Skinner realized the potential power of shaping one day in 1943 when he was working on a wartime project sponsored by General Mills in a lab on the top floor of a flour mill where pigeons frequently visited (Peterson, 2004). In a lighthearted moment, Skinner and his colleagues decided to see whether they could teach the pigeons to “bowl” by swiping with their beaks at a ball that Skinner had placed in a box along with some pins. Nothing worked until Skinner decided to reinforce any response even remotely related to a swipe, such as merely looking at the ball. “The result amazed us,” Skinner recalled. “In a few minutes the ball was caroming off the walls of the box as if the pigeon had been a champion squash player” (Skinner, 1958, p. 974). Skinner applied this insight in his later laboratory research. For example, he noted that if you put a rat in a Skinner box and wait for it to press the bar, you could end up waiting a very long time: Bar pressing just is not very common in a rat’s natural repertoire of responses. However, it is relatively easy to shape bar pressing. Watch the rat closely: If it turns in the direction of the bar, deliver a food reward. This will reinforce turning toward the bar, making such a movement more likely. Now wait for the rat to take a step toward the bar before delivering food; this will reinforce moving toward the bar. After the rat walks closer to the bar, wait until it touches the bar before presenting the food. Notice that none of these behaviours is the final desired behaviour (reliably pressing the bar). Rather, each behaviour is a successive approximation to the final product, or a behaviour that gets incrementally closer to the overall desired behaviour. In the dolphin example—
7.2.3.5 Superstitious Behaviour
Everything we have discussed so far suggests that one of the keys to establishing reliable operant behaviour is the correlation between an organism’s response and the occurrence of reinforcement. In the case of continuous reinforcement, when every response is followed by the presentation of a reinforcer, there is a one-

How would a behaviourist explain superstitions?
Skinner (1948) designed an experiment that illustrates this distinction. He put several pigeons in Skinner boxes, set the food dispenser to deliver food every 15 seconds, and left the birds to their own devices. Later he returned and found the birds engaging in odd, idiosyncratic behaviours, such as pecking aimlessly in a corner or turning in circles. He referred to these behaviours as “superstitious” and offered a behaviourist analysis of their occurrence. The pigeons, he argued, were simply repeating behaviours that had been accidentally reinforced. A pigeon that just happened to have pecked randomly in the corner when the food showed up had connected the delivery of food to that behaviour. Because this pecking behaviour was reinforced by the delivery of food, the pigeon was likely to repeat it. Now pecking in the corner was more likely to occur, and it was more likely to be reinforced 15 seconds later when the food appeared again. For each pigeon, the behaviour reinforced would most likely be whatever the pigeon happened to be doing when the food was first delivered. Skinner’s pigeons acted as though there was a causal relationship between their behaviours and the appearance of food when it was merely an accidental correlation.

Although some researchers questioned Skinner’s characterization of these behaviours as superstitious (Staddon & Simmelhag, 1971), later studies have shown that reinforcing adults or children using schedules in which reinforcement is not contingent on their responses can produce seemingly superstitious behaviour. It seems that people, like pigeons, behave as though there is a correlation between their responses and reward when in fact the connection is merely accidental (Bloom et al., 2007; Mellon, 2009; Ono, 1987; Wagner & Morris, 1987). Such findings should not be surprising to sports fans. Baseball players who enjoy several home runs on a day when they happened not to have showered are likely to continue that tradition, laboring under the belief that the accidental correlation between poor personal hygiene and a good day at bat is somehow causal. This “stench causes home runs” hypothesis is just one of many examples of human superstitions (Gilbert et al., 2000; Radford & Radford, 1949).
7.2.4 A Deeper Understanding of Operant Conditioning
Like classical conditioning, operant conditioning also quickly proved to be a powerful approach to learning. But B. F. Skinner, like Watson before him, was satisfied to observe an organism perform a learned behaviour; he did not look for a deeper explanation of mental processes (Skinner, 1950). In this view, an organism behaved in a certain way as a response to stimuli in the environment, not because there was any wanting, wishing, or willing by the animal in question. However, some research on operant conditioning digs deeper into the underlying mechanisms that produce the familiar outcomes of reinforcement. Like we did earlier in the chapter with classical conditioning, let us examine three elements that expand our view of operant conditioning: the cognitive, neural, and evolutionary elements of operant conditioning.
7.2.4.1 The Cognitive Elements of Operant Conditioning

Edward Chace Tolman (1886–
Tolman’s means–
7.2.4.1.1 Latent Learning and Cognitive Maps
In latent learning, something is learned, but it is not manifested as a behavioural change until sometime in the future. Latent learning can easily be established in rats and occurs without any obvious reinforcement, a finding that posed a direct challenge to the then-
Tolman gave three groups of rats access to a complex maze every day for over 2 weeks. The control group never received any reinforcement for navigating the maze. They were simply allowed to run around until they reached the goal box at the end of the maze. In FIGURE 7.10 you can see that over the 2 weeks of the study, the control group (in green) got a little better at finding their way through the maze, but not by much. A second group of rats received regular reinforcements; when they reached the goal box, they found a small food reward there. Not surprisingly, these rats showed clear learning, as can be seen in blue in Figure 7.10. A third group was treated exactly like the control group for the first 10 days and then rewarded for the last 7 days. This group’s behaviour (in orange) was quite striking. For the first 10 days, they behaved like the rats in the control group. However, during the final 7 days, they behaved a lot like the rats in the second group that had been reinforced every day. Clearly, the rats in this third group had learned a lot about the maze and the location of the goal box during those first 10 days even though they had not received any reinforcements for their behaviour. In other words, they showed evidence of latent learning.
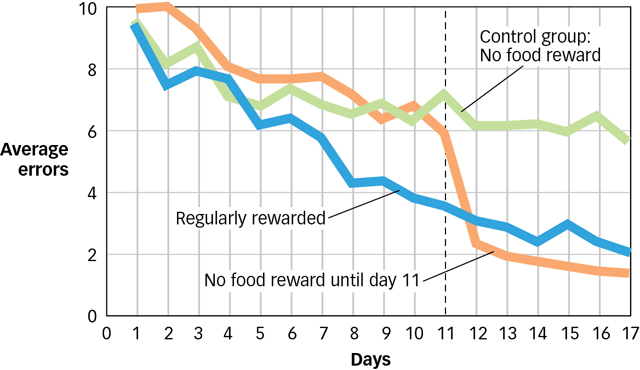
What are cognitive maps and why are they a challenge to behaviourism?
These results suggested to Tolman that beyond simply learning “start here, end here,” his rats had developed a sophisticated mental picture of the maze. Tolman called this a cognitive map, a mental representation of the physical features of the environment. Tolman thought that the rats had developed a mental picture of the maze, along the lines of “make two lefts, then a right, then a quick left at the corner,” and he devised several experiments to test that idea (Tolman & Honzik, 1930b; Tolman, Ritchie, & Kalish, 1946).
7.2.4.1.2 Further Support for Cognitive Explanations
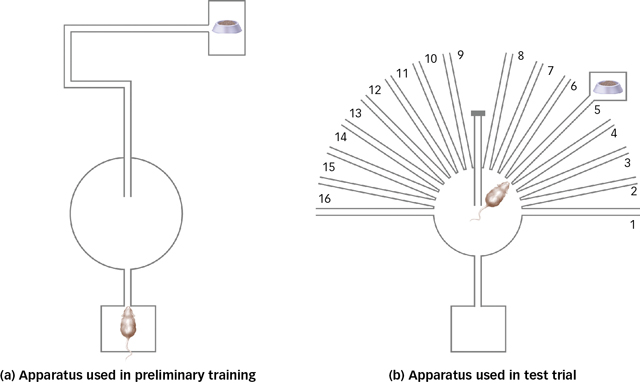
One simple experiment provided support for Tolman’s theories and wreaked havoc with the noncognitive explanations offered by staunch behaviourists. Tolman trained a group of rats in the maze shown in FIGURE 7.11a on the next page. As you can see, rats run down a straightaway, take a left, a right, a long right, and then end up in the goal box at the end of the maze. Because we are looking at it from above, we can see that the rat’s position at the end of the maze, relative to the starting point, is “diagonal to the upper right.” Of course, all the rat in the maze sees are the next set of walls and turns until it eventually reaches the goal box. Nonetheless, rats learned to navigate this maze without error or hesitation after about four nights. Clever rats. But they were more clever than you think.
After they had mastered the maze, Tolman changed things around a bit and put them in the maze shown in FIGURE 7.11b. The goal box was still in the same place relative to the start box. However, many alternative paths now spoked off the main platform, and the main straightaway that the rats had learned to use was blocked. Most behaviourists would predict that the rats in this situation—
7.2.4.1.3 Learning to Trust: For Better or Worse
Cognitive factors also played a key role in an experiment examining learning and brain activity (using fMRI) in people who played a “trust” game with a fictional partner (Delgado, Frank, & Phelps, 2005). On each trial, a participant could either keep a $1 reward or transfer the reward to a partner, who would receive $3. The partner could then either keep the $3 or share half of it with the participant. When playing with a partner who was willing to share the reward, the participant would be better off transferring the money, but when playing with a partner who did not share, the participant would be better off keeping the reward in the first place. Participants in such experiments typically find out who is trustworthy on the basis of trial-

In the study by Delgado and his colleagues, participants were given detailed descriptions of their partners that either portrayed the partners as trustworthy, neutral, or suspect. Even though during the game itself the sharing behaviour of the three types of partners did not differ—
Why might cognitive factors have been a factor in people’s trust of Bernie Madoff?
These kinds of effects might help us to understand otherwise perplexing real-
7.2.4.2 The Neural Elements of Operant Conditioning
Soon after psychologists came to appreciate the range and variety of things that could function as reinforcers, they began looking for underlying brain mechanisms that might account for these effects. The first hint of how specific brain structures might contribute to the process of reinforcement came from the discovery of what came to be called pleasure centres. McGill researchers James Olds and Peter Milner inserted tiny electrodes into different parts of a rat’s brain and allowed the animal to control electric stimulation of its own brain by pressing a bar. They discovered that some brain areas, particularly those in the limbic system (see the Neuroscience and Behaviour chapter), produced what appeared to be intensely positive experiences: The rats would press the bar repeatedly to stimulate these structures. The researchers observed that these rats would ignore food, water, and other life-
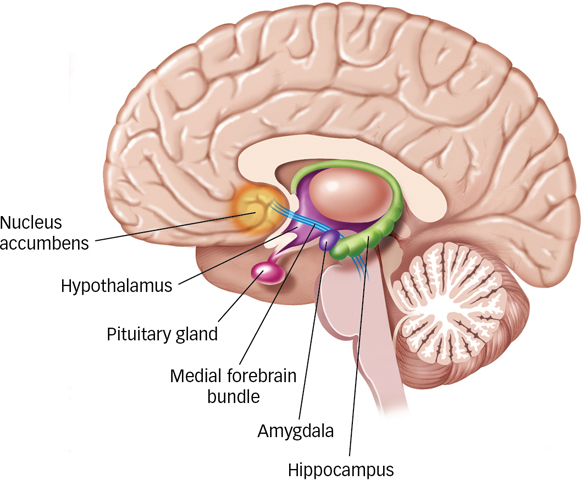
In the years since these early studies, researchers have identified a number of structures and pathways in the brain that deliver rewards through stimulation (Wise, 1989, 2005). The neurons in the medial forebrain bundle, a pathway that meanders its way from the midbrain through the hypothalamus into the nucleus accumbens, are the most susceptible to stimulation that produces pleasure. This is not surprising because psychologists have identified this bundle of cells as crucial to behaviours that clearly involve pleasure, such as eating, drinking, and engaging in sexual activity. Second, the neurons all along this pathway and especially those in the nucleus accumbens itself are all dopaminergic (i.e., they secrete the neurotransmitter dopamine). Remember from the Neuroscience and Behaviour chapter that higher levels of dopamine in the brain are usually associated with positive emotions. During recent years, several competing hypotheses about the precise role of dopamine have emerged, including the idea that dopamine is more closely linked with the expectation of reward than with reward itself (Fiorillo, Newsome, & Schultz, 2008; Schultz, 2006, 2007), or that dopamine is more closely associated with wanting or even craving something rather than simply liking it (Berridge, 2007).
How do specific brain structures contribute to the process of reinforcement?
Whichever view turns out to be correct, researchers have found good support for a reward centre in which dopamine plays a key role. First, as you have just seen, rats will work to stimulate this pathway at the expense of other basic needs (Olds & Fobes, 1981). However, if drugs that block the action of dopamine are administered to the rats, they cease pressing the lever for stimulation (Stellar, Kelley, & Corbett, 1983). Second, drugs such as cocaine, amphetamine, and opiates activate these pathways and centres (Moghaddam & Bunney, 1989), but dopamine-
HOT SCIENCE: Dopamine and Reward Learning in Parkinson’s Disease
Many of us have relatives or friends who have been affected by Parkinson’s disease (recall Michael J. Fox), which causes difficulty moving and involves the loss of neurons that use dopamine. As you learned in the Neuroscience and Behaviour chapter, the drug L-
Researchers have focused on the role of dopamine in reward-
In pioneering studies linking reward prediction error to dopamine, Wolfram Schultz and his colleagues recorded activity in dopamine neurons located in the reward centres of a monkey’s brain. They found that those neurons showed increased activity when the monkey received unexpected juice rewards and decreased activity when the monkey did not receive expected juice rewards. This suggests that dopamine neurons play an important role in generating the reward prediction error (Schultz, 2006, 2007; Schultz, Dayan, & Montague, 1997). Schultz’s observations have been backed up by studies using neuroimaging techniques to show that human brain regions involved in reward-

So, how do these findings relate to people with Parkinson’s disease? Several studies report that reward-
These results may relate to another intriguing feature of Parkinson’s disease: Some individuals develop serious problems with compulsive gambling, shopping, and related impulsive behaviours. Such problems seem to be largely the consequence of Parkinson’s drugs that stimulate dopamine receptors (Ahlskog, 2011; Weintraub, Papay, & Siderowf, 2013). Voon and her colleagues (2011) studied individuals who developed gambling and shopping problems only after contracting Parkinson’s disease and receiving treatment with drugs that stimulate dopamine receptors. Those individuals were scanned with fMRI while they performed a reward-
More studies will be needed to unravel the complex relations among dopamine, reward prediction error, learning, and Parkinson’s disease, but the studies to date suggest that such research should have important practical as well as scientific implications.
7.2.4.3 The Evolutionary Elements of Operant Conditioning
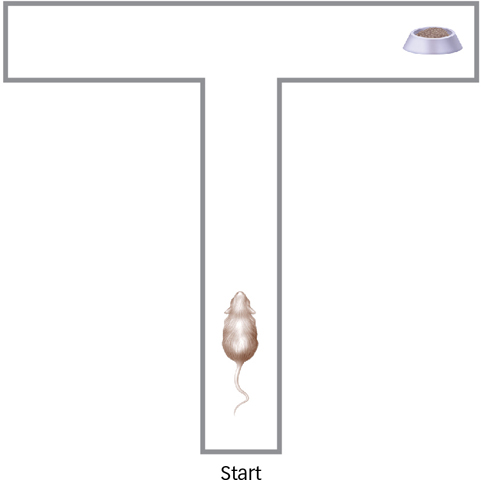
As you will recall, classical conditioning has an adaptive value that has been fine-
What was puzzling from a behaviourist perspective makes sense when viewed from an evolutionary perspective. Rats are foragers and, like all foraging species, they have evolved a highly adaptive strategy for survival. They move around in their environment looking for food. If they find it somewhere, they eat it (or store it) and then go look somewhere else for more. If they do not find food, they forage in another part of the environment. So, if the rat just found food in the right arm of a T maze, the obvious place to look next time is the left arm. The rat knows that there is not more food in the right arm because it just ate the food it found there! Indeed, foraging animals such as rats have well-
What explains a rat’s behaviour in a T maze?
Two of Skinner’s former students, Keller Breland and Marian Breland, were among the first researchers to discover that it was not just rats in T mazes that presented a problem for behaviourists (Breland & Breland, 1961). The Brelands pointed out that psychologists and the organisms they study often seemed to “disagree” on what the organisms should be doing. Their argument was simple: When this kind of dispute develops, the animals are always right, and the psychologists had better rethink their theories.
The Brelands, who made a career out of training animals for commercials and movies, often used pigs because pigs are surprisingly good at learning all sorts of tricks. However, they discovered that it was extremely difficult to teach a pig the simple task of dropping coins in a box. Instead of depositing the coins, the pigs persisted in rooting with them as if they were digging them up in soil, tossing them in the air with their snouts and pushing them around. The Brelands tried to train raccoons at the same task, with different but equally dismal results. The raccoons spent their time rubbing the coins between their paws instead of dropping them in the box.

Having learned the association between the coins and food, the animals began to treat the coins as stand-
The Brelands’ work shows that all species, including humans, are biologically predisposed to learn some things more readily than others and to respond to stimuli in ways that are consistent with their evolutionary history (Gallistel, 2000). Such adaptive behaviours, however, evolved over extraordinarily long periods and in particular environmental contexts. If those circumstances change, some of the behavioural mechanisms that support learning can lead an organism astray. Raccoons that associated coins with food failed to follow the simple route to obtaining food by dropping the coins in the box; “nature” took over and they wasted time rubbing the coins together. The point is that, although much of every organism’s behaviour results from predispositions sharpened by evolutionary mechanisms, these mechanisms sometimes can have ironic consequences.
Operant conditioning, as developed by B. F. Skinner, is a process by which behaviours are reinforced and therefore become more likely to occur, where complex behaviours are shaped through reinforcement, and where the contingencies between actions and outcomes are critical in determining how an organism’s behaviours will be displayed.
Like Watson, Skinner tried to explain behaviour without considering cognitive, neural, or evolutionary mechanisms. However, as with classical conditioning, this approach turned out to be incomplete.
Operant conditioning has clear cognitive components: Organisms behave as though they have expectations about the outcomes of their actions and adjust their actions accordingly. Cognitive influences can sometimes override the trial-
by- trial feedback that usually influences learning. Page 295Studies with both animals and people highlight the operation of a neural reward centre that impacts learning.
The associative mechanisms that underlie operant conditioning have their roots in evolutionary biology. Some things are relatively easily learned and others are difficult; the history of the species is usually the best clue as to which will be which.