Errors can arise in DNA replication
Errors introduced in the replication process are the simplest source of damage in the double helix. With the addition of each base, there is the possibility that an incorrect base might be incorporated, forming a non-Watson–Crick base pair. These non-Watson–Crick base pairs can locally distort the DNA double helix. Furthermore, such mismatches can be mutagenic; that is, they can result in permanent changes in the DNA sequence. When a double helix containing a non-Watson–Crick base pair is replicated, the two daughter double helices will have different sequences because the mismatched base is very likely to pair with its Watson–Crick partner. Errors other than mismatches include insertions, deletions, and breaks in one or both strands. Furthermore, replicative polymerases can stall or even fall off a damaged template entirely. As a consequence, replication of the genome may halt before it is complete.
A variety of mechanisms have evolved to deal with such interruptions, including specialized DNA polymerases that can replicate DNA across many lesions. A drawback is that such polymerases are substantially more error prone than are normal replicative polymerases. Nonetheless, these translesion or error-prone polymerases allow the completion of a draft sequence of the genome that can be at least partly repaired by DNA-repair processes. DNA recombination (Section 28.5) provides an additional mechanism for salvaging interruptions in DNA replication.
Bases can be damaged by oxidizing agents, alkylating agents, and light
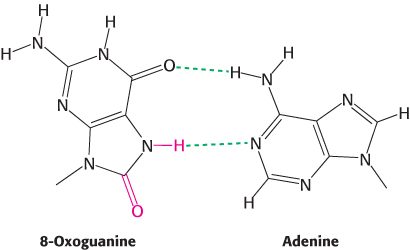
FIGURE 28.32Oxoguanine–adenine base pair. When guanine is oxidized to 8-oxoguanine, the damaged base can form a base pair with adenine through an edge of the base that does not normally participate in base-pair formation.
A variety of chemical agents can alter specific bases within DNA after replication is complete. Such mutagens include reactive oxygen species such as hydroxyl radical. For example, hydroxyl radical reacts with guanine to form 8-oxoguanine. 8-Oxoguanine is mutagenic because it often pairs with adenine rather than cytosine in DNA replication. Its choice of pairing partner differs from that of guanine because it uses a different edge of the base to form base pairs (Figure 28.32). Deamination is another potentially deleterious process. For example, adenine can be deaminated to form hypoxanthine (Figure 28.33). This process is mutagenic because hypoxanthine pairs with cytosine rather than thymine. Guanine and cytosine also can be deaminated to yield bases that pair differently from the parent base.
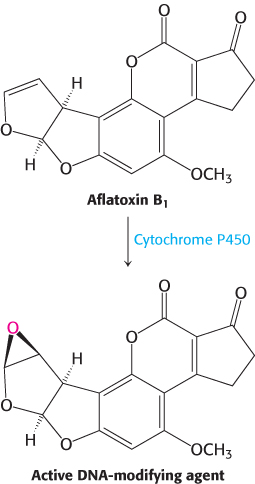
FIGURE 28.34Aflatoxin activation. The compound, produced by molds that grow on peanuts, is activated by cytochrome P450 to form a highly reactive species that modifies bases such as guanine in DNA, leading to mutations.
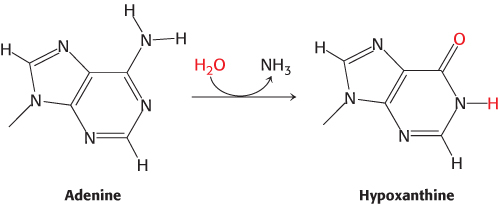
FIGURE 28.33Adenine deamination. The base adenine can be deaminated to form hypoxanthine. Hypoxanthine forms base pairs with cytosine in a manner similar to that of guanine, and so the deamination reaction can result in mutation.
In addition to oxidation and deamination, nucleotide bases are subject to alkylation. Electrophilic centers can be attacked by nucleophiles such as N-7 of guanine and adenine to form alkylated adducts. Some compounds are converted into highly active electrophiles through the action of enzymes that normally play a role in detoxification. A striking example is aflatoxin B1, a compound produced by molds that grow on peanuts and other foods. A cytochrome P450 enzyme (Section 26.4) converts this compound into a highly reactive epoxide (Figure 28.34). This agent reacts with the N-7 atom of guanosine to form a mutagenic adduct that frequently leads to a G–C-to-T–A transversion.
The ultraviolet component of sunlight is a ubiquitous DNA-damaging agent. Its major effect is to covalently link adjacent pyrimidine residues along a DNA strand (Figure 28.35). Such a pyrimidine dimer cannot fit into a double helix, and so replication and gene expression are blocked until the lesion is removed.
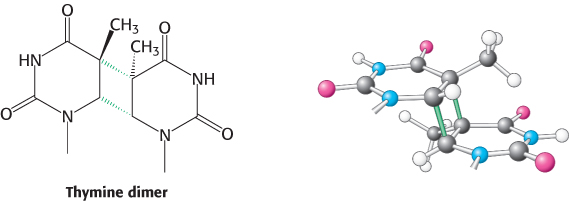
FIGURE 28.35Cross-linked dimer of two thymine bases. Ultraviolet light induces cross-links between adjacent pyrimidines along one strand of DNA.
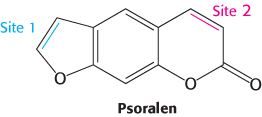
FIGURE 28.36A cross-linking agent. The compound psoralen and its derivatives can form interstrand cross-links through two reactive sites that can form adducts with nucleotide bases.
A thymine dimer is an example of an intrastrand cross-link because both participating bases are in the same strand of the double helix. Cross-links between bases on opposite strands also can be introduced by various agents. Psoralens are compounds, produced by a number of plants including the common fig, that form such interstrand cross-links (Figure 28.36). Interstrand cross-links disrupt replication because they prevent strand separation.
High-energy electromagnetic radiation such as x-rays can damage DNA by producing high concentrations of reactive species in solution. X-ray exposure can induce several types of DNA damage including single- and double-stranded breaks in DNA. This ability to induce such DNA damage led Hermann Muller to discover the mutagenic effects of x-rays in Drosophila in 1927. This discovery contributed to the development of Drosophila as one of the premier organisms for genetic studies.
DNA damage can be detected and repaired by a variety of systems
To protect the genetic message, a wide range of DNA-repair systems are present in most organisms. Many systems repair DNA by using sequence information from the uncompromised strand. Such single-strand replication systems follow a similar mechanistic outline:
Recognize the offending base(s).
Remove the offending base(s).
Repair the resulting gap with a DNA polymerase and DNA ligase.
We will briefly consider examples of several repair pathways. Although many of these examples are taken from E. coli, corresponding repair systems are present in most other organisms, including humans.
The replicative DNA polymerases themselves are able to correct many DNA mismatches produced in the course of replication. For example, the ε subunit of E. coli DNA polymerase III functions as a 3′-to-5′ exonuclease. This domain removes mismatched nucleotides from the 3′ end of DNA by hydrolysis. How does the enzyme sense whether a newly added base is correct? As a new strand of DNA is synthesized, it is proofread. If an incorrect base is inserted, then DNA synthesis slows down owing to the difficulty of threading a non-Watson–Crick base pair into the polymerase. In addition, the mismatched base is weakly bound and therefore able to fluctuate in position. The delay from the slowdown allows time for these fluctuations to take the newly synthesized strand out of the polymerase active site and into the exonuclease active site (Figure 28.37). There, the DNA is degraded, one nucleotide at a time, until it moves back into the polymerase active site and synthesis continues.
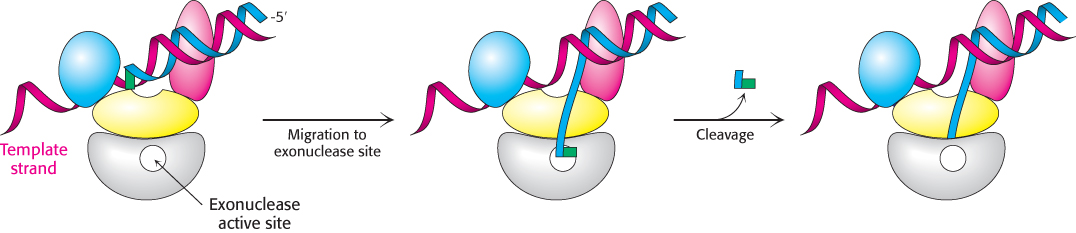
FIGURE 28.37Proofreading. The growing polynucleotide chain occasionally leaves the polymerase site and migrates to the active site of the exonuclease. There, one or more nucleotides are excised from the newly synthesized chain, removing potentially incorrect bases.
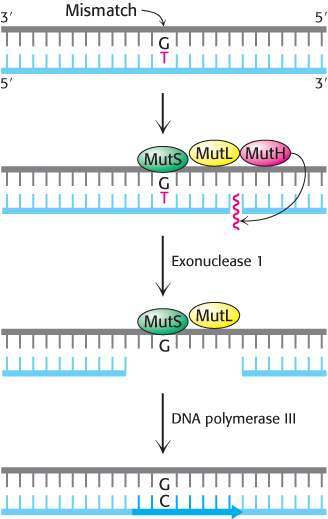
FIGURE 28.38Mismatch repair. DNA mismatch repair in E. coli is initiated by the interplay of MutS, MutL, and MutH proteins. A G—T mismatch is recognized by MutS. MutH cleaves the backbone in the vicinity of the mismatch. A segment of the DNA strand containing the erroneous T is removed by exonuclease I and synthesized anew by DNA polymerase III.
[Information from R. F. Service, Science 263:1559–1560, 1994.]
A second mechanism is present in essentially all cells to correct errors made in replication that are not corrected by proofreading (Figure 28.38). Mismatch repair systems consist of at least two proteins, one for detecting the mismatch and the other for recruiting an endonuclease that cleaves the newly synthesized DNA strand close to the lesion to facilitate repair. In E. coli, these proteins are called MutS and MutL and the endonuclease is called MutH.
Another mechanism of DNA repair is direct repair, one example of which is the photochemical cleavage of pyrimidine dimers. Nearly all cells contain a photoreactivating enzyme called DNA photolyase. The E. coli enzyme, a 35-kd protein that contains bound N5,N10-methenyltetrahydrofolate and flavin adenine dinucleotide (FAD) cofactors, binds to the distorted region of DNA. The enzyme uses light energy—specifically, the absorption of a photon by the N5,N10-methenyltetrahydrofolate coenzyme—to form an excited state that cleaves the dimer into its component bases.
The excision of modified bases such as 3-methyladenine by the E. coli enzyme AlkA is an example of base-excision repair. The binding of this enzyme to damaged DNA flips the affected base out of the DNA double helix and into the active site of the enzyme (Figure 28.39). The enzyme then acts as a glycosylase, cleaving the glycosidic bond to release the damaged base. At this stage, the DNA backbone is intact, but a base is missing. This hole is called an AP site because it is apurinic (devoid of A or G) or apyrimidinic (devoid of C or T). An AP endonuclease recognizes this defect and nicks the backbone adjacent to the missing base. Deoxyribose phosphodiesterase excises the residual deoxyribose phosphate unit, and DNA polymerase I inserts an undamaged nucleotide, as dictated by the base on the undamaged complementary strand. Finally, the repaired strand is sealed by DNA ligase.
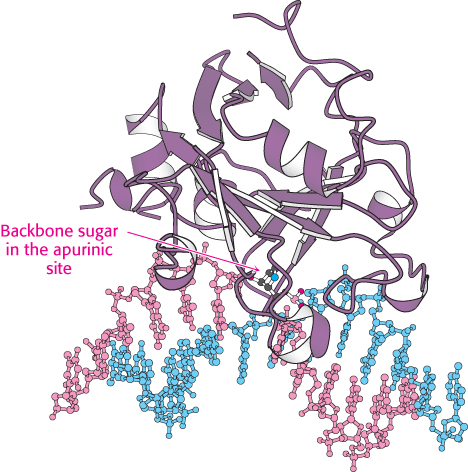
 FIGURE 28.39 Structure of DNA-repair enzyme. A complex between the DNA-repair enzyme AlkA and an analog of a DNA molecule missing a purine base (an apurinic site) is shown. Notice that the backbone sugar in the apurinic site is flipped out of the double helix into the active site of the enzyme.
FIGURE 28.39 Structure of DNA-repair enzyme. A complex between the DNA-repair enzyme AlkA and an analog of a DNA molecule missing a purine base (an apurinic site) is shown. Notice that the backbone sugar in the apurinic site is flipped out of the double helix into the active site of the enzyme.
[Drawn from 1BNK.pdb.]
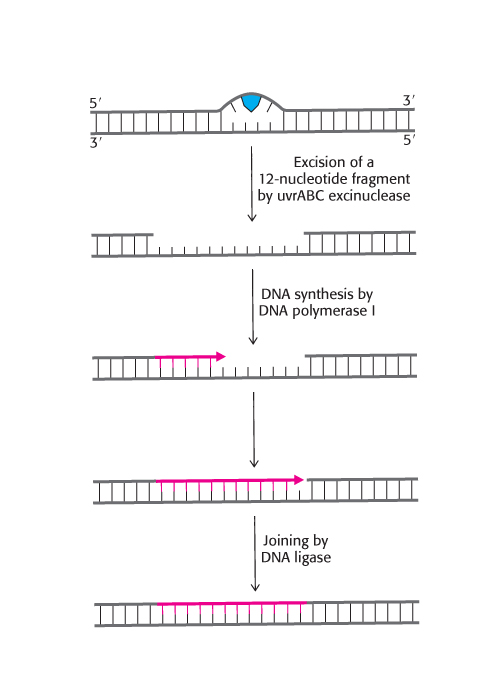
FIGURE 28.40Nucleotide-excision repair. Repair of a region of DNA containing a thymine dimer by the sequential action of a specific excinuclease, a DNA polymerase, and a DNA ligase. The thymine dimer is shown in blue and the new region of DNA is in red.
[Information from P. C. Hanawalt, Endevour 31:83, 1982.]
One of the best-understood examples of nucleotide-excision repair is utilized for the excision of a pyrimidine dimer. Three enzymatic activities are essential for this repair process in E. coli (Figure 28.40). First, an enzyme complex consisting of the proteins encoded by the uvrABC genes detects the distortion produced by the DNA damage. The UvrABC enzyme then cuts the damaged DNA strand at two sites, 8 nucleotides away from the damaged site on the 5′ side and 4 nucleotides away on the 3′ side. The 12-residue oligonucleotide excised by this highly specific excinuclease (from the Latin exci, “to cut out”) then diffuses away. DNA polymerase I enters the gap to carry out repair synthesis. The 3′ end of the nicked strand is the primer, and the intact complementary strand is the template. Finally, the 3′ end of the newly synthesized stretch of DNA and the original part of the DNA chain are joined by DNA ligase.
DNA ligase is able to seal simple breaks in one strand of the DNA backbone. However, alternative mechanisms are required to repair breaks on both strands that are close enough together to separate the DNA into two double helices. Several distinct mechanisms are able to repair such damage. One mechanism, nonhomologous end joining (NHEJ), does not depend on other DNA molecules in the cell. In NHEJ, the free double-stranded ends are bound by a heterodimer of two proteins, Ku70 and Ku80. These proteins stabilize the ends and mark them for subsequent manipulations. Through mechanisms that are not yet well understood, the Ku70/80 heterodimers act as handles used by other proteins to draw the two double-stranded ends close together so that enzymes can seal the break.
Alternative mechanisms of double-stranded-break repair can operate if an intact stretch of double-stranded DNA with an identical or very similar sequence is present in the cell. These repair processes use homologous recombination, presented in Section 28.5.
As noted in Section 5.4, researchers can now take advantage of double-stranded-break repair mechanisms for executing targeted changes in eukaryotic genomes. Specific engineered nucleases are used to introduce double-strand breaks in particular locations within the genome. The DNA repair machinery in the targeted cells will then repair the break, through either NHEJ to disrupt the gene or homologous recombination-based repair with added double-stranded DNA fragments to introduce more elaborate modifications. For example, mutations associated with human diseases can be specifically introduced into the genomes of model organisms such as mice or zebrafish to examine the consequences.
The presence of thymine instead of uracil in DNA permits the repair of deaminated cytosine
 The presence in DNA of thymine rather than uracil, as in RNA, was an enigma for many years. Both bases pair with adenine. The only difference between them is a methyl group in thymine in place of the C-5 hydrogen atom in uracil. Why is a methylated base employed in DNA and not in RNA? The existence of an active repair system to correct the deamination of cytosine provides a convincing solution to this puzzle.
The presence in DNA of thymine rather than uracil, as in RNA, was an enigma for many years. Both bases pair with adenine. The only difference between them is a methyl group in thymine in place of the C-5 hydrogen atom in uracil. Why is a methylated base employed in DNA and not in RNA? The existence of an active repair system to correct the deamination of cytosine provides a convincing solution to this puzzle.
Cytosine in DNA spontaneously deaminates at a perceptible rate to form uracil. The deamination of cytosine is potentially mutagenic because uracil pairs with adenine, and so one of the daughter strands will contain a U–A base pair rather than the original C–G base pair. This mutation is prevented by a repair system that recognizes uracil to be foreign to DNA (Figure 28.41). The repair enzyme, uracil DNA glycosylase, is homologous to AlkA. The enzyme hydrolyzes the glycosidic bond between the uracil and deoxyribose moieties but does not attack thymine-containing nucleotides. The AP site generated is repaired to reinsert cytosine. Thus, the methyl group on thymine is a tag that distinguishes thymine from deaminated cytosine. If thymine were not used in DNA, uracil correctly in place would be indistinguishable from uracil formed by deamination. The defect would persist unnoticed, and so a C–G base pair would necessarily be mutated to U–A in one of the daughter DNA molecules. This mutation is prevented by a repair system that searches for uracil and leaves thymine alone. Thymine is used instead of uracil in DNA to enhance the fidelity of the genetic message.
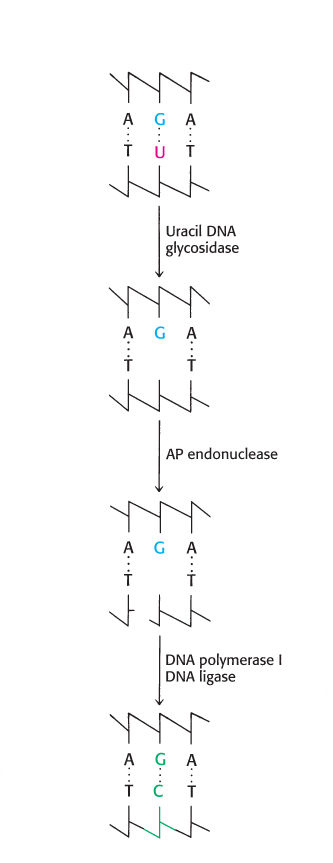
FIGURE 28.41Uracil repair. Uridine bases in DNA, formed by the deamination of cytidine, are excised and replaced by cytidine.
Some genetic diseases are caused by the expansion of repeats of three nucleotides
 Some genetic diseases are caused by the presence of DNA sequences that are inherently prone to errors in the course of repair and replication. A particularly important class of such diseases is characterized by the presence of long tandem arrays of repeats of three nucleotides. An example is Huntington disease, an autosomal dominant neurological disorder with a variable age of onset. The mutated gene in this disease expresses a protein in the brain called huntingtin, which contains a stretch of consecutive glutamine residues. These glutamine residues are encoded by a tandem array of CAG sequences within the gene. In unaffected persons, this array is between 6 and 31 repeats, whereas, in those with the disease, the array is between 36 and 82 repeats or longer. Moreover, the array tends to become longer from one generation to the next. The consequence is a phenomenon called anticipation: the children of an affected parent tend to show symptoms of the disease at an earlier age than did the parent.
Some genetic diseases are caused by the presence of DNA sequences that are inherently prone to errors in the course of repair and replication. A particularly important class of such diseases is characterized by the presence of long tandem arrays of repeats of three nucleotides. An example is Huntington disease, an autosomal dominant neurological disorder with a variable age of onset. The mutated gene in this disease expresses a protein in the brain called huntingtin, which contains a stretch of consecutive glutamine residues. These glutamine residues are encoded by a tandem array of CAG sequences within the gene. In unaffected persons, this array is between 6 and 31 repeats, whereas, in those with the disease, the array is between 36 and 82 repeats or longer. Moreover, the array tends to become longer from one generation to the next. The consequence is a phenomenon called anticipation: the children of an affected parent tend to show symptoms of the disease at an earlier age than did the parent.
The tendency of these trinucleotide repeats to expand is explained by the formation of alternative structures in the course of DNA repair. On cleavage of the DNA backbone, part of the array can loop out without disrupting base-pairing outside this region. Then, in replication, DNA polymerase extends this strand through the remainder of the array, leading to an increase in the number of copies of the trinucleotide sequence.
A number of other neurological diseases are characterized by expanding arrays of trinucleotide repeats. How do these long stretches of repeated amino acids cause disease? For huntingtin, it appears that the polyglutamine stretches become increasingly prone to aggregate as their length increases; the additional consequences of such aggregation are still under investigation.
Many cancers are caused by the defective repair of DNA
As described in Chapter 14, cancers are caused by mutations in genes associated with growth control. Defects in DNA-repair systems increase the overall frequency of mutations and, hence, the likelihood of cancer-causing mutations. Indeed, the synergy between studies of mutations that predispose people to cancer and studies of DNA repair in model organisms has been tremendous in revealing the biochemistry of DNA-repair pathways. Genes for DNA-repair proteins are often tumor-suppressor genes; that is, they suppress tumor development when at least one copy of the gene is free of a deleterious mutation. When both copies of a gene are mutated, however, tumors develop at rates greater than those for the population at large. People who inherit defects in a single tumor-suppressor allele do not necessarily develop cancer but are susceptible to developing the disease because only the one remaining normal copy of the gene must develop a new defect to further the development of cancer. Table 28.2 lists selected genes that are associated with diseases including cancer and that encode proteins involved with DNA repair processes.
TABLE 28.2
|
|
|
|
Xeroderma pigmentosum (skin) |
|
Nucleotide excision repair |
Lynch syndrome (colon cancer) |
|
|
Breast and ovarian cancer |
|
Double-strand break repair |
|
|
|
|
Consider, for example, xeroderma pigmentosum, a rare human skin disease. The skin of an affected person is extremely sensitive to sunlight or ultraviolet light. In infancy, severe changes in the skin become evident and worsen with time. The skin becomes dry, and there is a marked atrophy of the dermis. Keratoses appear, the eyelids become scarred, and the cornea ulcerates. Skin cancer usually develops at several sites. Many patients die before age 30 from metastases of these malignant skin tumors. Studies of xeroderma pigmentosum patients have revealed that mutations occur in genes for a number of different proteins. These proteins are components of the human nucleotide-excision-repair pathway, including homologs of the UvrABC subunits.
Defects in other repair systems can increase the frequency of other tumors. For example, hereditary nonpolyposis colorectal cancer (HNPCC, or Lynch syndrome) results from defective DNA mismatch repair. HNPCC is not rare—as many as 1 in 200 people will develop this form of cancer. Mutations in two genes, called hMSH2 and hMLH1, account for most cases of this hereditary predisposition to cancer. The striking finding is that these genes encode the human counterparts of MutS and MutL of E. coli. Mutations in hMSH2 and hMLH1 seem likely to allow mutations to accumulate throughout the genome. In time, genes important in controlling cell proliferation become altered, resulting in the onset of cancer.
Not all tumor-suppressor genes are specific to particular types of cancer. The gene for a protein called p53 is mutated in more than half of all tumors. The p53 protein helps control the fate of damaged cells. First, it plays a central role in sensing DNA damage, especially double-stranded breaks. Then, after sensing damage, the protein either promotes a DNA-repair pathway or activates the apoptosis pathway, leading to cell death. Most mutations in the p53 gene are sporadic; that is, they occur in somatic cells rather than being inherited. People who inherit a deleterious mutation in one copy of the p53 gene suffer from Li-Fraumeni syndrome and have a high probability of developing several types of cancer.
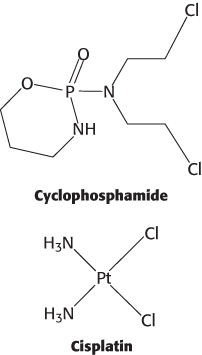
Cancer cells often have two characteristics that make them especially vulnerable to agents that damage DNA molecules. First, they divide frequently, and so their DNA replication pathways are more active than they are in most cells. Second, as already noted, cancer cells often have defects in DNA-repair pathways. Several agents widely used in cancer chemotherapy, including cyclophosphamide and cisplatin, act by damaging DNA. Cancer cells are less able to avoid the effect of the induced damage than are normal cells, providing a therapeutic window for specifically killing cancer cells.
Many potential carcinogens can be detected by their mutagenic action on bacteria
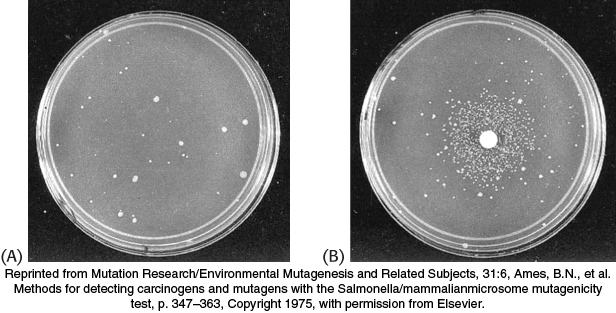
FIGURE 28.42Ames test. (A) A petri plate containing about 109 Salmonella bacteria that cannot synthesize histidine and (B) a petri plate containing a filter-paper disc with a mutagen, which produces a large number of revertants that can synthesize histidine. After 2 days, the revertants appear as rings of colonies around the disc. The small number of visible colonies in plate A are spontaneous revertants.
Many human cancers are caused by exposure to chemicals that cause mutations. It is important to identify such compounds and to ascertain their potency so that human exposure to them can be minimized. Bruce Ames devised a simple and sensitive test for detecting chemical mutagens. In the Ames test, a thin layer of agar containing about 109 bacteria of a specially constructed tester strain of Salmonella is placed on a petri plate. These bacteria are unable to grow in the absence of histidine, because a mutation is present in one of the genes for the biosynthesis of this amino acid. The addition of a chemical mutagen to the center of the plate results in many new mutations. A small proportion of them reverse the original mutation, and histidine can be synthesized. These revertants multiply in the absence of an external source of histidine and appear as discrete colonies after the plate has been incubated at 37°C for 2 days (Figure 28.42). For example, 0.5 μg of 2-aminoanthracene gives 11,000 revertant colonies, compared with only 30 spontaneous revertants in its absence. A series of concentrations of a chemical can be readily tested to generate a dose–response curve.
Some of the tester strains are responsive to base-pair substitutions, whereas others detect deletions or additions of base pairs (frameshifts). The sensitivity of these specially designed strains has been enhanced by the genetic deletion of their excision-repair systems. Potential mutagens enter the tester strains easily because the lipopolysaccharide barrier that normally coats the surface of Salmonella is incomplete in these strains. A key feature of this detection system is the inclusion of a mammalian liver homogenate. Recall that some potential carcinogens such as aflatoxin are converted into their active forms by enzyme systems in the liver or other mammalian tissues. Bacteria lack these enzymes, and so the test plate requires a few milligrams of a liver homogenate to activate this group of mutagens.
The Salmonella test is extensively used to help evaluate the mutagenic and carcinogenic risks of a large number of chemicals. This rapid and inexpensive bacterial assay for mutagenicity complements epidemiological surveys and animal tests that are necessarily slower, more laborious, and far more expensive. The Salmonella test for mutagenicity is an outgrowth of studies of gene–protein relations in bacteria. It is a striking example of how fundamental research in molecular biology can lead directly to important advances in public health.