Protein-Coding Genes May Be Solitary or Belong to a Gene Family
The nucleotide sequences within chromosomal DNA can be classified on the basis of their structure and function, as shown in Table 8-1. Here we examine the properties of each class, beginning with protein-
In multicellular organisms, roughly 25–
Duplicated genes constitute the second group of protein-
Page 306
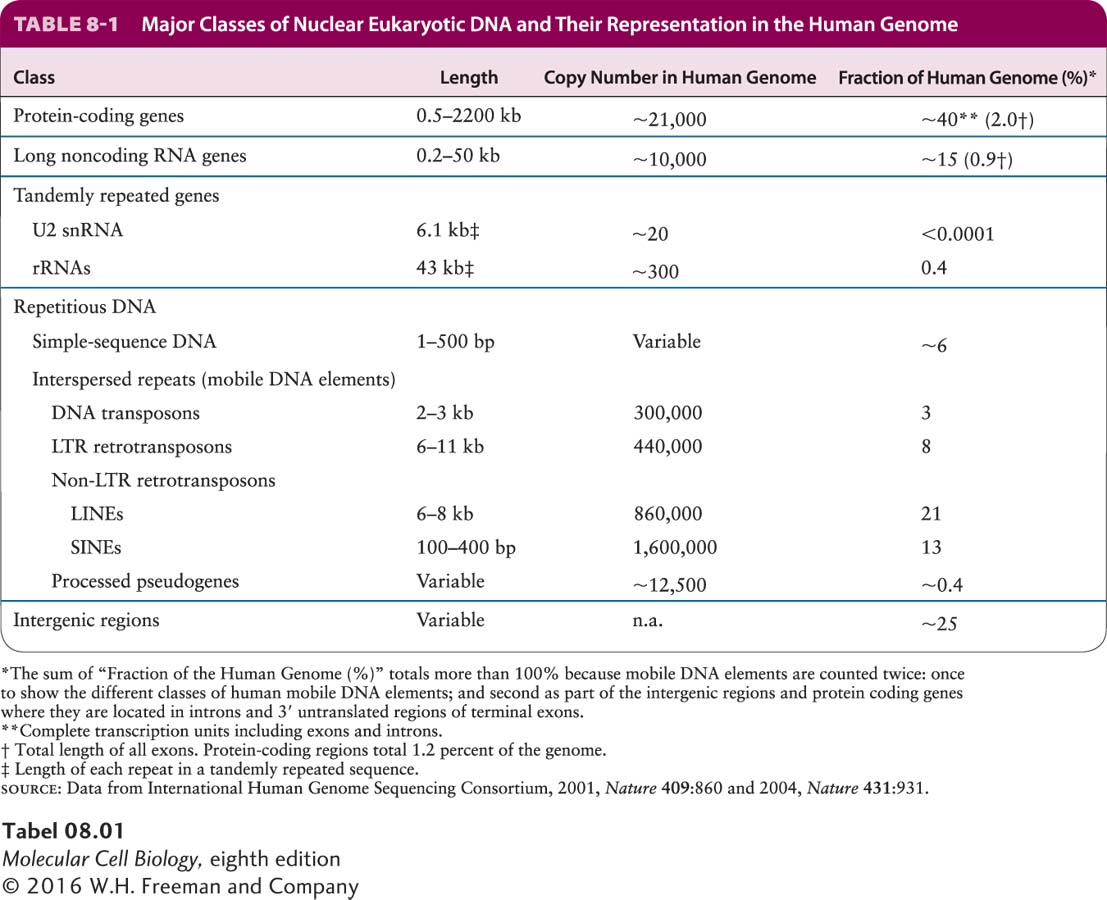
The genes encoding the β-likeas globins are a good example of a gene family. As shown in Figure 8-4a, the β-likeas globin gene family contains five functional genes, designated HBB (encoding the most abundant adult β-globin), HBD (a minor adult β-globin), HBG1 and HBG2 (fetal β-globins), and HBE1 (embryonic β-globin). Two identical β-likeas globin polypeptides combine with two identical α-likes globin polypeptides (encoded by another gene family expressed during embryonic, fetal, and adult stages of development) and four heme prosthetic groups to form a hemoglobin molecule (see Figures 3-14 and 12-20). All the hemoglobins formed from the different α-likes and β-likeas globins carry oxygen in the blood, but they exhibit somewhat different properties that are suited to their specific functions in human physiology. For example, hemoglobins containing either the HBG1- or HBG2-encoded polypeptides are expressed only during fetal life. Because these fetal hemoglobins have a higher affinity for oxygen than adult hemoglobins, they can effectively extract oxygen from the maternal circulation in the placenta. The lower oxygen affinity of adult hemoglobins, which are expressed after birth, permits better release of oxygen to the tissues, especially muscles, which have a high demand for oxygen during exercise. The embryonic hemoglobin assembled from polypeptides encoded by the HBE1 gene and the embryonic α-likes globin gene HBZ has an even higher affinity for oxygen than the fetal and adult hemoglobins.
The different β-like globin genes arose by duplication of an ancestral gene, most likely as the result of unequal crossing over during meiotic recombination in a developing germ cell (egg or sperm) (see Figure 8-2b). Over evolutionary time, the two copies of the gene that resulted accumulated random mutations, resulting in sequence drift. Beneficial mutations that conferred some refinement in the basic oxygen-
Page 307
Two regions in the human β-like globin gene cluster contain nonfunctional sequences, called pseudogenes, that are similar to the functional β-like globin genes (see Figure 8-4a). Sequence analysis shows that these pseudogenes have the same apparent exon–
Duplications of segments of a chromosome (called segmental duplication) occurred fairly often during the evolution of multicellular plants and animals. As a result, a large fraction of the genes in these organisms today have been duplicated, allowing the process of sequence drift to generate gene families and pseudogenes. The extent of sequence divergence between duplicated copies of the genome and characterization of the homologous genomic sequences in related organisms allow us to estimate the time in evolutionary history when the duplication occurred. For example, the human fetal globin genes (HGB1 and HGB2) evolved following the duplication of a 5.5-
Although members of gene families that arose relatively recently in evolution, such as the genes of the human β-globin family, are often found near one another on the same chromosome, members of gene families may also be found on different chromosomes in the same organism. This is the case for the human α-like globin genes, which were separated from the β-globin genes by an ancient chromosomal translocation. Both the α- and β-globin genes evolved from a single ancestral globin gene that was duplicated (see Figure 8-2b) to generate the predecessors of the contemporary α- and β-globin genes in mammals. Both the primordial α- and β-globin genes then underwent further duplications to generate the different genes of the α- and β-globin gene clusters found in mammals today.
Several different gene families encode the various proteins that make up the cytoskeleton. These proteins are present in varying amounts in almost all cells. In vertebrates, the major cytoskeletal proteins are the actins, tubulins, and intermediate filament proteins such as the keratins, discussed in Chapters 17, 18, and 20. We examine the origin of one such family, the tubulin family, in Section 8.4. Although the physiological rationale for the cytoskeletal protein families is not as obvious as it is for the globins, the different members of a family probably have similar but subtly different functions suited to the particular type of cell in which they are expressed.