6.5Modern Techniques Make the Experimental Exploration of Evolution Possible
Modern Techniques Make the Experimental Exploration of Evolution Possible
Two techniques of biochemistry have made it possible to examine the course of evolution more directly and not simply by inference. The polymerase chain reaction (Section 5.1) allows the direct examination of ancient DNA sequences, releasing us, at least in some cases, from the constraints of being able to examine existing genomes from living organisms only. Molecular evolution may be investigated through the use of combinatorial chemistry, the process of producing large populations of molecules en masse and selecting for a biochemical property. This exciting process provides a glimpse into the types of molecules that may have existed very early in evolution.
Ancient DNA can sometimes be amplified and sequenced
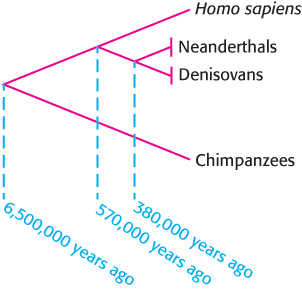
The tremendous chemical stability of DNA makes the molecule well suited to its role as the storage site of genetic information. So stable is the molecule that samples of DNA have survived for many thousands of years under appropriate conditions. With the development of PCR and advanced DNA-
Remarkably, the complete genome sequences of a Neanderthal and a closely related hominin known as a Denisovan have been obtained using DNA isolated from nearly 50,000-
A few earlier studies claimed to determine the sequences of far more ancient DNA such as that found in insects trapped in amber, but these studies appear to have been flawed. The source of these sequences turned out to be contaminating modern DNA. Successful sequencing of ancient DNA requires sufficient DNA for reliable amplification and the rigorous exclusion of all sources of contamination.
Molecular evolution can be examined experimentally
Evolution requires three processes: (1) the generation of a diverse population, (2) the selection of members based on some criterion of fitness, and (3) reproduction to enrich the population in these more-
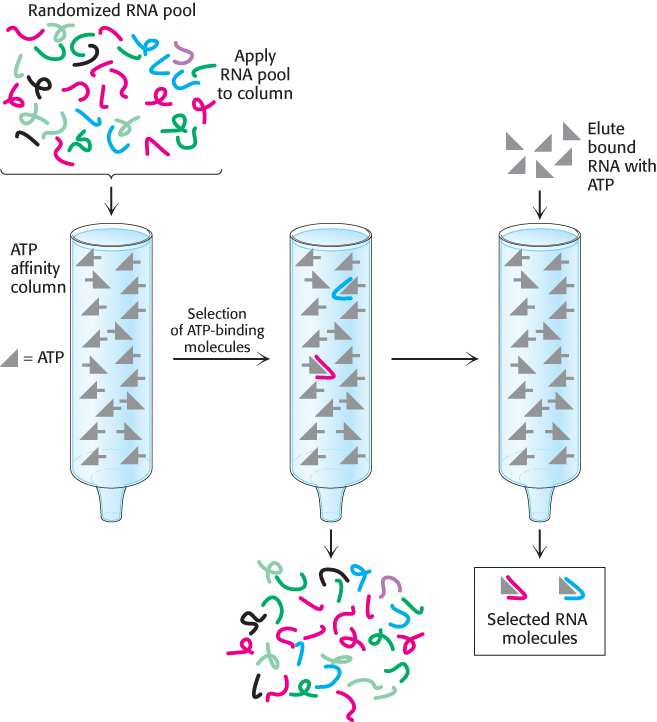
A diverse population of nucleic acid molecules can be synthesized in the laboratory by the process of combinatorial chemistry, which rapidly produces large populations of a particular type of molecule such as a nucleic acid. A population of molecules of a given size can be generated randomly so that many or all possible sequences are present in the mixture. When an initial population has been generated, it is subjected to a selection process that isolates specific molecules with desired binding or reactivity properties. Finally, molecules that have survived the selection process are replicated through the use of PCR; primers are directed toward specific sequences included at the ends of each member of the population. Errors that occur naturally in the course of the replication process introduce additional variation into the population in each “generation.” Let us consider an application of this approach. Early in evolution, before the emergence of proteins, RNA molecules may have played all major roles in biological catalysis. To understand the properties of potential RNA catalysts, researchers have used the methods heretofore described to create an RNA molecule capable of binding adenosine triphosphate and related nucleotides. An initial population of RNA molecules 169 nucleotides long was created; 120 of the positions differed randomly, with equimolar mixtures of adenine, cytosine, guanine, and uracil. The initial synthetic pool that was used contained approximately 1014 RNA molecules. Note that this number is a very small fraction of the total possible pool of random 120-
186
The collection of molecules that were bound well by the ATP affinity column was replicated by reverse transcription into DNA, amplification by PCR, and transcription back into RNA. The somewhat error-
187
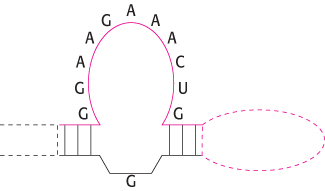
The folded structure of the ATP-
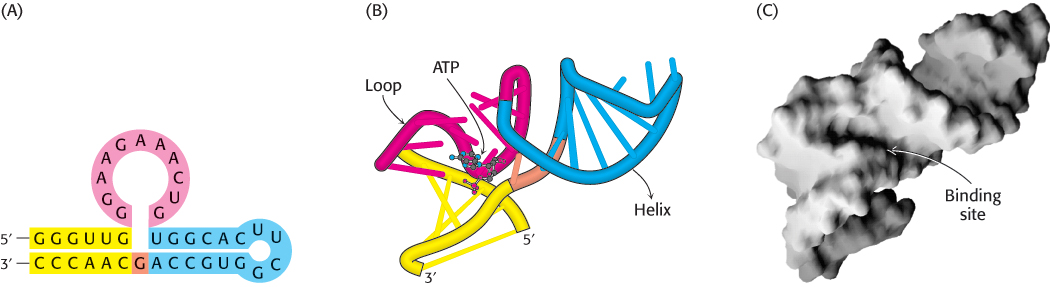
 Synthetic oligonucleotides that can specifically bind ligands, such as the ATP-
Synthetic oligonucleotides that can specifically bind ligands, such as the ATP-