17.1 DECIPHERING THE GENETIC CODE: tRNA AS ADAPTOR
DNA and RNA each consist of only four different nucleotides, whereas proteins can have up to 20 different amino acids. For only four nucleotides to specify the 20 common amino acids, multiple nucleotides must be combined to make up a code. Combinations of two nucleotides yield only 16 (42) different dinucleotide code words, insufficient to encode 20 amino acids. Combinations of three nucleotides yield 64 (43) code words, more than enough to specify 20 amino acids. Hence, the RNA “code word,” or codon, was hypothesized to be a combination of three nucleotides, or possibly more. Insightful experiments, described in this chapter, demonstrated that the code is indeed triplet.
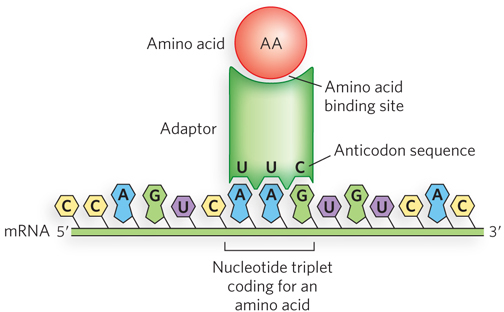
In 1955, to explain how an RNA sequence codes for a sequence of amino acids, Francis Crick hypothesized the existence of an “adaptor” molecule. He proposed that adaptors can recognize specific codons in the mRNA and that each adaptor carries a specific amino acid (Figure 17-1). Adaptors line up on the mRNA, thus aligning the sequence of amino acids. Not long after Crick’s adaptor hypothesis, Paul Zamecnik and Mahlon Hoagland discovered a small RNA that covalently attaches to amino acids in a reaction requiring ATP (see the How We Know section at the end of this chapter). These RNA–
591
KEY CONVENTION
In denoting tRNAs, the specificity is indicated by a superscript, and the aminoacylated-
All tRNAs Have a Similar Structure
The structure of the tRNA molecule reveals how it is capable of functioning as an adaptor. We briefly discuss tRNA structure here, and then explore this topic in greater detail in Chapter 18.
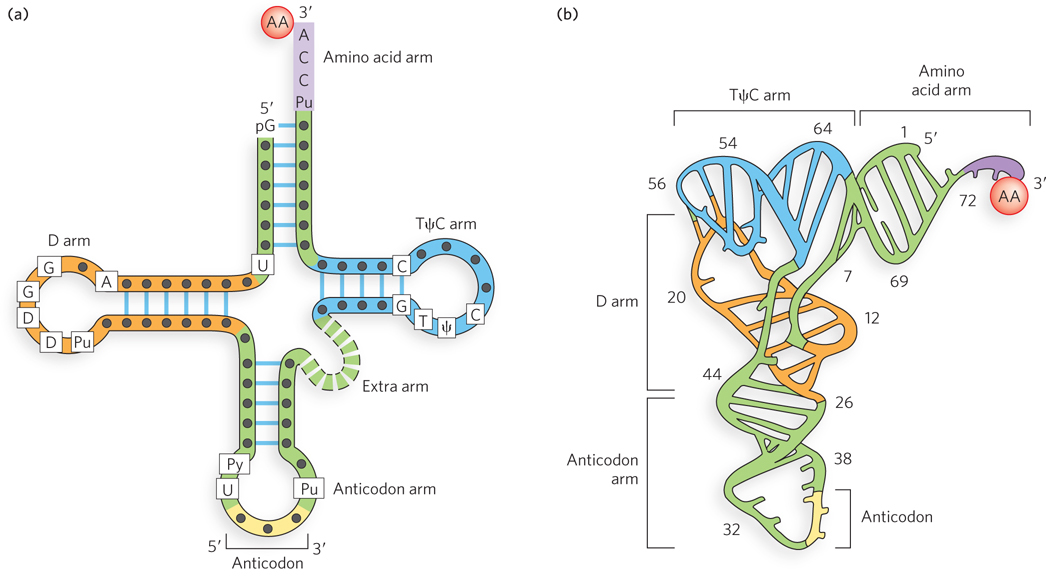
Transfer RNAs are relatively small, single-
When drawn in two dimensions, the hydrogen-
592
KEY CONVENTION
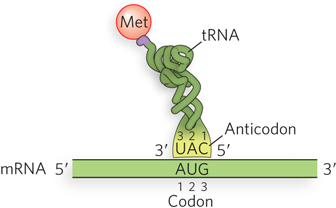
The nucleotide positions of the codon (mRNA) and anticodon (tRNA) are numbered 1, 2, and 3, in the 5′→3′ direction. Due to the antiparallel base pairing between the anticodon and the codon, the numbering of nucleotides in the anticodon is the reverse of that in the codon. Thus, anticodon nucleotide 3 pairs with codon nucleotide 1.
As shown in Figure 17-2, the anticodon is some distance from the 3′ terminus of the amino acid arm (where the amino acid is attached), and thus the anticodon cannot directly specify the correct amino acid. Indeed, the ribosome will link any two amino acids lined up correctly on the mRNA, regardless of whether the tRNA is charged with a correct or an incorrect amino acid. It is the function of the aminoacyl-
The Genetic Code Is Degenerate
As we have seen, there are 64 unique ways to combine four different nucleotides in a triplet codon sequence, yet there are only 20 common amino acids. Therefore, either some codons are not found in mRNA sequences, or—
All 64 codons of the genetic code are used in some fashion: 61 for coding amino acids and 3 for specifying the termination of translation (Figure 17-4). Three amino acids—
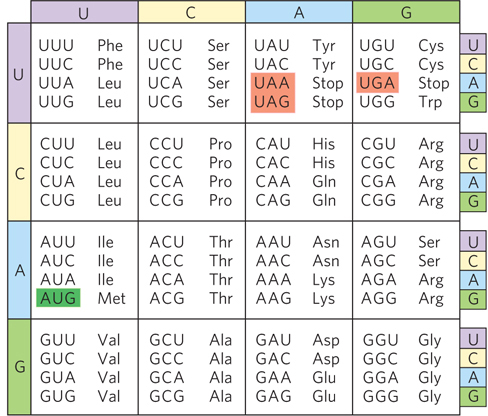
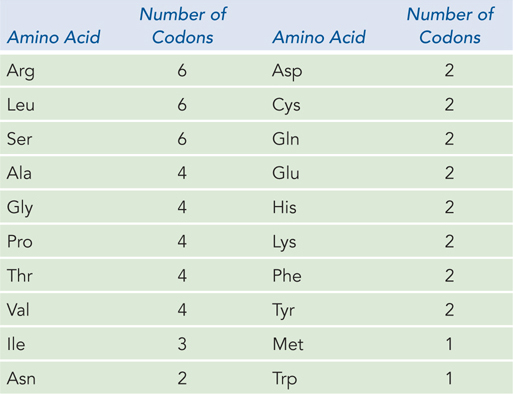
When several different codons specify one amino acid, the first two nucleotides of each codon are the primary determinants of specificity, and the difference between the codons usually lies at the third position. For example, alanine is specified by the triplets GCU, GCC, GCA, and GCG. When four codons specify the same amino acid, they are referred to as a codon family. Within a codon family, the first two nucleotides are the same, the nucleotide at the third position does not matter, and base pairing of the first two nucleotides carries the information needed to specify the amino acid. Many amino acids are specified by two codons in which the third nucleotide is either a purine in both or a pyrimidine in both.
593
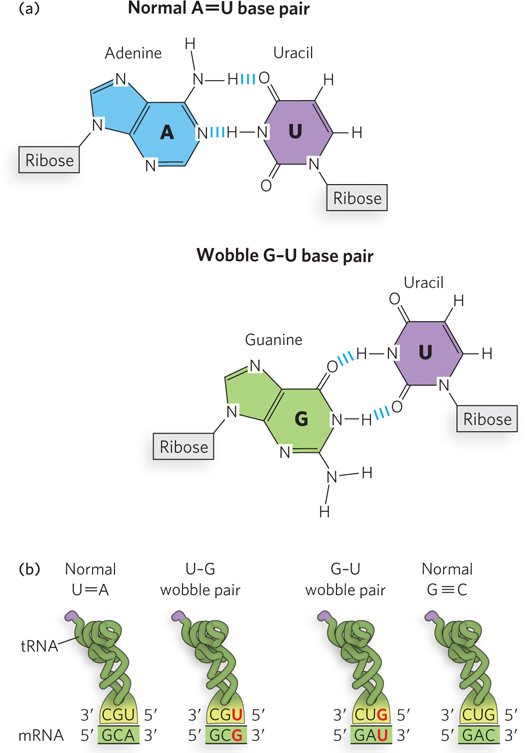
Wobble Enables One tRNA to Recognize Two or More Codons
If all three nucleotides in an mRNA codon were needed to form Watson-
As noted above, when several codons specify the same amino acid, usually the third nucleotide is the only difference. In some cases the cell uses different tRNAs for the different codons that encode the same amino acid, and in these cases a single aminoacyl-
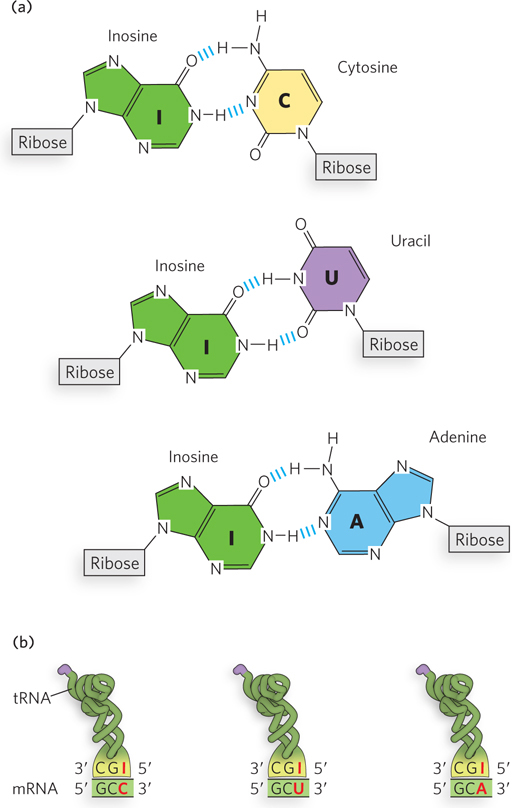
The anticodon in some tRNAs includes inosine (designated I; this nucleotide residue contains the base hypoxanthine), which can hydrogen-
594
The process by which some tRNAs can recognize more than one codon was formalized by Crick, who proposed a set of four relationships known as the wobble hypothesis:
The first two bases of an mRNA codon always form Watson-
Crick base pairs with the corresponding bases of the tRNA anticodon, and they confer most of the coding specificity. The first base of the anticodon (reading in the 5′→3′ direction) pairs with the third base of the codon and determines the number of codons recognized by the tRNA. When the first nucleotide of the anticodon is C or A, base pairing is specific, and only one codon is recognized by that tRNA. When the first nucleotide is U or G, base pairing is less specific, and two different codons may be read by the same tRNA. When the first nucleotide of an anticodon is I, three different codons can be recognized—
the maximum number for any tRNA. When an amino acid is specified by several different codons, codons that differ in either of the first two bases require different tRNAs.
A minimum of 32 tRNAs are required to translate all 61 codons (31 tRNAs for the amino acids and 1 for initiation).
Specific Codons Start and Stop Translation
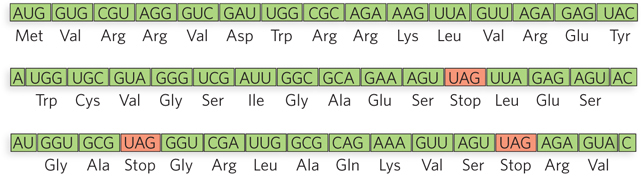
As we describe in Section 17.2 and in further detail in Chapter 18, the codons in an mRNA molecule are read by the ribosome in the 5′→3′ direction, without gaps. Because each codon has three nucleotides, an mRNA sequence has the potential to encode three different polypeptide sequences, depending on exactly where translation begins—
595
Specific sequences in mRNA signal the start of translation and thus define the reading frame. Translation almost always starts at an AUG codon, which specifies the amino acid methionine; this codon is referred to as the initiation codon or start codon. Occasionally, the codon GUG (usually encoding valine) or UUG (usually encoding leucine) is used as an initiation codon, yet the mRNA is still recognized by the initiating methionine tRNA, inserting a Met residue. The mRNA can also have internal AUG (or GUG and UUG) codons, but translation does not begin at these internal positions. In bacteria, there is a specific sequence in the mRNA next to the initiating AUG (or GUG) that binds the ribosome and directs it to start translation. In eukaryotes, the ribosome is directed to the 5′ terminus of the mRNA, after which it slides down the mRNA; translation can then be initiated at various sites, influenced by a nucleotide sequence known as the Kozak sequence (discussed in Chapter 18).
The three codons (UAA, UAG, and UGA) that signal the end of translation and do not specify any amino acid are called termination codons or stop codons (or, sometimes, nonsense codons; see Figure 17-7). Termination codons signal the ribosome to dissociate from the newly synthesized polypeptide chain. When the ribosome encounters a termination codon, a release factor associates with the ribosome and terminates protein synthesis. Release factors, even though they recognize specific codons, are proteins. In a fascinating display of molecular mimicry, the three-
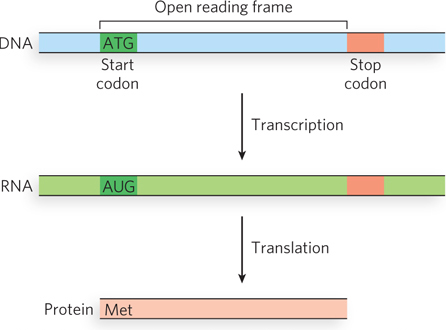
With 3 of the 64 codons acting as terminators, a random mRNA sequence should contain 1 stop codon for every 20 codons or so. A long sequence of nucleotide triplets with no stop codons is unlikely to occur by chance, and it generally encodes a protein. Such a sequence is known as an open reading frame, or ORF (Figure 17-8). For example, the average length of a gene in E. coli is 1,000 nucleotides, or about 333 codons that lack a termination codon.
The Genetic Code Resists Single-Base Substitution Mutations
The degeneracy of the genetic code enables it to absorb many types of point mutations without serious consequence (see Chapter 12 for a more complete discussion of types of mutation). A single-
The ability of the code to withstand mutation is even more apparent when we consider that the most frequent mutation is a transition mutation, in which a purine is replaced by another purine (A·T replaced by G≡C, or G≡C by A·T). All three positions of the codon confer some type of protection from deleterious transition mutations. A transition mutation in the third position rarely cause a change at all, due to the wobble rules. Even the functioning of UAA and UAG stop codons is protected from damage by a transition mutation in the third position.
A transition mutation in the first position of most codons does result in an amino acid change, but the change is usually to an amino acid that is chemically similar to the original amino acid. This is especially evident for hydrophobic amino acids, as shown in the leftmost column of Figure 17-4. These codons contain U in the second position, and replacement of the first nucleotide results in a codon that specifies another hydrophobic residue. For example, a codon change of GUU to AUU results in an exchange of Ile for Val. Had the GUU codon been altered to CUU, the protein would contain Leu instead of Val. These amino acids have similar chemical properties and thus are much more likely to conserve the protein function than if a hydrophobic residue were replaced by a polar residue. The second position of a codon generally determines whether it encodes a polar (if nucleotide 2 is a purine) or hydrophobic (if a pyrimidine) amino acid. Therefore, transition mutations in the second position also tend to conserve the chemical nature of the protein product.
Errors produced during translation occur most frequently in the codon’s first and third nucleotide positions, but the redundancy in coding due to wobble in the third position removes most errors. Eight amino acids are specified by codons that contain any of the four nucleotides in the third position. This, coupled with the fact that any purine-
596
Computational studies that examine the theoretical ability of randomly generated genetic codes to withstand the effects of mutation show that most codes would be much less resistant to mutation than is the code actually used by cells. In fact, the probability of arriving by chance at a code that is as resistant to mutation as the genetic code of living organisms is about one in a million. These considerations suggest that the code was extensively honed by natural selection before the divergence of other life forms from LUCA, the ancestral cell.
Some Mutations Are Suppressed by Special tRNAs
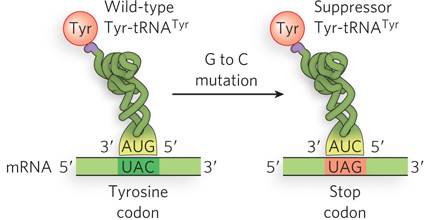
Far more deleterious than missense mutations are codon changes that result in a termination codon. These nonsense mutations abort protein synthesis, resulting in an incomplete protein that is rarely functional. The gene can be restored to function by a second mutation that converts the nonsense codon to a missense codon or by a mutation in a tRNA that suppresses termination at the nonsense codon by inserting an amino acid at that position (Figure 17-9). Mutant tRNAs that function at a stop codon to allow translation to continue are called suppressor tRNAs. For example, a change in the anticodon of tRNATyr from 5′-GUA to 5′-CUA results in an altered tRNATyr that inserts tyrosine at a 5′-UAG termination codon (Figure 17-10). Depending on the suppressor tRNA, other amino acids could be inserted at a 5′-UAG termination codon. In theory, any tRNA with an anticodon that is one base pair different from a stop codon could become a suppressor tRNA if a single point mutation occurred in the right place in the anticodon. In fact, suppressor mutations are rare in vivo, but this phenomenon has been harnessed as a tool in the molecular biology laboratory.
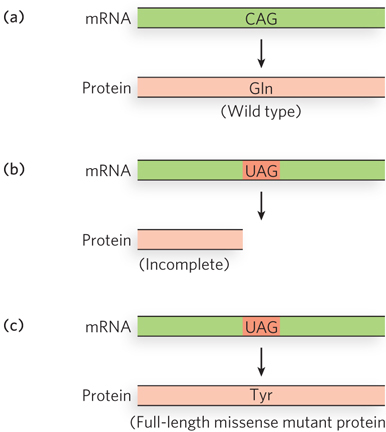
Although suppressor tRNAs usually carry a single-
Suppression must not be too efficient, otherwise normal termination codons would also be suppressed, leading to abnormally long protein products—
597
An example of suppression in E. coli is tRNATyr with the anticodon 5′-GUA. E. coli contains three identical tRNATyr genes, but one is much more highly transcribed than the others. The tRNATyr suppressor mutation, which changes the anticodon to 5′-CUA and thus recognizes the 5′-UAG stop codon, is found in one of the minor, less-
SECTION 17.1 SUMMARY
Transfer RNAs are small RNA molecules that can covalently attach at their 3′ end to an amino acid. The triplet anticodon in tRNA pairs with a triplet codon in mRNA, and this pairing mediates translation of the nucleotide sequence in mRNA into the amino acid sequence of a protein.
The genetic code is degenerate, because most amino acids are specified by two or more codons. One tRNA often reads two codon sequences, due to noncanonical or wobble base pairing at the third nucleotide position of the codon. When the anticodon contains inosine (I), a modified nucleotide residue, the tRNA recognizes three different codons, ending in A, C, or U.
An AUG codon, specifying methionine, typically initiates protein synthesis. The three termination codons do not specify an amino acid, but instead instruct the ribosome to stop translation.
Due to codon assignments and the degeneracy of the genetic code, single-
base substitution mutations generally result in codons that specify the same or similar amino acids; nonsense mutations result in a stop codon that can lead to inactive protein. Mutant tRNAs that carry a single- nucleotide change in the anticodon can suppress nonsense mutations by inserting an amino acid in the polypeptide at the mutant termination codon.