3.1 CHEMICAL BUILDING BLOCKS OF NUCLEIC ACIDS AND PROTEINS
Nucleic Acids Are Long Chains of Nucleotides
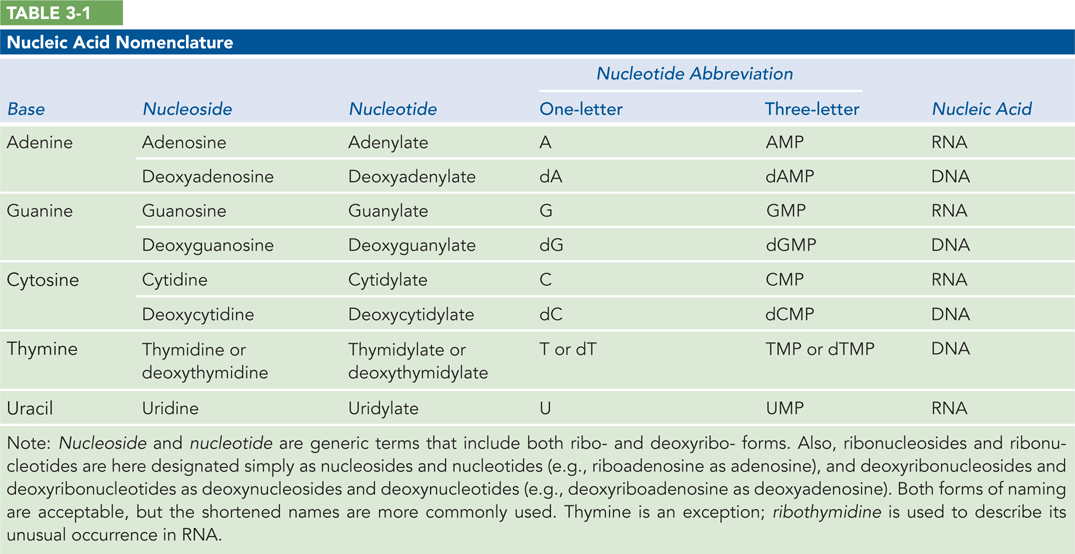
Deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) store and transmit genetic information, in part by coding for proteins. In addition, some RNA molecules function catalytically or structurally within larger, multimolecular complexes. Both DNA and RNA are composed of building blocks (monomers) called nucleotides, which are linked together by phosphodiester bonds to form long, unbranched chains. Nucleic acids can reach chain lengths of up to many millions of nucleotides and molecular masses of up to several billion daltons. A nucleotide molecule has three components: a nitrogenous base, a five-
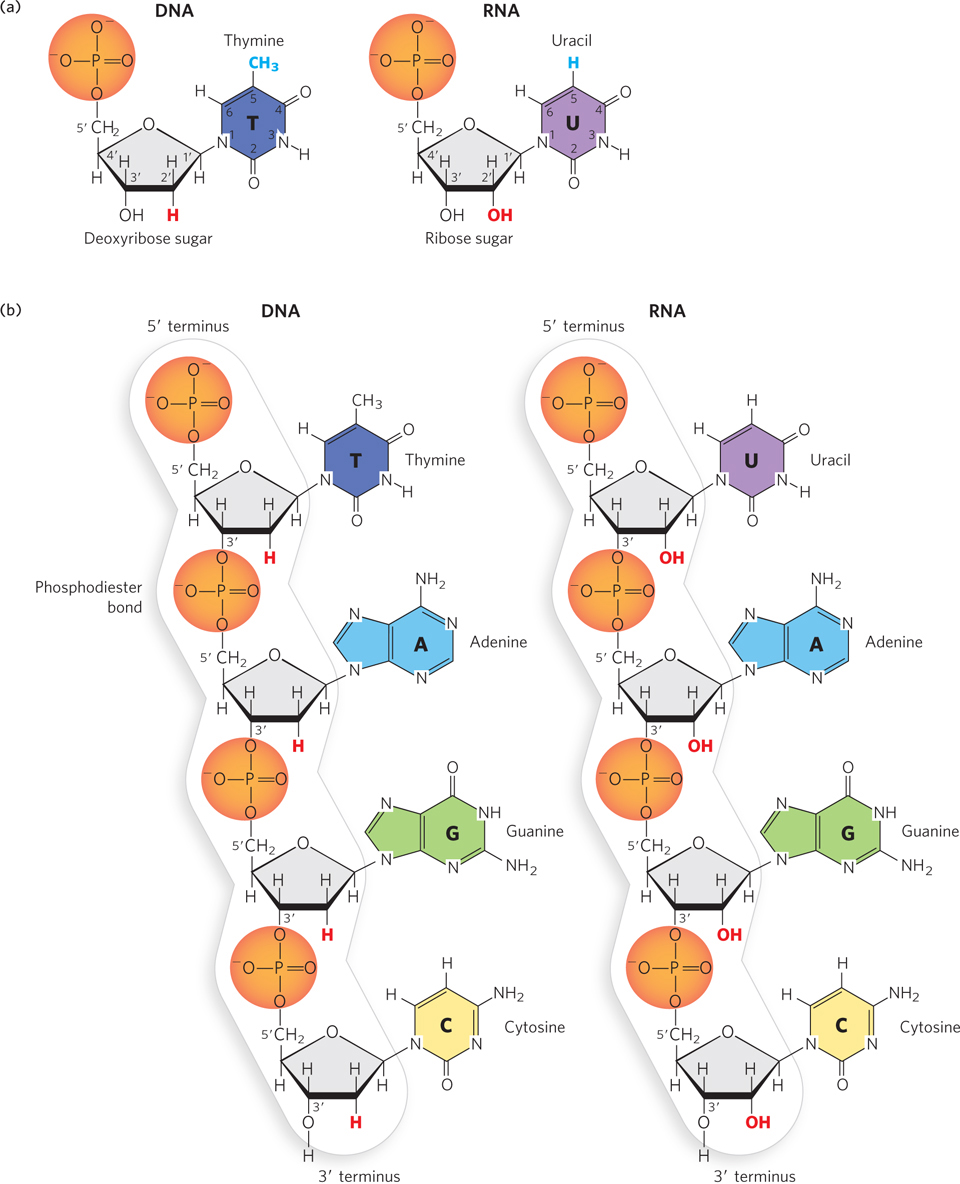
The nucleotides that make up DNA polymers are deoxyribonucleotides (Figure 3-1a, left), named for the type of pentose sugar found in DNA: deoxyribose. Whereas the phosphate group and the type of pentose remain constant, each deoxyribonucleotide contains one of four different nitrogenous bases: thymine (T), adenine (A), guanine (G), or cytosine (C) (Figure 3-1b, left). The type of base establishes the identity of each individual deoxyribonucleotide. Thus, the information in DNA is written in a four-
Chemically, RNA is very similar to DNA. Like DNA, it is a long, unbranched polymer of nucleotides. And like DNA nucleotides, all RNA nucleotides contain a pentose and a phosphate group, and one of four different nitrogenous bases. Two small differences in their chemical components, however, give rise to important distinctions between the structures and functions of RNA and DNA. The first is the type of pentose present. RNA nucleotides contain ribose and thus are named ribonucleotides (see Figure 3-1a, right). Ribose has one more hydroxyl (–OH) group on the sugar ring than does deoxyribose, which defines the RNA polynucleotide as ribonucleic acid rather than deoxyribonucleic acid. The second distinction is the assortment of nitrogenous bases found in RNA. Ribonucleotides contain three of the same bases found in DNA—
63
64
KEY CONVENTION
DNA and RNA are defined by the type of sugar in the polynucleotide backbone (deoxyribose or ribose), not by the presence of thymine or uracil.
Even with just four types of nucleotides each, the number of possible DNA and RNA sequences (4n, where n is the number of nucleotides in the sequence) is enormous for even the shortest molecules. Thus, an almost infinite number of distinct genetic messages can exist.
Proteins Are Long Polymers of Amino Acids
Proteins, like nucleic acids, are unbranched polymers. The building blocks of protein chains are amino acids (Figure 3-2a). When amino acids are joined together by a peptide bond between the amino group of one amino acid and the carboxyl group of another, a peptide is formed. Longer chains of amino acids are called polypeptides (Figure 3-2b). Polypeptides have a characteristic directionality defined by the free amino group of the amino acid at one end of the polymer (the amino terminus, or N-
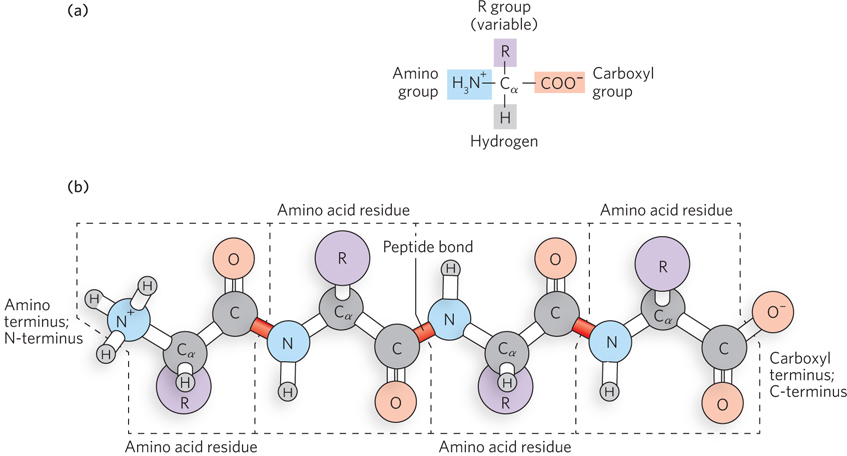
All 20 common amino acids have a similar structure: a central carbon atom, the alpha carbon atom (α carbon, or Cα), bonded to four different chemical groups. For this reason, they are called α-amino acids. The α-amino acids have a carboxyl (–COOH) group, an amino (–NH2) group, and a hydrogen atom, all bonded to the α carbon. Each amino acid also has a unique side chain, or R group, bonded to the α carbon atom (see Figure 3-2). The R groups vary in structure, size, electrical charge, and hydrophobicity. The diverse chemical properties of R groups are what give proteins the ability to form many different three-
65
Chemical Composition Helps Determine Nucleic Acid and Protein Structure
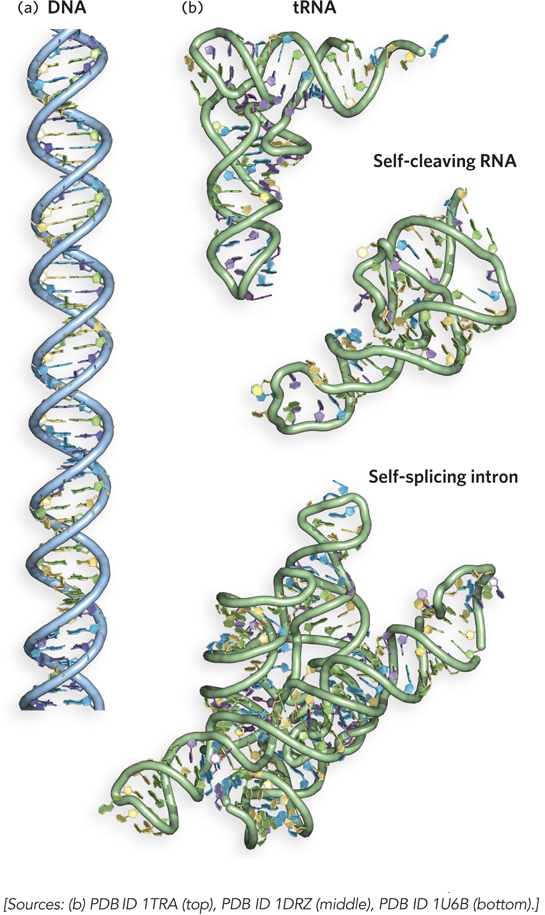
The fact that some of the crucial requirements for life are met by polymeric molecules makes good sense, from a biosynthetic standpoint. As we have noted, a huge variety of nucleic acids and proteins can be produced by varying the sequence of nucleotide or amino acid monomers in the chains. DNA molecules are typically many millions of nucleotides long, but they form relatively uniform overall structures in which the nucleotide bases in two strands pair up along their length to produce a double helix (Figure 3-3a). RNA molecules, except for those that store the genetic information of viruses, are much shorter and more structurally diverse than DNA. A single strand of RNA can fold back on itself to form short helices that come together in a three-
Of all biological polymers, proteins have the greatest variety of three-
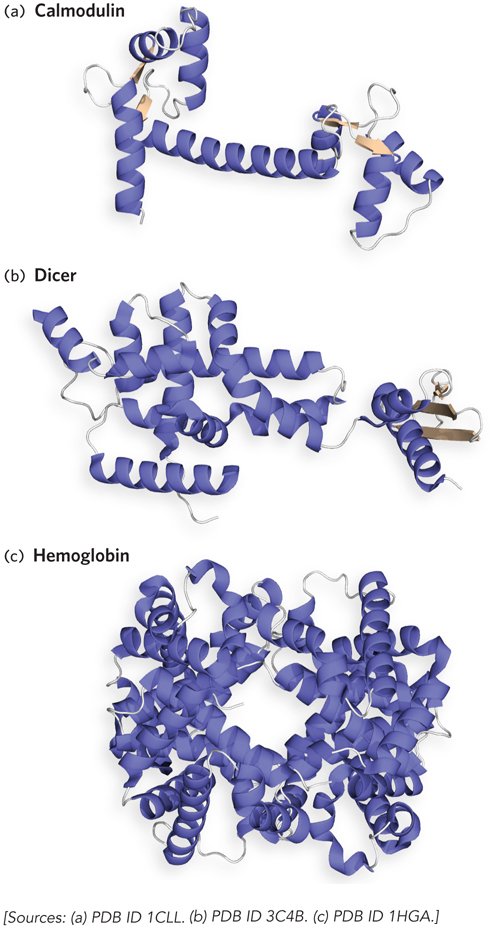
Chemical Composition Can Be Altered by Postsynthetic Changes
Chemical modifications of nucleotides and amino acids often occur after a DNA, RNA, or protein molecule has been synthesized. Sometimes these modifications are required for the molecule to attain its biologically active structure or to bind other molecules.
The primary modification of DNA nucleotides is the addition of methyl (–CH3) groups to the C, A, and G bases (Figure 3-5a). DNA base methylation is critical for accurate DNA replication and, in bacteria, for the protection of DNA from degradative enzymes; in human and other eukaryotic cells, it is essential for activating and silencing gene expression. RNA molecules can be modified in a greater variety of ways, including the addition of methyl groups to the nucleotide bases or to the 2′-hydroxyl group of the ribose and the substitution of less-
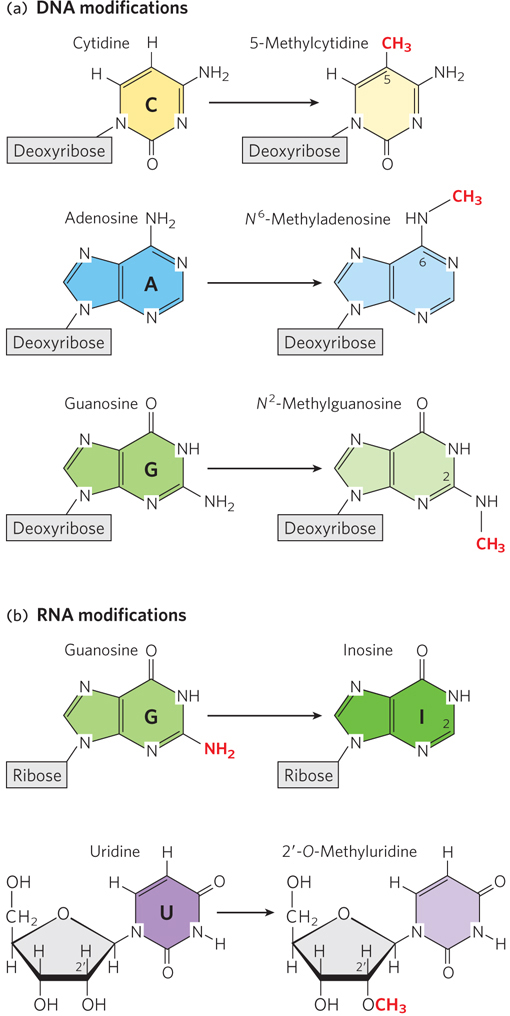
66
Proteins are often modified by the addition of chemical groups to specific amino acid residues within a polypeptide chain. More than 300 types of amino acid modifications are known to occur in proteins; a few are particularly common. For example, addition of phosphate groups to hydroxyl groups in the side chains of serine, tyrosine, and threonine can dramatically change a protein’s shape and function. The phosphorylation and dephosphorylation of proteins is an important mechanism by which signals are transmitted within and among cells. Proteins are sometimes modified by the addition of sugars (glycosylation) or methyl groups, with functional consequences (Figure 3-6). For example, glycosylated proteins provide chemical signatures on the surfaces of cells that help distinguish “self” from “nonself.” Another common protein modification is the addition of acetyl groups to lysine side chains. Lysine acetylation—
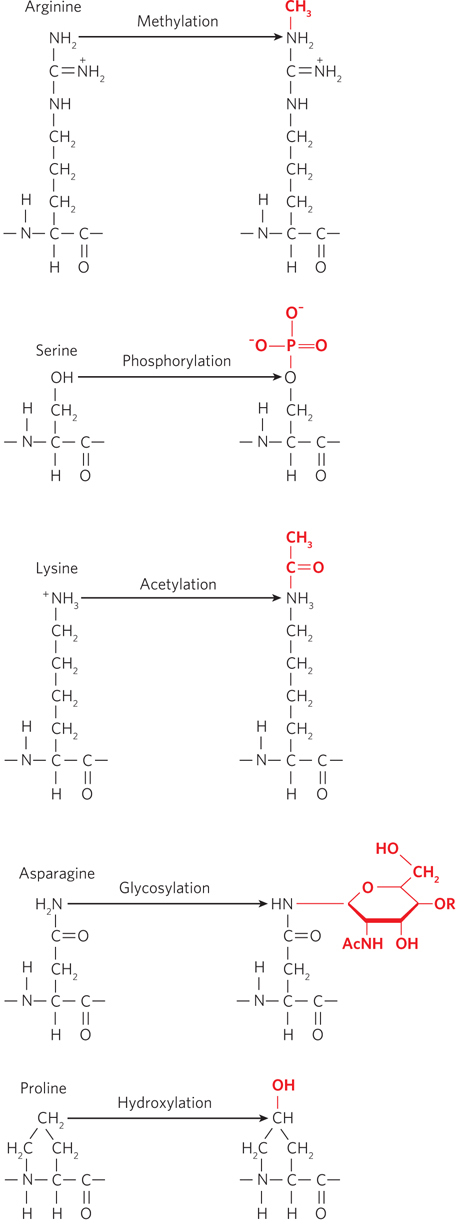
67
68
SECTION 3.1 SUMMARY
Polymeric molecules play crucial roles in all organisms.
The nucleic acids, DNA and RNA, are polymers of nucleotides. Each nucleotide has three components: a deoxyribose (in DNA) or ribose (in RNA) pentose sugar, a phosphate group, and a nitrogenous base. The four bases in DNA are adenine, guanine, cytosine, and thymine; the four bases in RNA are adenine, guanine, cytosine, and uracil.
DNA and RNA are chemically similar, with two small differences that have significant functional consequences, including different helical geometries, three-
dimensional shapes, and protein- binding abilities. The ribose of RNA has a hydroxyl (–OH) group on the 2′carbon of the sugar ring, but the deoxyribose of DNA does not; and, instead of thymine, RNA nucleotides contain uracil, an unmethylated form of the thymine base. The nucleotides of DNA or RNA are linked into chains by phosphodiester bonds. Proteins are polymers of amino acids. Twenty amino acid building blocks are commonly found in proteins, each consisting of a central α-carbon atom bonded to four different groups: a carboxyl group, an amino group, an R group, and a hydrogen atom. The R groups, or side chains, have chemical properties that contribute to the functional and structural diversity of proteins. The amino acid residues in proteins are linked by peptide bonds.
DNA molecules form a two-
stranded double helix, whereas RNA molecules are mainly found as single polynucleotide strands that fold back on themselves to create various three- dimensional shapes. Protein structures are even more diverse, due in part to the different chemical properties of the amino acid side chains. Postsynthetic chemical modifications of DNA, RNA, and proteins can dramatically affect the structure and biological activity of these macromolecules. In DNA, methylation of bases A, C, and G is common and leads to changes in gene expression. In RNA, modifications are more varied and include methylation of bases and/or ribose and other, more substantial alterations of bases. Protein modifications include the addition of phosphate, sugar, methyl, acetyl, and hydroxyl groups to specific amino acid side chains.