29.3
The Transcription Products of Eukaryotic Polymerases Are Processed
Virtually all the initial products of transcription are further processed in eukaryotes. For example, primary transcripts (pre-mRNA molecules), the products of RNA polymerase II action, acquire a cap at their 5′ ends and a poly(A) tail at their 3′ ends. Most importantly, nearly all mRNA precursors in higher eukaryotes are spliced. Introns are precisely excised from primary transcripts, and exons are joined to form mature mRNAs with continuous messages. Some mature mRNAs are only a tenth the size of their precursors, which can be as large as 30 kb or more. The pattern of splicing can be regulated in the course of development to generate variations on a theme, such as membrane-bound or secreted forms of antibody molecules. Alternative splicing enlarges the repertoire of proteins in eukaryotes and is one clear illustration of why the proteome is more complex than the genome. The particular processing steps and the factors taking part vary according to the type of RNA polymerase.
RNA polymerase I produces three ribosomal RNAs
Several RNA molecules are key components of ribosomes. RNA polymerase I transcription produces a single precursor (45S in mammals) that encodes three RNA components of the ribosome: the 18S rRNA, the 28S rRNA, and the 5.8S rRNA (Figure 29.27). The 18S rRNA is the RNA component of the small ribosomal subunit (40S), and the 28S and 5.8S rRNAs are two RNA components of the large ribosomal subunit (60S). The other RNA component of the large ribosomal subunit, the 5S rRNA, is transcribed by RNA polymerase III as a separate transcript.
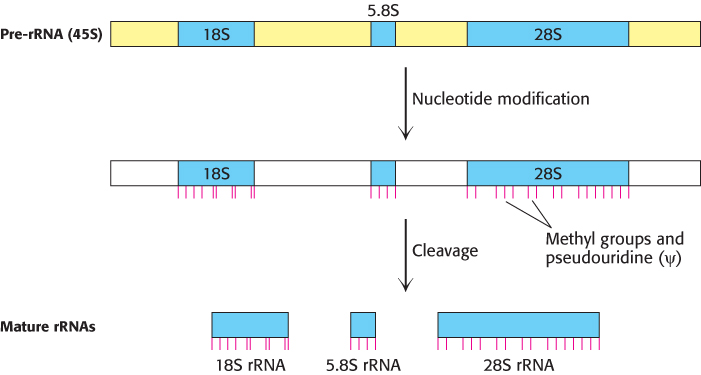
FIGURE 29.27Processing of eukaryotic pre-rRNA. The mammalian pre-rRNA transcript contains the RNA sequences destined to become the 18S, 5.8S, and 28S rRNAs of the small and large ribosomal subunits. First, nucleotides are modified: small nucleolar ribonucleoproteins methylate specific nucleoside groups and convert selected uridines into pseudouridines (indicated by red lines). Next, the pre-rRNA is cleaved and packaged to form mature ribosomes, in a highly regulated process in which more than 200 proteins take part.
The cleavage of the precursor into three separate rRNAs is actually the final step in its processing. First, the nucleotides of the pre-rRNA sequences destined for the ribosome undergo extensive modification, on both ribose and base components, directed by many small nucleolar ribonucleoproteins (snoRNPs), each of which consists of one snoRNA and several proteins. The pre-rRNA is assembled with ribosomal proteins, as guided by processing factors, in a large ribonucleoprotein. For instance, the small-subunit (SSU) processome is required for 18S rRNA synthesis and can be visualized in electron micrographs as a terminal knob at the 5′ ends of the nascent rRNAs (Fig. 29.28). Finally, rRNA cleavage (sometimes coupled with additional processing steps) releases the mature rRNAs assembled with ribosomal proteins as ribosomes. Like those of RNA polymerase I transcription itself, most of these processing steps take place in the cell nucleolus, a nuclear subcompartment.
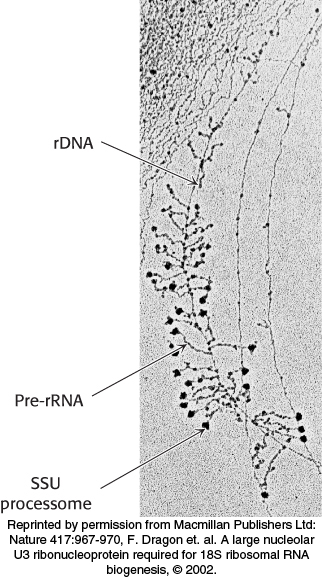
FIGURE 29.28Visualization of rRNA transcription and processing in eukaryotes. Transcription of rRNA and its assembly into precursor ribosomes can be visualized by electron microscopy. The structures resemble Christmas trees: the trunk is the rDNA and each branch is a pre-rRNA transcript. Transcription starts at the top of the tree, where the shortest transcripts can be seen, and progresses down the rDNA to the end of the gene. The terminal knobs visible at the end of some pre-rRNA transcripts likely correspond to the SSU processome, a large ribonucleoprotein required for processing the pre-rRNA.
[Reprinted by permission from Macmillan Publishers Ltd: Nature 417:967-970, F. Dragon et. al. A large nucleolar U3 ribonucleoprotein required for 18S ribosomal RNA biogenesis, © 2002.]
RNA polymerase III produces transfer RNA
Eukaryotic tRNA transcripts are among the most processed of all RNA polymerase III transcripts. Like those of prokaryotic tRNAs, the 5′ leader is cleaved by RNase P, the 3′ trailer is removed, and CCA is added by the CCA-adding enzyme (Figure 29.29). Eukaryotic tRNAs are also heavily modified on base and ribose moieties; these modifications are important for function. In contrast with prokaryotic tRNAs, many eukaryotic pre-tRNAs are also spliced by an endonuclease and a ligase to remove an intron.
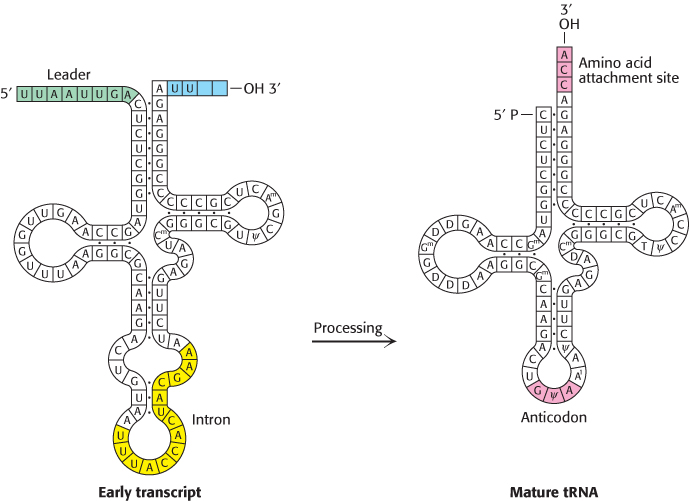
FIGURE 29.29Transfer RNA precursor processing. The conversion of a yeast tRNA precursor into a mature tRNA requires the removal of a 14-nucleotide intron (yellow), the cleavage of a 5′ leader (green), and the removal of UU and the attachment of CCA at the 3′ end (red). In addition, several bases are modified.
The product of RNA polymerase II, the pre-mRNA transcript, acquires a 5′ cap and a 3′ poly(A) tail
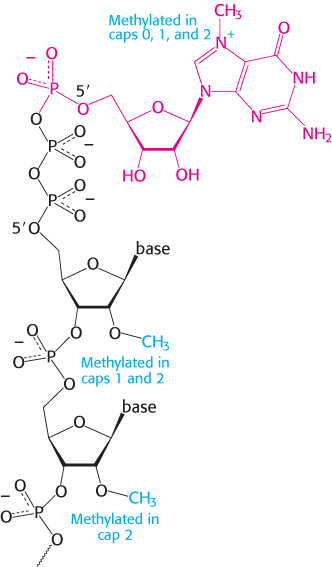
FIGURE 29.30Capping the 5′ end. Caps at the 5′ end of eukaryotic mRNA include 7-methylguanylate (red) attached by a triphosphate linkage to the ribose at the 5′ end. None of the riboses are methylated in cap 0, one is methylated in cap 1, and both are methylated in cap 2.
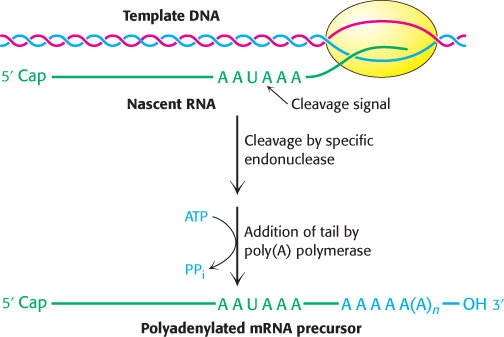
FIGURE 29.31Polyadenylation of a primary transcript. A specific endonuclease cleaves the RNA downstream of AAUAAA. Poly(A) polymerase then adds about 250 adenylate residues.
Perhaps the most extensively studied transcription product is the product of RNA polymerase II: most of this RNA will be processed to mRNA. The immediate product of RNA polymerase II is sometimes referred to as precursor-to-messenger RNA, or pre-mRNA. Most pre-mRNA molecules are spliced to remove the introns. Moreover, both the 5′ and the 3′ ends are modified, and both modifications are retained as the pre-mRNA is converted into mRNA.
As in prokaryotes, eukaryotic transcription usually begins with A or G. However, the 5′ triphosphate end of the nascent RNA chain is immediately modified. First, a phosphoryl group is released by hydrolysis. The diphosphate 5′ end then attacks the α-phosphorus atom of GTP to form a very unusual 5′–5′ triphosphate linkage. This distinctive terminus is called a cap (Figure 29.30). The N-7 nitrogen of the terminal guanine is then methylated by S-adenosylmethionine to form cap 0. The adjacent riboses may be methylated to form cap 1 or cap 2. Transfer RNA and ribosomal RNA molecules, in contrast with messenger RNAs and with small RNAs that participate in splicing, do not have caps. Caps contribute to the stability of mRNAs by protecting their 5′ ends from phosphatases and nucleases. In addition, caps enhance the translation of mRNA by eukaryotic protein-synthesizing systems.
As mentioned earlier, pre-mRNA is also modified at the 3′ end. Most eukaryotic mRNAs contain a polyadenylate, poly(A), tail at that end, added after transcription has ended. The DNA template does not encode this poly(A) tail. Indeed, the nucleotide preceding poly(A) is not the last nucleotide to be transcribed. Some primary transcripts contain hundreds of nucleotides beyond the 3′ end of the mature mRNA.
How is the 3′ end of the pre-mRNA given its final form? Eukaryotic primary transcripts are cleaved by a specific endonuclease that recognizes the sequence AAUAAA (Figure 29.31). Cleavage does not take place if this sequence or a segment of some 20 nucleotides on its 3′ side is deleted. The presence of internal AAUAAA sequences in some mature mRNAs indicates that AAUAAA is only part of the cleavage signal; its context also is important. After cleavage of the pre-RNA by the endonuclease, a poly(A) polymerase adds about 250 adenylate residues to the 3′ end of the transcript; ATP is the donor in this reaction.
The role of the poly(A) tail is still not firmly established despite much effort. However, evidence is accumulating that it enhances translation efficiency and the stability of mRNA. Blocking the synthesis of the poly(A) tail by exposure to 3′-deoxyadenosine (cordycepin) does not interfere with the synthesis of the primary transcript. Messenger RNA devoid of a poly(A) tail can be transported out of the nucleus. However, an mRNA molecule devoid of a poly(A) tail is usually a much less effective template for protein synthesis than is one with a poly(A) tail. Indeed, some mRNAs are stored in an unadenylated form and receive the poly(A) tail only when translation is imminent. The half-life of an mRNA molecule may be determined in part by the rate of degradation of its poly(A) tail.
Small regulatory RNAs are cleaved from larger precursors
Cleavage plays a role in the processing of small single-stranded RNAs (approximately 20–23 nucleotides) called microRNAs. MicroRNAs play key roles in gene regulation in eukaryotes, as we shall see in Chapter 32. They are generated from initial transcripts produced by RNA polymerase II and, in some cases, RNA polymerase III. These transcripts fold into hairpin structures that are cleaved by specific nucleases at various stages (Figure 29.32). The final single-stranded RNAs are bound by members of the Argonaute family of proteins where the RNAs help target the regulation of specific genes.
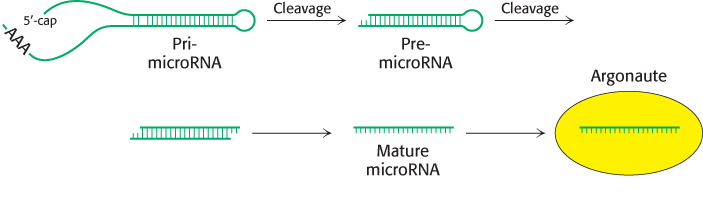
FIGURE 29.32Small regulatory RNA production. A pathway from a transcription product including a microRNA to the mature microRNA bound to an Argonaute protein. The initial transcription product, a pri-microRNA, is first cleaved to a small double-stranded RNA called a pre-microRNA. One of the strands of the pre-microRNA, the mature microRNA, is then bound by an Argonaute protein.
RNA editing changes the proteins encoded by mRNA
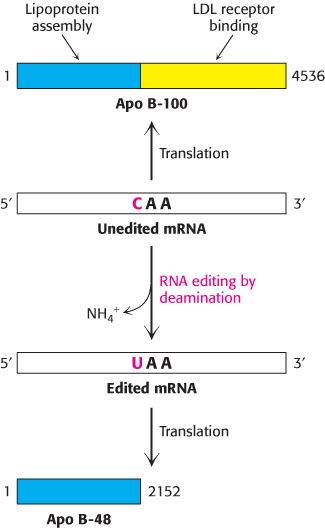
FIGURE 29.33RNA editing. Enzyme-catalyzed deamination of a specific cytidine residue in the mRNA for apolipoprotein B-100 changes a codon for glutamine (CAA) to a stop codon (UAA). Apolipoprotein B-48, a truncated version of the protein lacking the LDL receptor-binding domain, is generated by this posttranscriptional change in the mRNA sequence.
[Information from P. Hodges and J. Scott, Trends Biochem. Sci. 17:77, 1992.]
Remarkably, the amino acid sequence information encoded by some mRNAs is altered after transcription. RNA editing is the term for a change in the nucleotide sequence of RNA after transcription by processes other than RNA splicing. RNA editing is prominent in some systems already discussed. Apolipoprotein B (apo B) plays an important role in the transport of triacylglycerols and cholesterol by forming an amphipathic spherical shell around the lipids carried in lipoprotein particles (Section 26.3). Apo B exists in two forms, a 512-kDa apo B-100 and a 240-kDa apo B-48. The larger form, synthesized by the liver, participates in the transport of lipids synthesized in the cell. The smaller form, synthesized by the small intestine, carries dietary fat in the form of chylomicrons. Apo B-48 contains the 2152 N-terminal residues of the 4536-residue apo B-100. This truncated molecule can form lipoprotein particles but cannot bind to the low-density-lipoprotein receptor on cell surfaces. What is the relationship between these two forms of apo B? Experiments revealed that a totally unexpected mechanism for generating diversity is at work: the changing of the nucleotide sequence of mRNA after its synthesis (Figure 29.33). A specific cytidine residue of mRNA is deaminated to uridine, which changes the codon at residue 2153 from CAA (Gln) to UAA (stop). The deaminase that catalyzes this reaction is present in the small intestine, but not in the liver, and is expressed only at certain developmental stages.
RNA editing is not confined to apolipoprotein B. Glutamate opens cation-specific channels in the vertebrate central nervous system by binding to receptors in postsynaptic membranes. RNA editing changes a single glutamine codon (CAG) in the mRNA for the glutamate receptor to the codon for arginine (read as CGG). The substitution of Arg for Gln in the receptor prevents Ca2+, but not Na+, from flowing through the channel.
RNA editing is likely much more common than was formerly thought. The chemical reactivity of nucleotide bases, including the susceptibility to deamination that necessitates complex DNA-repair mechanisms, has been harnessed as an engine for generating molecular diversity at the RNA and, hence, protein levels.
In trypanosomes (parasitic protozoans), a different kind of RNA editing markedly changes several mitochondrial mRNAs. Nearly half the uridine residues in these mRNAs are inserted by RNA editing. A guide RNA molecule identifies the sequences to be modified, and a poly(U) tail on the guide donates uridine residues to the mRNAs undergoing editing. DNA sequences evidently do not always faithfully disclose the sequence of encoded proteins: functionally crucial changes to mRNA can take place.
Sequences at the ends of introns specify splice sites in mRNA precursors
Most genes in higher eukaryotes are composed of exons and introns (Section 4.7). The introns must be excised and the exons must be linked to form the final mRNA in a process called RNA splicing. This splicing must be exquisitely sensitive: splicing just one nucleotide upstream or downstream of the intended site would create a one-nucleotide shift, which would alter the reading frame on the 3′ side of the splice to give an entirely different amino acid sequence, likely including a premature stop codon. Thus, the correct splice site must be clearly marked. Does a particular sequence denote the splice site? The sequences of thousands of intron–exon junctions within RNA transcripts are known. In eukaryotes from yeast to mammals, these sequences have a common structural motif: the intron begins with GU and ends with AG. The consensus sequence at the 5′ splice in vertebrates is AGGUAAGU, where the GU is invariant (Figure 29.34). At the 3′ end of an intron, the consensus sequence is a stretch of 10 pyrimidines (U or C; termed the polypyrimidine tract), followed by any base and then by C, and ending with the invariant AG. Introns also have an important internal site located between 20 and 50 nucleotides upstream of the 3′ splice site; it is called the branch site for reasons that will be evident shortly. In yeast, the branch-site sequence is nearly always UACUAAC, whereas, in mammals, a variety of sequences are found.

FIGURE 29.34Splice sites. Consensus sequences for the 5′ splice site and the 3′ splice site are shown. Py stands for pyrimidine.
The 5′ and 3′ splice sites and the branch site are essential for determining where splicing takes place. Mutations in each of these three critical regions lead to aberrant splicing. Introns vary in length from 50 to 10,000 nucleotides, and so the splicing machinery may have to find the 3′ site several thousand nucleotides away. Specific sequences near the splice sites (in both the introns and the exons) play an important role in splicing regulation, particularly in designating splice sites when there are many alternatives. Researchers are currently attempting to determine the factors that contribute to splice-site selection for individual mRNAs. Despite our knowledge of splice-site sequences, predicting pre-mRNAs and their protein products from genomic DNA sequence information remains a challenge.
Splicing consists of two sequential transesterification reactions
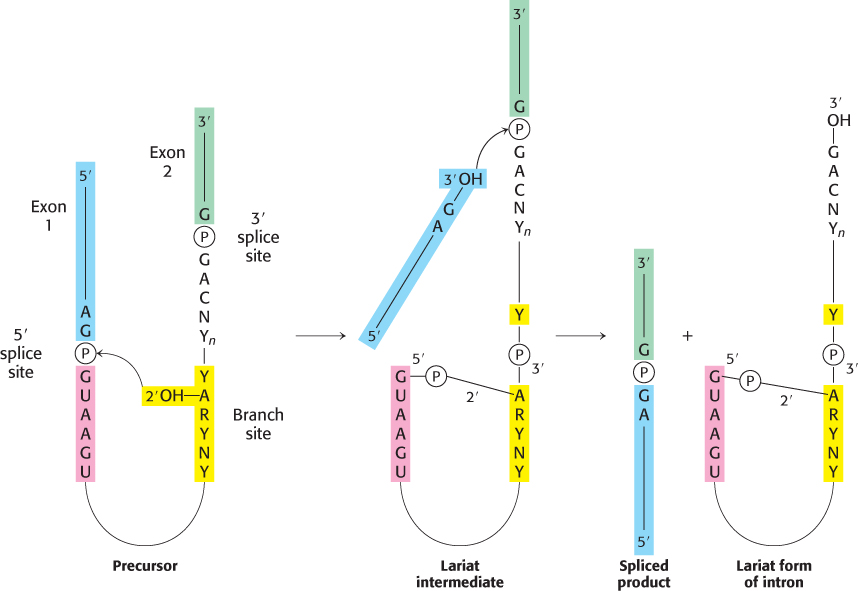
The splicing of nascent mRNA molecules is a complicated process. It requires the cooperation of several small RNAs and proteins that form a large complex called a spliceosome. However, the chemistry of the splicing process is simple. Splicing begins with the cleavage of the phosphodiester bond between the upstream exon (exon 1) and the 5′ end of the intron (Figure 29.35). The attacking group in this reaction is the 2′-OH group of an adenylate residue in the branch site. A 2′−5′ phosphodiester bond is formed between this A residue and the 5′ terminal phosphate of the intron. This reaction is a transesterification.
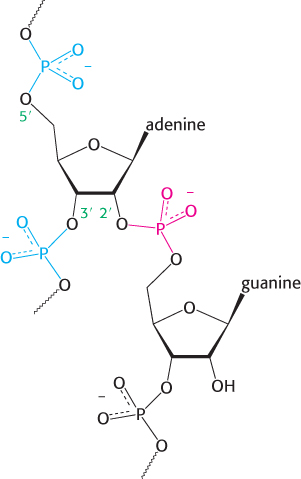
FIGURE 29.36Splicing branch point. The structure of the branch point in the lariat intermediate in which the adenylate residue is joined to three nucleotides by phosphodiester bonds. The new 2′-to-5′ linkage is shown in red, and the usual 3′-to-5′ linkages are shown in blue.
Note that this adenylate residue is also joined to two other nucleotides by normal 3′−5′ phosphodiester bonds (Figure 29.36). Hence a branch is generated at this site, and a lariat intermediate is formed.
The 3′ OH terminus of exon 1 then attacks the phosphodiester bond between the intron and exon 2. Exons 1 and 2 become joined, and the intron is released in lariat form. Again, this reaction is a transesterification. Splicing is thus accomplished by two transesterification reactions rather than by hydrolysis followed by ligation. The first reaction generates a free 3′
OH group at the 3′ end of exon 1, and the second reaction links this group to the 5′-phosphate of exon 2. The number of phosphodiester bonds stays the same during these steps, which is crucial because it allows the splicing reaction itself to proceed without an energy source such as ATP or GTP.
OH terminus of exon 1 then attacks the phosphodiester bond between the intron and exon 2. Exons 1 and 2 become joined, and the intron is released in lariat form. Again, this reaction is a transesterification. Splicing is thus accomplished by two transesterification reactions rather than by hydrolysis followed by ligation. The first reaction generates a free 3′
OH group at the 3′ end of exon 1, and the second reaction links this group to the 5′-phosphate of exon 2. The number of phosphodiester bonds stays the same during these steps, which is crucial because it allows the splicing reaction itself to proceed without an energy source such as ATP or GTP.
Small nuclear RNAs in spliceosomes catalyze the splicing of mRNA precursors
The nucleus contains many types of small RNA molecules with fewer than 300 nucleotides, referred to as snRNAs (small nuclear RNAs). A few of them—designated U1, U2, U4, U5, and U6—are essential for splicing mRNA precursors. The secondary structures of these RNAs are highly conserved in organisms ranging from yeast to human beings. These RNA molecules are associated with specific proteins to form complexes termed snRNPs (small nuclear ribonucleoprotein particles); investigators often speak of them as “snurps.” Spliceosomes are large (60S) dynamic assemblies composed of snRNPs, hundreds of other proteins called splicing factors, and the mRNA precursors being processed (Table 29.3).
TABLE 29.3 Small nuclear ribonucleoprotein particles (snRNPs) in the splicing of mRNA precursors
|
|
Size of snRNA (nucleotides) |
|
|
|
|
|
|
|
|
Binds the branch site and forms part of the catalytic center |
|
|
|
Binds the 5′ splice site and then the 3′ splice site |
|
|
|
Masks the catalytic activity of U6 |
|
|
|
|
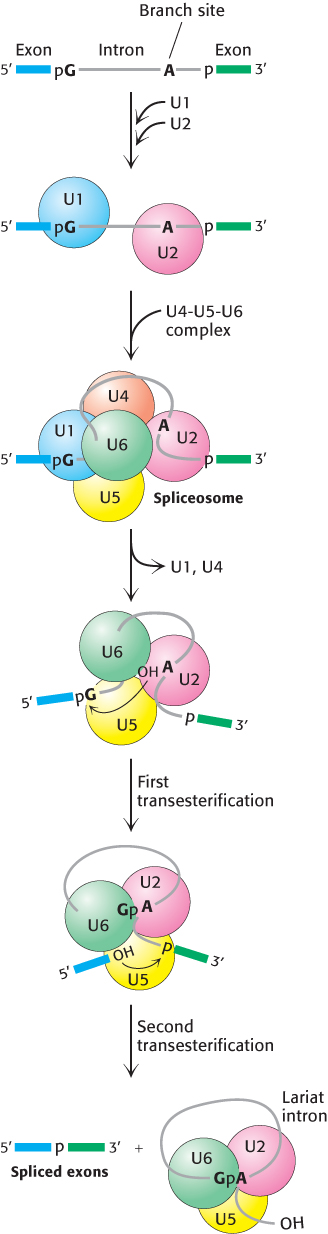
FIGURE 29.37Spliceosome assembly and action. U1 binds the 5′ splice site and U2 binds to the branch point. A preformed U4-U5-U6 complex then joins the assembly to form the complete spliceosome. The U6 snRNA re-folds and binds the 5′ splice site, displacing U1. Extensive interactions between U6 and U2 displace U4. Then, in the first transesterification step, the branch-site adenosine attacks the 5′ splice site, making a lariat intermediate. U5 holds the two exons in close proximity, and the second transesterification takes place, with the 5′ splice-site hydroxyl group attacking the 3′ splice site. These reactions result in the mature spliced mRNA and a lariat form of the intron bound by U2, U5, and U6.
[Information from T. Villa, J. A. Pleiss, and C. Guthrie, Cell 109:149–152, 2002.]
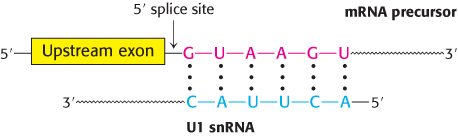
In mammalian cells, splicing begins with the recognition of the 5′ splice site by the U1 snRNP (Figure 29.37). U1 snRNA contains a highly conserved six-nucleotide sequence, not covered by protein in the snRNP, that base-pairs to the 5′ splice site of the pre-mRNA. This binding initiates spliceosome assembly on the pre-mRNA molecule.
U2 snRNP then binds the branch site in the intron by base-pairing between a highly conserved sequence in U2 snRNA and the pre-mRNA. U2 snRNP binding requires ATP hydrolysis. A preassembled U4-U5-U6 tri-snRNP joins this complex of U1, U2, and the mRNA precursor to form the spliceosome. This association also requires ATP hydrolysis.
A revealing view of the interplay of RNA molecules in this assembly came from examining the pattern of cross-links formed by psoralen, a reagent that joins neighboring pyrimidines in base-paired regions on treatment with light. These cross-links suggest that splicing takes place in the following way. First, U5 interacts with exon sequences in the 5′ splice site and subsequently with the 3′ exon. Next, U6 disengages from U4 and undergoes an intramolecular rearrangement that permits base-pairing with U2 as well as interaction with the 5′ end of the intron, displacing U1 from the spliceosome. The U2-U6 helix is indispensable for splicing, suggesting that U2 and U6 snRNAs probably form the catalytic center of the spliceosome (Figure 29.38). U4 serves as an inhibitor that masks U6 until the specific splice sites are aligned. These rearrangements result in the first transesterification reaction, cleaving the 5′ exon and generating the lariat intermediate.
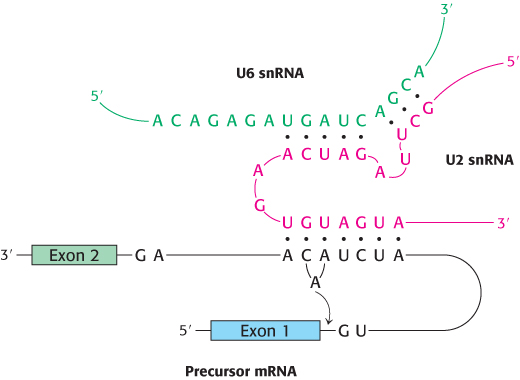
FIGURE 29.38Splicing catalytic center. The catalytic center of the spliceosome is formed by U2 snRNA (red) and U6 snRNA (green), which are base paired. U2 is also base paired to the branch site of the mRNA precursor.
[Information from H. D. Madhani and C. Guthrie, Cell 71:803–817, 1992.]
Further rearrangements of RNA in the spliceosome facilitate the second transesterification. In these rearrangements, U5 aligns the free 5′ exon with the 3′ exon such that the 3′-hydroxyl group of the 5′ exon is positioned to nucleophilically attack the 3′ splice site to generate the spliced product. U2, U5, and U6 bound to the excised lariat intron are released to complete the splicing reaction.
Many of the steps in the splicing process require ATP hydrolysis. How is the free energy associated with ATP hydrolysis used to power splicing? To achieve the well-ordered rearrangements necessary for splicing, ATP-powered RNA helicases must unwind RNA helices and allow alternative base-pairing arrangements to form. Thus, two features of the splicing process are noteworthy. First, RNA molecules play key roles in directing the alignment of splice sites and in carrying out catalysis. Second, ATP-powered helicases unwind RNA duplex intermediates that facilitate catalysis and induce the release of snRNPs from the mRNA.
Transcription and processing of mRNA are coupled
Although the transcription and processing of mRNAs have been described herein as separate events in gene expression, experimental evidence suggests that the two steps are coordinated by the carboxyl-terminal domain of RNA polymerase II. We have seen that the CTD consists of a unique repeated seven-amino-acid sequence, YSPTSPS. Either S2 or S5 or both may be phosphorylated in the various repeats. The phosphorylation state of the CTD is controlled by a number of kinases and phosphatases and leads the CTD to bind many of the proteins having roles in RNA transcription and processing. The CTD contributes to efficient transcription by recruiting these proteins to the pre-mRNA (Figure 29.39), including:
1. capping enzymes, which methylate the 5′ guanine on the pre-mRNA immediately after transcription begins;
2. components of the splicing machinery, which initiate the excision of each intron as it is synthesized; and
3. an endonuclease that cleaves the transcript at the poly(A) addition site, creating a free 3′-OH group that is the target for 3′ adenylation.
These events take place sequentially, directed by the phosphorylation state of the CTD.
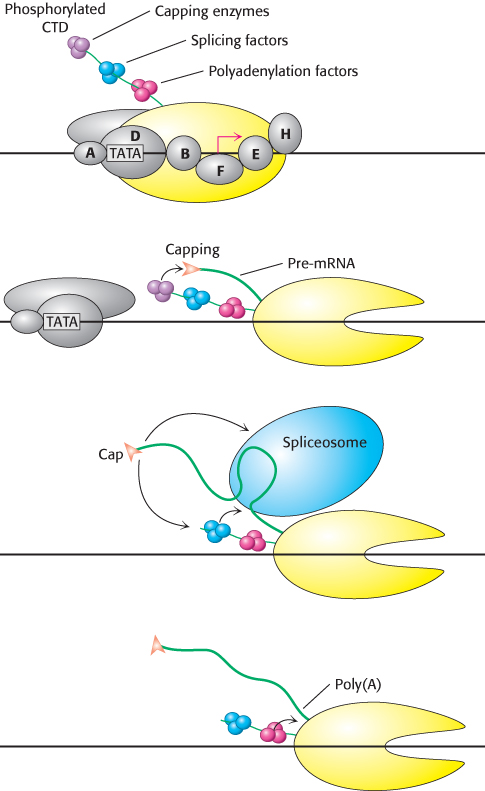
FIGURE 29.39The CTD: Coupling transcription to pre-mRNA processing. The transcription factor TFIIH phosphorylates the carboxyl-terminal domain (CTD) of RNA polymerase II, signaling the transition from transcription initiation to elongation. The phosphorylated CTD binds factors required for pre-mRNA capping, splicing, and polyadenylation. These proteins are brought in close proximity to their sites of action on the nascent pre-mRNA as it is transcribed during elongation.
[Information from P. A. Sharp, TIBS 30:279–281, 2005.]
Mutations that affect pre-mRNA splicing cause disease
 Mutations in either the pre-mRNA (cis-acting) or the splicing factors (trans-acting) can cause defective pre-mRNA splicing. Mutations in the pre-mRNA cause some forms of thalassemia, a group of hereditary anemias characterized by the defective synthesis of hemoglobin (Section 7.4). Cis-acting mutations that cause aberrant splicing can occur at the 5′ or 3′ splice sites in either of the two introns of the hemoglobin β chain or in its exons. The mutations usually result in an incorrectly spliced pre-mRNA that, because of a premature stop codon, cannot encode a full-length protein. The defective mRNA is normally degraded rather than translated. Mutations in the 5′ splice site may alter that site such that the splicing machinery cannot recognize it, forcing the machinery to find another 5′ splice site in the intron and introducing the potential for a premature stop codon. Mutations in the intron itself may create a new 5′ splice site; in this case, either one of the two splice sites may be recognized (Figure 29.40). Consequently, some normal protein can be made, and so the disease is less severe. Mutations affecting splicing have been estimated to cause at least 15% of all genetic diseases.
Mutations in either the pre-mRNA (cis-acting) or the splicing factors (trans-acting) can cause defective pre-mRNA splicing. Mutations in the pre-mRNA cause some forms of thalassemia, a group of hereditary anemias characterized by the defective synthesis of hemoglobin (Section 7.4). Cis-acting mutations that cause aberrant splicing can occur at the 5′ or 3′ splice sites in either of the two introns of the hemoglobin β chain or in its exons. The mutations usually result in an incorrectly spliced pre-mRNA that, because of a premature stop codon, cannot encode a full-length protein. The defective mRNA is normally degraded rather than translated. Mutations in the 5′ splice site may alter that site such that the splicing machinery cannot recognize it, forcing the machinery to find another 5′ splice site in the intron and introducing the potential for a premature stop codon. Mutations in the intron itself may create a new 5′ splice site; in this case, either one of the two splice sites may be recognized (Figure 29.40). Consequently, some normal protein can be made, and so the disease is less severe. Mutations affecting splicing have been estimated to cause at least 15% of all genetic diseases.
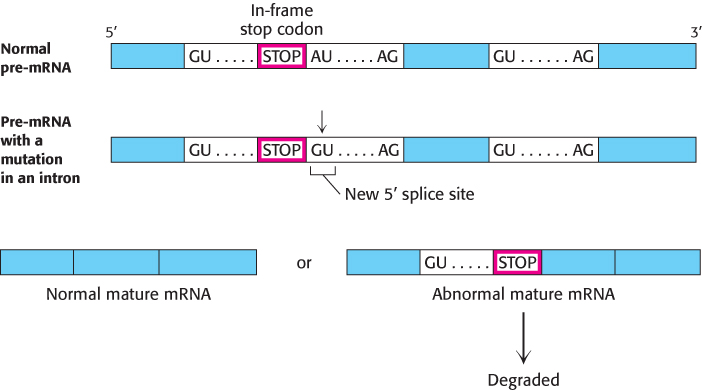
FIGURE 29.40A splicing mutation that causes thalassemia. An A-to-G mutation within the first intron of the gene for the human hemoglobin β chain creates a new 5′ splice site (GU). Both 5′ splice sites are recognized by the U1 snRNP; thus splicing may sometimes create a normal mature mRNA and an abnormal mature mRNA that contains intron sequences. The normal mature mRNA is translated into a hemoglobin β chain. Because it includes intron sequences, the abnormal mature mRNA now has a premature stop codon and is degraded.
Disease-causing mutations may also appear in splicing factors. Retinitis pigmentosa is a disease of acquired blindness, first described in 1857, with an incidence of 1/3500. About 5% of the autosomal dominant form of retinitis pigmentosa is likely due to mutations in the hPrp8 protein, a pre-mRNA splicing factor that is a component of the U4-U5-U6 tri-snRNP. How a mutation in a splicing factor that is present in all cells causes disease only in the retina is not clear; nevertheless, retinitis pigmentosa is a good example of how mutations that disrupt spliceosome function can cause disease.
Most human pre-mRNAs can be spliced in alternative ways to yield different proteins
Alternative splicing is a widespread mechanism for generating protein diversity. Different combinations of exons from the same gene may be spliced into a mature RNA, producing distinct forms of a protein for specific tissues, developmental stages, or signaling pathways. What controls which splicing sites are selected? The selection is determined by the binding of trans-acting splicing factors to cis-acting sequences in the pre-mRNA. Most alternative splicing leads to changes in the coding sequence, resulting in proteins with different functions. Alternative splicing provides a powerful mechanism for expanding the versatility of genomic sequences through combinatorial control. Consider a gene with five positions at which splicing can take place. With the assumption that these alternative splicing pathways can be regulated independently, a total of 25 = 32 different mRNAs can be generated.
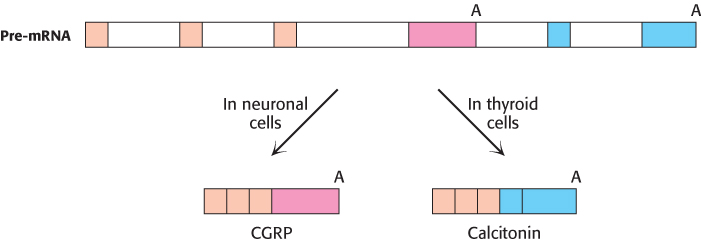
FIGURE 29.41An example of alternative splicing. In human beings, two very different hormones are produced from a single calcitonin/CGRP pre-mRNA. Alternative splicing produces the mature mRNA for either calcitonin or CGRP (calcitonin-gene-related protein), depending on the cell type in which the gene is expressed. Each alternative transcript incorporates one of two alternative polyadenylation signals (A) present in the pre-mRNA.
Sequencing of the human genome has revealed that most pre-mRNAs are alternatively spliced, leading to a much greater number of proteins than would be predicted from the number of genes. An example of alternative splicing leading to the expression of two different proteins, each in a different tissue, is provided by the gene encoding both calcitonin and calcitonin-gene-related peptide (CGRP; Figure 29.41). In the thyroid gland, the inclusion of exon 4 in one splicing pathway produces calcitonin, a peptide hormone that regulates calcium and phosphorus metabolism. In neuronal cells, the exclusion of exon 4 in another splicing pathway produces CGRP, a peptide hormone that acts as a vasodilator. A single pre-mRNA thus yields two very different peptide hormones, depending on cell type. In this case, only two proteins result from alternative splicing; however, in other cases, many more can be produced. An extreme example is the Drosophila pre-mRNA that encodes DSCAM, a neuronal protein affecting axon connectivity. Alternative splicing of this pre-mRNA has the potential to produce 38,016 different combinations of exons, a greater number than the total number of genes in the Drosophila genome. However, only a fraction of these potential mRNAs appear to be produced, owing to regulatory mechanisms that are not yet well understood. Several human diseases that can be attributed to defects in alternative splicing are listed in Table 29.4. Further understanding of alternative splicing and the mechanisms of splice-site selection will be crucial to understanding how the proteome represented by the human genome is expressed.
TABLE 29.4 Selected human diseases attributed to defects in alternative splicing
|
|
|
Acute intermittent porphyria |
Porphobilinogen deaminase |
Breast and ovarian cancer |
|
|
|
|
|
|
|
|
|
|
HGPRT deficiency (Lesch–Nyhan syndrome) |
Hypoxanthine-guanine phosphoribosyltransferase |
Leigh encephalomyelopathy |
Pyruvate dehydrogenase E1α |
Severe combined immunodeficiency |
|
|
|
|