13.3 Multiple Regression
 This page includes Statistical Videos
This page includes Statistical VideosOBJECTIVES By the end of this section, I will be able to …
- Find the multiple regression equation, interpret the multiple regression coefficients, and use the multiple regression equation to make predictions.
- Calculate and interpret the adjusted coefficient of determination.
- Perform the F test for the overall significance of the multiple regression.
- Conduct t tests for the significance of individual predictor variables.
- Explain the use and effect of dummy variables in multiple regression.
- Apply the strategy for building a multiple regression model.
1 Finding the Multiple Regression Equation, Interpreting the Coefficients, and Making Predictions
Thus far, we have examined the relationship between the response variable y and a single predictor variable x. In our data-filled world, however, we often encounter situations where we can use more than one x variable to predict the y variable. This is called multiple regression.
Regression analysis using a single y variable and a single x variable is called simple linear regression.
Multiple regression describes the linear relationship between one response variable y and more than one predictor variable, x1,x2,x3,…. The multiple regression equation is an extension of the regression equation
ˆy=b0+b1x1+b2x2+…bkxk
where k represents the number of x variables in the equation, and b0,b1,b2,…bk represent the multiple regression coefficients.
The interpretation of the regression coefficients is similar to the interpretation of the slope b1 in simple linear regression, except that we also state that the other x variables are held constant. The interpretation of the y intercept b0 is similar to the simple linear regression case. The next example illustrates the multiple regression equation, and shows how to interpret the multiple regression coefficients.
EXAMPLE 11 Multiple regression equation, coefficients, and prediction
breakfastcereals3
The data set Breakfast Cereals includes several predictor variables and one response variable, y=(nutritional) rating.
- Use technology to find the multiple regression equation for predicting y=rating, using x1=fiber and x2=sugar. State the equation with a sentence.
- State the values of the multiple regression coefficients.
- Interpret the multiple regression coefficients for using x1=fiber and x2=sugar.
- Use the multiple regression equation to predict the rating of a breakfast cereal with 5 mg of fiber and 10 mg of sugar.
When we perform a multiple regression of one variable on (or against or versus) a set of other variables, the first variable is always the y variable, and the set of variables following the word on are the x variables.
Solution
Using the instructions in the Step-by-Step Technology Guide at the end of this section, we open the Breakfast Cereals data set and perform a multiple regression of y=rating on x1=fiber and x2=sugar. Note that this does not represent extrapolation, as there are cereals in the data set that have either zero grams of fiber (such as Cap’n Crunch) or zero grams of sugar (such as Cream of Wheat).
A partial Minitab printout is shown in Figure 20. A partial SPSS printout is in Figure 21. The multiple regression equation is
ˆy=b0+b1x1+b2x2=52.22+2.869(fiber)−2.246(sugar)
The estimated nutritional rating equals 52.22 points plus 2.869 times the number of grams of fiber minus 2.246 times the number of grams of sugar.
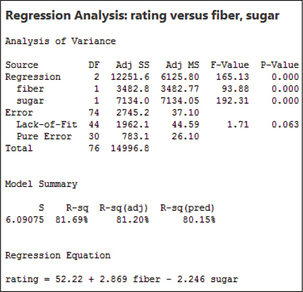 FIGURE 20 Multiple regression equation in Minitab.
FIGURE 20 Multiple regression equation in Minitab. FIGURE 21 Multiple regression equation in SPSS.
FIGURE 21 Multiple regression equation in SPSS.- The values of the multiple regression coefficients are b0=52.22, b1=2.869, and b2=−2.246.
- The multiple regression coefficients are interpreted as follows:
- b0=52.22 (y intercept). The estimated nutritional rating when there are zero grams of fiber and zero grams of sugar is 52.22.
- b1=2.869. For every increase of one gram of fiber, the estimated increase in nutritional rating is 2.869 points, when the amount of sugar is held constant.
- b2=−2.246. For every increase of one gram of sugar, the estimated decrease in nutritional rating is 2.246 points, when the amount of fiber is held constant.
 When making predictions in multiple regression, beware of the pitfalls of extrapolation, just like those for simple linear regression. Further, in multiple regression, the values for all predictor variables must lie within their respective ranges. Otherwise, the prediction represents extrapolation, and it may be misleading.Page 745
When making predictions in multiple regression, beware of the pitfalls of extrapolation, just like those for simple linear regression. Further, in multiple regression, the values for all predictor variables must lie within their respective ranges. Otherwise, the prediction represents extrapolation, and it may be misleading.Page 745 To find the predicted rating for a breakfast cereal with x1=fiber=5 and x2=sugar=10, we plug these values into the multiple regression equation from part (a):
ˆy=52.22+2.869(5)−2.246(10)=44.105
The predicted nutritional rating for a breakfast cereal with 5 mg of fiber and 10 mg of sugar is 44.105.
NOW YOU CAN DO
Exercises 9–16.
2 The Adjusted Coefficient of Determination
Recall from Section 4.3 that we measure the goodness of a regression equation using the coefficient of determination r2=SSR/SST. In multiple regression, we use the same formula for the coefficient of determination (though the letter r is promoted to a capital R).
Multiple Coefficient of Determination R2
The multiple coefficient of determination is given by:
R2 = SSRSST 0≤ R2 ≤ 1
where SSR is the sum of squares regression, and SST is the total sum of squares. The multiple coefficient of determination R2 represents the proportion of the variability in the response y that is explained by the multiple regression equation.
Unfortunately, when a new x variable is added to the multiple regression equation, the value of R2 always increases, even when the variable is not useful for predicting y. So, we need a way to adjust the value of R2 as a penalty for having too many unhelpful x variables in the equation. This is the adjusted coefficient of determination, R2adj.
Adjusted Coefficient of Determination R2adj
The adjusted coefficient of determination is given by the formula
R2adj=1−(1−R2)(n−1n−k−1)
where n is the number of observations, k is the number of x variables, and R2 is the multiple coefficient of determination. R2adj is always smaller than R2.
R2adj is preferable to R2 as a measure of the goodness of a regression equation, because R2adj will decrease if an unhelpful x variable is added to the regression equation. The interpretation of R2adj is similar to R2.
EXAMPLE 12 Calculating and interpreting the adjusted coefficient of determination R2adj
For the multiple regression in Example 11, we have SSR=12,251.6 and SST=14,996.8.
- Calculate the multiple coefficient of determination for R2.
- There are n= 77 observations. Compute and interpret the adjusted coefficient of determination R2adj.
Solution
- R2 = SSRSST = 12,251.614,996.8 ≈ 0.8169
- R2adj = 1− (1−R2)(n−1n−k−1) = 1 − (1−0.8169)(77−177−2−1)≈ 0.8120
Therefore, the multiple regression equation accounts for 81.2% of the variability in nutritional rating.
NOW YOU CAN DO
Exercises 17–20.
Thus far, in this section, we have used descriptive methods for multiple regression. Next, we learn how to perform inference in multiple regression.
3 The F Test for the Overall Significance of the Multiple Regression
The multiple regression model is an extension of the regression model from Section 13.1, and it approximates the relationship between y and the collection of x variables.
Multiple Regression Model
The population multiple regression equation is
y=β0+β1x1+β2x2+⋯+βkxk+ε
where β0,β1,β2,⋯βk are the parameters of the population regression equation, k is the number of x variables, and ε represents the random error term that follows a normal distribution with mean 0 and constant variance σ2.
The population parameters β0 , β1 , β2, … βk are unknown, so we must perform inference to learn about them. We begin by asking, is our multiple regression useful? To answer this question, we perform the F test for the overall significance of the multiple regression.
Our multiple regression will not be useful if all of the population parameters equal zero, for this will result in no relationship at all between the y variable and the set of x variables. Thus, the hypotheses for the F test are
- H0 : β1 = β2 = ⋯ = βk = 0 No linear relationship exists between y and any of the x variables. The overall multiple regression is not significant.
- Ha : . A linear relationship exists between and at least one of the variables. The overall multiple regression is significant.
The test is not valid if there is strong evidence that the regression assumptions have been violated. The multiple regression assumptions are similar to those for simple linear regression. We illustrate the steps for the test with the following example.
states that at least one of the , not that all of the .
EXAMPLE 13 test for the overall significance of the multiple regression
For the breakfast cereal data, we are interested in determining whether a linear relationship exists between , and and .
- Determine whether the regression assumptions have been violated.
- Perform the test for the overall significance of the multiple regression of rating on vitamins and sodium, using level of significance .
Solution
- Figure 22, a scatterplot of the residuals versus fitted values, contains no strong evidence of unhealthy patterns. Although the two cereals, All-Bran with Extra Fiber and Product 19, are unusual, the vast majority of the data suggest that the independence, constant variance, and zero-mean assumptions are satisfied. Figure 23 indicates that the normality assumption is satisfied.
- The Minitab multiple regression results are provided in Figure 24.Page 747
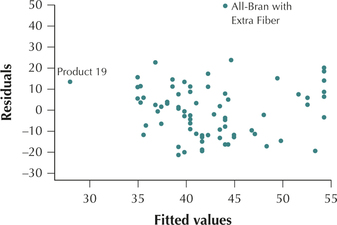 FIGURE 22 Scatterplots of residuals versus fitted values.
FIGURE 22 Scatterplots of residuals versus fitted values.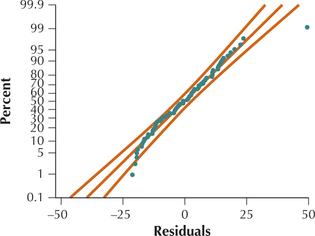 FIGURE 23 Normal probability plot of the residuals.FIGURE 24 Minitab results for regression of rating on vitamins and sodium.
FIGURE 23 Normal probability plot of the residuals.FIGURE 24 Minitab results for regression of rating on vitamins and sodium.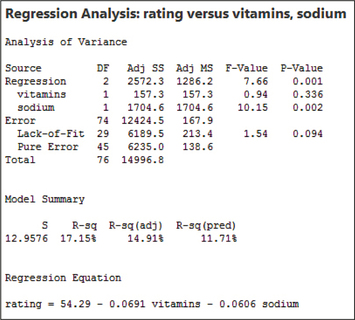
Step 1 State the hypotheses and the rejection rule. We have variables, so the hypotheses are
- . No linear relationship exists between rating and either vitamins and sodium. The overall multiple regression is not significant.
- and . A linear relationship exists between rating and at least one of vitamins and sodium. The overall multiple regression is significant.
Reject if the .
- Step 2 Find the statistic and the -value. These are located in the ANOVA table portion of the printout, denoted Analysis of Variance. From Figure 24, we have and . The -value represents .
- Step 3 Conclusion and interpretation. The , so we reject . There is evidence, at level of significance , for a linear relationship between rating and at least one of vitamins and sodium. The overall multiple regression is significant.
The ANOVA table is a convenient way to organize a set of statistics, which can be used to perform multiple regression as well as ANOVA.
NOW YOU CAN DO
Exercises 21, 22, 27, and 28.
Once we find that the overall multiple regression is significant, we may ask: Which of the individual variables have a significant linear relationship with the response variable ?
4 The Test for the Significance of Individual Predictor Variables
To determine whether a particular variable has a significant linear relationship with the response variable , we perform the test that was used in Section 13.1 to test for the significance of that variable. One may perform as many such tests as there are variables in the model, which is assuming the overall test is significant. We illustrate the steps for performing a set of tests using the following example.
EXAMPLE 14 Performing a set of tests for the significance of a set of individual variables
Using the results from Example 13, do the following, using level of significance :
- Test 1: Test whether a significant linear relationship exists between rating and vitamins.
- Test 2: Test whether a significant linear relationship exists between rating and sodium.
Solution
The regression assumptions were verified in Example 13.
Step 1 For each hypothesis test, state the hypotheses and the rejection rule. Vitamins is , and sodium is , so the hypotheses are
- Test 1:
- . No linear relationship exists between rating and vitamins.
- . A linear relationship exists between rating and vitamins.
- Reject if the .
- Test 2:
- . No linear relationship exists between rating and sodium.
- . A linear relationship exists between rating and sodium.
- Reject if the .
- Test 1:
- Step 2 For each hypothesis test, find the statistic and the -value. Figure 25 is an excerpt of the Minitab results from Figure 24, with the relevant statistics and -values highlighted. For Test 1, the -value represents , because it is a two-tailed test. For Test 2, the -value represents .
- Test 1: , with -value 0.336.
- Test 2: , with -value 0.002.
 FIGURE 25 statistics and -values for the test for the significance of the variables vitamins and sodium.
FIGURE 25 statistics and -values for the test for the significance of the variables vitamins and sodium. - Step 3 For each hypothesis test, state the conclusion and interpretation.
- Test 1: The , which is not . Therefore, we do not reject . There is insufficient evidence of a linear relationship between rating and vitamins when sodium is held constant. Perhaps surprisingly, the variable vitamins is not significant, meaning that the amount of vitamins in the breakfast cereal is not helpful in predicting nutritional rating.
- Test 2: The , which is . Therefore, we reject . There is evidence of a linear relationship between rating and sodium when vitamins is held constant. The variable sodium is significant, meaning that the amount of sodium in the breakfast cereal is helpful in predicting nutritional rating.
NOW YOU CAN DO
Exercises 23 and 30.
So far, all of our variables have been continuous. But what if we want to include a categorical variable as a predictor?
5 Dummy variables in Multiple regression
The data set Pulse and Temp contains the heart rate, body temperature, and sex of 130 men and women. We want to use and to predict . However, sex is a categorical variable, so we must recode the values of as follows:
The variable is called a dummy variable, because it recodes the values of the binomial (categorical) variable sex into values of 0 and 1.
A dummy variable is a predictor variable used to recode a binomial categorical variable in regression, and taking values 0 or 1.
This recoding will provide us with two different regression equations, one for the females and one for the males , shown here:
- Females:
- Males:
Note that these two regression equations have the same slope , but different intercepts. The females have intercept , whereas the males have intercept . See Figure 29 on page 750. The difference in intercepts is , which is the coefficient of the dummy variable . Let us illustrate with an example.
EXAMPLE 15 Dummy variables in multiple regression
- Verify that the regression assumptions are met.
- Perform a multiple regression of on and , using level of significance . Find the two regression equations, one for females and the other for males.
- Construct a scatterplot of versus , using different-shaped points to show the different sexes. Place the two regression equations on the scatterplot.
- Interpret the coefficient of the dummy variable .
Solution
Figures 26 and 27 contain no evidence of unhealthy patterns. We therefore conclude that the regression assumptions are verified.
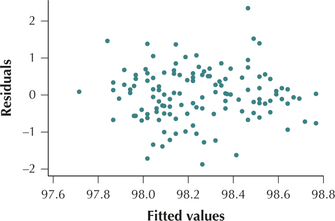 FIGURE 26 Scatterplot of residuals versus fitted values.
FIGURE 26 Scatterplot of residuals versus fitted values.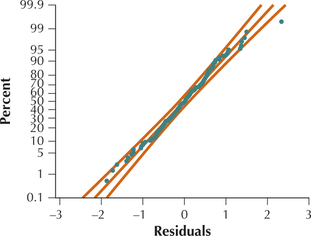 FIGURE 27 Normal probability plot of the residuals.Page 750
FIGURE 27 Normal probability plot of the residuals.Page 750- Figure 28 contains the multiple regression results. The -value for the test is 0.001, which is , so we conclude that the overall regression is significant. The regression results tell us that , , and . Thus, our two regression equations are:
- Females:
- Males:
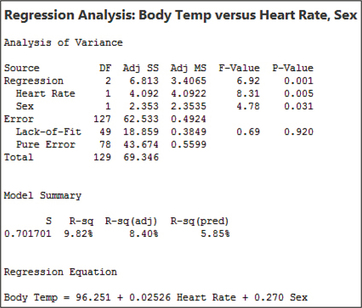 FIGURE 28 Results for multiple regression of on and .
FIGURE 28 Results for multiple regression of on and .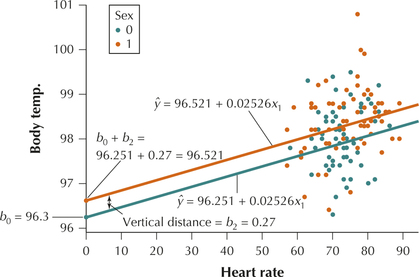 FIGURE 29 Scatterplot showing parallel regression lines when using dummy variables.
FIGURE 29 Scatterplot showing parallel regression lines when using dummy variables. - Figure 29 contains the scatterplot of versus , with the orange dots representing females and the blue dots representing males. The regression lines are shown, orange for females, blue for males. Note that the regression lines are parallel, because they each have the same slope . So the only difference in the lines is the intercepts.
- For females, the intercept is .
- For males, the intercept is simply .
- The vertical distance between the parallel regression lines equals , as shown in Figure 29. Thus, we interpret the coefficient of the dummy variable as the estimated increase in for those observations with (females), as compared to those with (males), when heart rate is held constant. That is, for the same heart rate, females have a body temperature that is higher than that of males, by an estimated 0.27 degrees.
NOW YOU CAN DO
Exercise 29.
6 Strategy for Building a Multiple Regression Model
In order to bring together all you have learned of multiple regression, we now present a general strategy for building a multiple regression model.
Strategy for Building a Multiple Regression Model
Step 1 The Test.
Construct the multiple regression equation using all relevant predictor variables. Apply the test for the significance of the overall regression, in order to make sure that a linear relationship exists between the response and at least one of the predictor variables.
Page 751Step 2 The Tests.
Perform the tests for the individual predictors. If at least one of the predictors is not significant (that is, its -value is greater than level of significance ), then eliminate the variable with the largest -value from the model. Ignore the -value of . Repeat Step 2 until all remaining predictors are significant.
We eliminate only one variable at a time. It may happen that eliminating one nonsignificant variable will nudge a second, formerly nonsignificant, variable into significance.
Step 3 Verify the Assumptions.
For your final model, verify the regression assumptions.
Step 4 Report and Interpret Your Final Model.
- Provide the multiple regression equation for your final model.
- Interpret the multiple regression coefficients so that a nonstatistician could understand.
- Report and interpret the standard error of the estimate s and the adjusted coefficient of determination .
We illustrate this strategy, known as backward stepwise regression, in the following example.
EXAMPLE 16 Strategy for building a multiple regression model
baseball2013

The author of this book first became interested in the field of statistics through the enjoyment of sports statistics, especially baseball, which is packed with interesting statistics. Today, professional sports teams are seeking competitive advantage through the analysis of data and statistics, such as Sabermetrics (Society of American Baseball Research, www.sabr.org), as shown in the motion picture Moneyball.
Suppose a baseball researcher is interested in predicting , using the data set Baseball 2013 and the following predictor variables:
Use the Strategy for Building a Multiple Regression Model to build the best multiple regression model for predicting the number of runs scored using these predictor variables, at level of significance .
Solution
The data set Baseball 2013 contains the batting statistics of the players in Major League Baseball who had at least 100 at-bats during the 2013 season (Source: www.seanlahman.com/baseball-archive/statistics).
- Step 1 The Test. Figure 30 shows the Minitab results of a regression of on the set of predictor variables . The -value for the test is significant, so we know that a linear relationship exists between and at least one of the variables.
Step 2 The test (the first time). In Figure 30, the -value for Batting Average is greater than level of significance . We therefore eliminate the Batting Average from the model. Perhaps surprisingly, a player's batting average is evidently not helpful in predicting the number of runs that player will score when all other predictors are held constant.
Page 752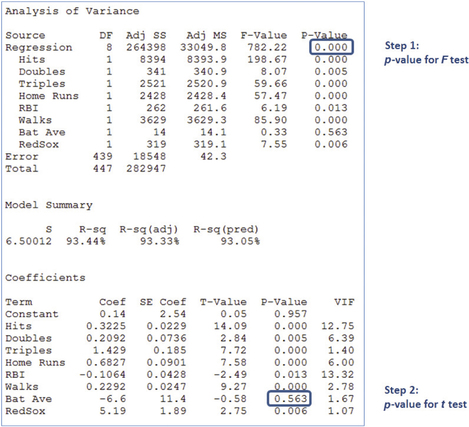 FIGURE 30 Step 1: test is significant.
FIGURE 30 Step 1: test is significant.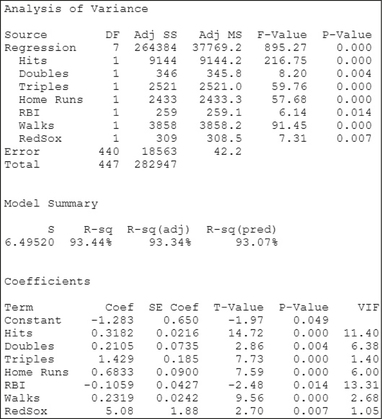 FIGURE 31 All variables are significant; we have our final model.
FIGURE 31 All variables are significant; we have our final model.- Step 2 The test (the second time). We repeat Step 2 as long as there are variables with -values greater than level of significance . Figure 31 shows the results of performing the multiple regression of on all the variables except Batting Average. No further variables have -values below 0.05; therefore, no further variables are excluded from the model. In other words, we have our final model.
- Step 3 Verify the assumptions. For our final model, we now verify the regression assumptions. Figures 32 and 33 show no patterns for the bulk of the data that would indicate a violation of the regression assumptions. We therefore conclude that the regression assumptions are verified.
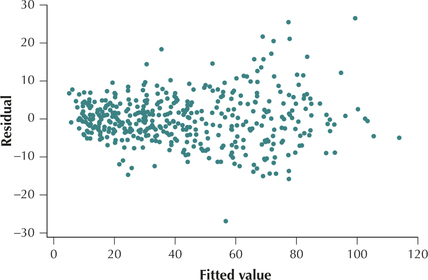 FIGURE 32 Scatterplot of residuals versus fitted values.
FIGURE 32 Scatterplot of residuals versus fitted values.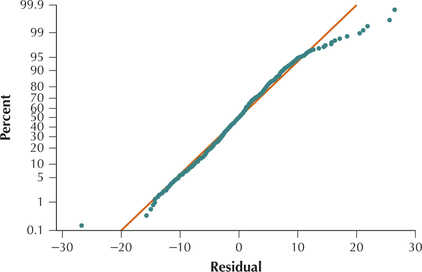 FIGURE 33 Normal probability plots of the residuals.
FIGURE 33 Normal probability plots of the residuals. - Step 4 Report and interpret your final model.
The multiple regression equation for the final model is shown here.
Page 753- We interpret the coefficient for Hits, and leave to the exercises the interpretation of the other multiple regression coefficients. “For each additional hit that a player makes, the estimated increase in the number of runs that player will score is 0.3182, when all the other variables are held constant.”
- The standard error of the estimate for the final model is . That is, using the multiple regression equation in (a), the size of the typical prediction error will be about 6.5 runs. The value of the adjusted coefficient of determination is . In other words, 93.07% of the variability in the number of runs scored is accounted for by this multiple regression equation.
NOW YOU CAN DO
Exercises 24–26 and 31–33.