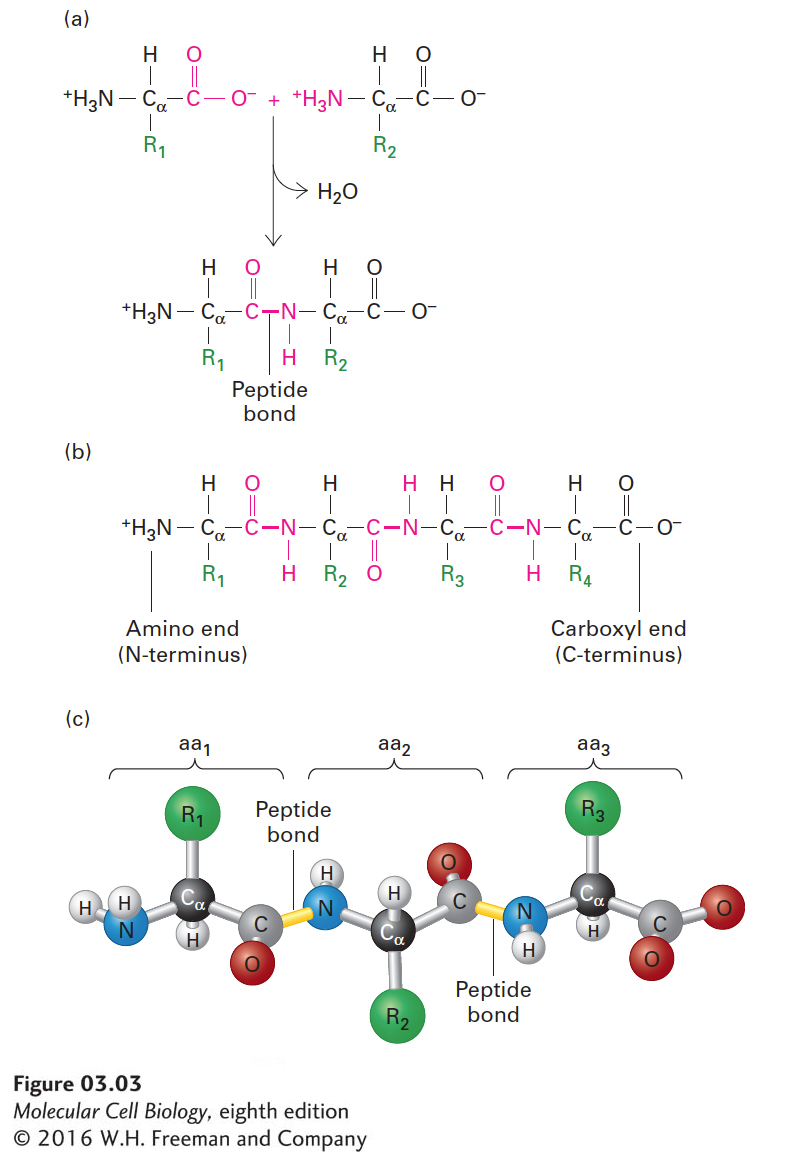
The Primary Structure of a Protein Is Its Linear Arrangement of Amino Acids
As discussed in Chapter 2, proteins are polymers constructed out of 20 different types of amino acids. Individual amino acids are linked together in linear, unbranched chains by covalent amide bonds, called peptide bonds. Peptide bond formation between the amino group of one amino acid and the carboxyl group of another results in the net release of a water molecule and thus is a form of dehydration reaction (Figure 3-3a). The repeated amide N, α carbon (Cα), carbonyl C, and oxygen atoms of each amino acid residue form the backbone of a protein molecule from which the various side-chain groups project (Figure 3-3b, c). As a consequence of the peptide linkage, the backbone exhibits directionality, usually referred to as an N-to-C orientation, because all the amino groups are located on the same side of the Cα atoms. Thus one end of a protein has a free (unlinked) amino group (the N-terminus), and the other end has a free carboxyl group (the C-terminus). The sequence of a protein chain is conventionally written with its N-terminal amino acid on the left and its C-terminal amino acid on the right, and the amino acids are numbered sequentially starting from the N-terminus.
FIGURE 3-3Structure of a polypeptide. (a) Individual amino acids are linked together by peptide bonds, which form via reactions that result in a loss of water (dehydration). R1, R2, etc., represent the side chains (“R groups”) of amino acids. (b) Linear polymers of peptide-bond-linked amino acids are called polypeptides, which have a free amino end (N-terminus) and a free carboxyl end (C-terminus). (c) A ball-and-stick model shows peptide bonds (yellow) linking the amino nitrogen atom (blue) of one amino acid (aa) with the carbonyl carbon atom (gray) of an adjacent one in the chain. The R groups (green) extend from the α carbon atoms (black) of the amino acids. These side chains largely determine the distinct properties of individual proteins.
Page 70
The primary structure of a protein is simply the linear covalent arrangement, or sequence, of the amino acid residues that compose it. The first primary structure of a protein determined was that of insulin in the early 1950s. Today the number of known sequences exceeds 10 million and is growing daily. Many terms are used to denote the chains formed by the polymerization of amino acids. A short chain of amino acids linked by peptide bonds and having a defined sequence is called an oligopeptide, or simply a peptide; longer chains are referred to as polypeptides. Peptides generally contain fewer than 20–30 amino acid residues, whereas polypeptides are often 200–500 residues long. The longest protein described to date is the muscle protein titin, some forms of which can be more than 34,000 residues long. We generally reserve the term protein for a polypeptide (or complex of polypeptides) that has a well-defined three-dimensional structure.
The size of a protein or a polypeptide is expressed either as its mass in daltons (a dalton is 1 atomic mass unit) or as its molecular weight (MW), which is a dimensionless number equal to the mass in daltons. For example, a 10,000-MW protein has a mass of 10,000 daltons (Da), or 10 kilodaltons (kDa). Later in this chapter, we will consider different methods for measuring the sizes and other physical characteristics of proteins. The precise molecular weight of a protein that has not been covalently modified is readily determined by summing up the weights of all of its constituent amino acids as determined from its amino acid sequence. The proteins encoded by the yeast genome, for example, have an average molecular weight of 52,728 and contain, on average, 466 amino acid residues. The average molecular weight of amino acids in proteins is 113, taking into account their average relative abundances. This value can be used to estimate the number of residues in a protein of unknown sequence if you know its molecular weight or, conversely, to estimate from the number of residues in a protein its likely molecular weight. Covalent modification of one or more amino acids in a protein—for example, by phosphorylation or glycosylation (see Chapters 2 and 13)—alters the mass of those residues and thus the mass of the protein in which they reside.
How many proteins are there in a typical eukaryotic (nucleated) cell? Let’s do a simple calculation for one such cell, a hepatocyte (a major type of cell in the mammalian liver). This type of cell, roughly a cube 15 µm (0.0015 cm) on a side, has a volume of 3.4 × 10−9 cm3 (or milliliters, ml). Assuming a cell density of 1.03 g/ml, the cell would weigh 3.5 × 10−9 g. Since protein accounts for approximately 20 percent of a cell’s weight, the total weight of cellular protein is 7 × 10−10 g. Assuming that an average protein has a molecular weight of 52,728 g/mol, we can calculate the total number of protein molecules per hepatocyte as about 7.9 × 109 from the total protein weight and Avogadro’s number, the number of molecules per mole of any chemical compound (6.02 × 1023). To carry this calculation one step further, consider that a hepatocyte contains about 10,000 different proteins; thus each cell, on average, would contain close to a million molecules of each type of protein. In fact, the abundances of different proteins vary widely, from the quite rare insulin-binding receptor protein (20,000 molecules per cell) to the structural protein actin (5 × 108 molecules per cell). Every cell closely regulates the abundance of each protein such that each is present in the appropriate quantity for its cellular functions at any given time. We will learn more about the mechanisms used by cells to regulate protein levels later in this chapter and in Chapters 9 and 10.