12.1 One-Way Analysis of Variance (ANOVA)
 This page includes Video Technology Manuals
This page includes Video Technology Manuals This page includes Statistical Videos
This page includes Statistical VideosOBJECTIVES By the end of this section, I will be able to …
- Explain how analysis of variance works.
- Perform one-way analysis of variance.
1 How Analysis of Variance (ANOVA) Works

Analysis of variance (ANOVA) is a hypothesis test for determining whether three or more means of different populations are equal. ANOVA works by comparing the variability between the samples to the variability within the samples.
Suppose we are interested in determining whether significant differences exist in grade point averages (GPAs) among residents of three dormitories, A, B, and C. Table 1 displays three random samples of GPAs of 10 residents from each dormitory.
| A | 0.60 | 3.82 | 4.00 | 2.22 | 1.46 | 2.91 | 2.20 | 1.60 | 0.89 | 2.30 |
| B | 2.12 | 2.00 | 1.03 | 3.47 | 3.70 | 1.72 | 3.15 | 3.93 | 1.26 | 2.62 |
| C | 3.65 | 1.57 | 3.36 | 1.17 | 2.55 | 3.12 | 3.60 | 4.00 | 2.85 | 2.13 |
The sample mean GPA for Dormitory A is
ˉxA=0.60+3.82+4.00+2.22+1.46+2.91+2.20+1.60+0.89+2.3010=2.2
Similarly, we can find the sample mean GPAs for the other dormitories: ˉxB=2.5 and ˉxC=2.8. We note that the sample means are not equal. The question is: Are the population means equal? Let μA, μB, and μC represent the population mean GPAs for Dormitories A, B, and C, respectively. We are interested in the following hypotheses, where μi represents the population mean GPA for dormitory i:
H0:μA=μB=μCversusHa:not all the population means are equal
Sufficient differences in the sample means would represent evidence that the population means were not equal. The question is: What represents “sufficiently” different? We need something to compare against, such as the spread of each sample. One measure of spread or variability is the range:
range=max−min
We have
range(Dorm A)=4.00−0.60=3.40range(Dorm B)=3.93−1.03=2.90range(Dorm C)=4.00−1.17=2.83
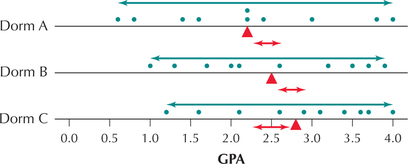
These ranges are rather large spreads, and there is a considerable amount of overlap among the different dormitory GPAs, as shown in Figure 1.
Figure 1 shows the difference among the means for the three dorm GPAs compared with the spread of each dorm's GPAs, as measured by the range. The red triangles represent the sample means, ˉxA=2.2, ˉxB=2.5, and ˉxC=2.8. The spread of the sample means (shown by the red arrows) is much less than the spreads of the individual dorm GPAs (shown by the green arrows). Thus, the sample means ˉxA=2.2, ˉxB=2.5, and ˉxC=2.8 are not sufficiently different when compared against the spread of the GPAs. This graph would therefore not provide evidence to reject the null hypothesis that the population mean GPAs are all equal.
Now we make a similar comparison for the GPAs for Dormitories D, E, and F in Table 2.
| D | 2.16 | 2.23 | 2.09 | 2.17 | 2.25 | 2.19 | 2.24 | 2.28 | 2.25 | 2.14 |
| E | 2.45 | 2.34 | 2.58 | 2.49 | 2.60 | 2.42 | 2.55 | 2.62 | 2.45 | 2.50 |
| F | 2.80 | 2.75 | 2.93 | 2.68 | 2.88 | 2.75 | 2.87 | 2.81 | 2.73 | 2.80 |
The sample mean GPAs for Dormitories D, E, and F are the same as those for Dormitories A, B, and C, respectively: ˉxD=2.2, ˉxE=2.5, and ˉxF=2.8. Again, we are interested in whether the population means are equal.
H0:μD=μE=μFversusHa:not all the population means are equal
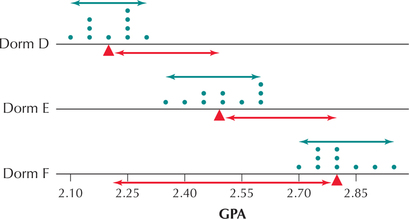
Consider the comparison dotplot in Figure 2. There now seems to be better evidence for concluding that the three population means are not all equal. There is no overlap among the three samples because the spread within each dormitory is much smaller than for Dormitories A, B, and C.
range (Dorm D)=2.28−2.09=0.19range (Dorm E)=2.62−2.34=0.28range (Dorm F)=2.93−2.68=0.25
Figure 2 shows the difference among the means for the three dorm GPAs compared with the range of each dorm's GPAs. The red triangles represent the sample means, ˉxD=2.2, ˉxE=2.5, and ˉxF=2.8. The spread of the sample means (red arrows) is much greater than the spreads of the individual dorm GPAs (green arrows). Thus, the sample means ˉxD=2.2, ˉxE=2.5, and ˉxF=2.8 are sufficiently different when compared against the range of the GPAs. This graph would, therefore, provide some evidence to reject the null hypothesis that the population mean GPAs are all equal.
Note that we arrived at opposite conclusions for the two sets of dormitories, even though the sample means of the first group are identical to the sample means of the second group. Here is the key difference:
- The within-sample spreads of Dormitories A, B, and C are large. Compared to these large spreads, the difference in sample means did not seem large.
- The within-sample spreads of Dormitories D, E, and F are small. Compared to these small spreads, the difference in sample means did seem large.
These are the types of comparisons that the ANOVA method makes.
Instead of using the range as the measure of spread, analysis of variance uses the standard deviation of the individual samples. Recall that samples with larger spread have larger standard deviations, just as they have larger ranges.
Developing Your Statistical Sense
How Does Analysis of Variance Work?
The key to how analysis of variance works is the following comparison. Compare
- the variability in the sample means—that is, how large the differences are between the sample means (indicated by the lengths of the red arrows in Figures 1 and 2)—with
- the variability within each sample—that is, the within-sample spreads (indicated by the lengths of the green arrows in Figures 1 and 2).
When (a) is much larger than (b), this is evidence that the population means are not all equal and that we should reject the null hypothesis. Thus, our analysis depends on measuring variability—and hence the term analysis of variance.
Just as for hypothesis-testing procedures from previous chapters, analysis of variance can be performed only if certain requirements are met.
Requirements for Performing Analysis of Variance
- Each of the k populations is normally distributed.
- The variances (σ2) of the populations are all equal.
- The samples are independently drawn.
Note: In analysis of variance, the null hypothesis always states that all the population means are equal and the alternative hypothesis always states that not all the population means are equal. Note that Ha is not stating that the population means are all different. For Ha to be true, it is sufficient for a single population mean to be different, even though all the other population means may be equal.
Our hypotheses for testing for the equality of the population mean GPA for Dormitories A, B, and C are
H0:μA=μB=μCversusHa:not all the population means are equal
Let us stop for a moment to consider what these requirements and the hypotheses mean.
- If H0 is true, then all three dormitories would have the same population mean GPA: μA=μB=μC=μ, where we denote the hypothesized common mean as μ.
- Requirement 1 states that each population is normally distributed.
- Requirement 2 states that all the population variances are equal. Let's call this common variance σ2.
Putting all this together, H0 assumes that the observations from each population come from the same normal distribution, with mean μ and variance σ2.
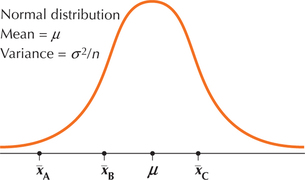
Suppose we then take samples of size n from each group. Fact 3 in Chapter 7 states that the sampling distribution of ˉx for a sample of size n taken from a normal population with mean μ and standard deviation σ (that is, variance σ2) is also normal, with mean μ and standard deviation σ/√n (that is, variance σ2/√n), as shown in Figure 3. Each dormitory's GPA is assumed (under H0) to come from the same sampling distribution, so we would expect the sample means to be fairly close together.
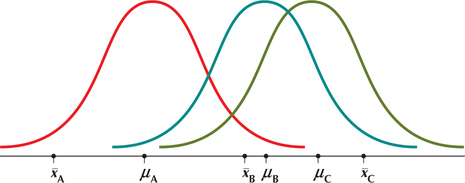
On the other hand, if H0 is not true, then not all the population means are equal (Figure 4). In this case, there is no sampling distribution common to all sample means, so we would not expect the sample means to be close together. Note in Figure 4 that each distribution nevertheless has the same shape (normal) and spread (that is, variance) because of the requirements.
Note: Normal probability plots were introduced in Chapter 7.
Procedure for Verifying the Requirements for Analysis of Variance
- Step 1 Normality. Check that the data from each group are normally distributed, using normality probability plots.
- Step 2 Equal Variances. Compute the sample standard deviation for each group to verify that the largest standard deviation is not larger than twice the smallest standard deviation.
- Step 3 Independence. Verify that the samples drawn from each group are independently drawn.
EXAMPLE 1 Verify the requirements for performing an analysis of variance
dormitory
Verify the requirements for performing an analysis of variance using the hypotheses
H0:μA=μB=μCversusHa:not all the population means are equal
where μi represents the population mean GPA for Dormitory i, using data from Table 1.
Solution
Step 1 Normality. To verify that each of the k=3 populations is normally distributed, we examine normal probability plots of each sample, shown in Figure 5. Each plot indicates acceptable normality.
FIGURE 5 Normal probability plots verify normality requirement.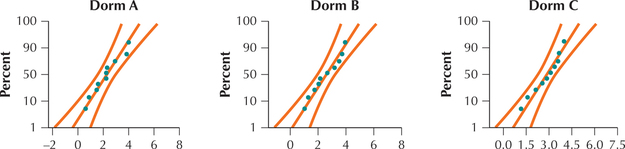 Page 670
Page 670Step 2 Equal Variances. To find the standard deviation for Dorm A, we first find
∑(x−ˉx)2=(0.60−2.2)2+(3.82−2.2)2+(4.00−2.2)2+(2.22−2.2)2 +(1.46−2.2)2+(2.91−2.2)2+(2.20−2.2)2+(1.60−2.2)2 +(0.89−2.2)2+(2.30−2.2)2 =11.5626
Then
sA=√∑(x−ˉx)2n−1=√11.562610−1≈1.133460777
We similarly find sB≈1.030857248 and sC≈0.9370284. The largest, sA≈1.133460777, is not larger than twice the smallest, sC≈0.9370284. Thus, the equal variance require-ment is satisfied.
- Step 3 Independence. Because the students are randomly sampled from each dormitory, with the selection of students in one dormitory not affecting the selection of students sampled from the other dormitories, the independence assumption is also validated.
Note: We retain many decimal places when calculating sA, sB, and sC because these values are used to calculate other quantities later on.
NOW YOU CAN DO
Exercises 7–10.
Note: This form for ˉˉx is a weighted mean with the weights being the sample sizes.
Assuming that H0 is true, we estimate the common population mean μ using the overall sample mean, ˉˉx:
ˉˉx=(n1ˉx1+n2ˉx2+⋯+nkˉxk)nt
where there are k samples and nt is the “total sample size” (sum of the k sample sizes). The overall sample mean ˉˉx is simply the mean of all the observations from all the samples. For the special case when all the sample sizes are equal, the overall sample mean ˉˉx is simply the mean of the k sample means,
ˉˉx=(ˉx1+ˉx2+⋯+ˉxk)k
EXAMPLE 2 Calculating the overall sample mean ˉˉx
For the sample GPA data given in Table 1 for Dorms A, B, and C, calculate the overall sample mean, ˉˉx.
Solution
We have k=3 dormitories, with sample mean GPAs ˉxA=2.2, ˉxB=2.5, ˉxC=2.8. Also, nA=nB=nC=10, and nt=10+10+10=30. Thus,
ˉˉx=10(2.2)+10(2.5)+10(2.8)30=2.5
All the sample sizes are equal, so we can also calculate ˉˉx as follows:
ˉx=(2.2+2.5+2.8)30=2.5
NOW YOU CAN DO
Exercises 11–14.
What Does This Number Mean?
ˉˉx=2.5 is the mean GPA for all 30 students from all three samples. We can use ˉˉx as our estimate of the common population mean μ assumed in H0.
Recall that analysis of variance works by comparing the variability in the sample means to the variability within each sample. We use the following statistics to measure these variabilities.
The greater the distance between the sample means, the larger the MSTR.
The larger the standard deviation of the k samples, the larger the MSE.
The mean square treatment (MSTR) measures the variability in the sample means. MSTR is the sample variance of the sample means, weighted by sample size.
MASTR=∑ni(ˉxi−ˉˉx)2k−1
where ni and ˉxi are the sample size and mean of the ith sample, ˉˉx is the overall sample mean, and there are k populations.
The mean square error (MSE) measures the variability within the samples. MSE is the mean of the sample variances, weighted by sample size.
MSE=∑(ni−1)s2ini−1
where ni and s2i are the sample size and variance of the ith sample, nt is the total sample size, and there are k populations.
We compare MSTR to MSE by taking the ratio of these two quantities. This ratio MSTR/MSE follows the F distribution that we learned about in Section 10.4.
The student may want to review the characteristics of the F distribution in Section 10.4.
The test statistic for analysis of variance is
Fdata=MSTRMSE
Fdata measures the variability among the sample means, compared to the variability within the samples. Fdata follows an F distribution with df1=k−1 and df2=nt−k, when the following requirements are met: (1) each of the k populations is normally distributed, (2) the variances of the populations are all equal, and (3) the samples are independently drawn.
The term mean square represents a weighted mean of quantities that are squared. Each mean square itself consists of two parts: the sum of squares in the numerator and the degrees of freedom in the denominator. The numerator for MSTR is called the sum of squares treatment (SSTR), and the numerator for MSE is called the sum of squares error (SSE).
MSTR=sum of squares treatmentdf1=SSTRdf1=∑ni(ˉxi−ˉˉx)2k−1MSE=sum of squares treatmentdf2=SSEdf2=∑(ni−1)s2int−k
The total sum of squares (SST) is found by adding SSTR and SSE:
SST=SSTR+SSE
The ANOVA table shown in Table 3 is a convenient way to display the various statistics calculated during an analysis of variance. Note that the quantities in the mean square column equal the ratio of the two columns to its left.
| Source of variation |
Sum of squares |
Degrees of freedom |
Mean square | F-test statistic |
|---|---|---|---|---|
| Treatment | SSTR | df1=k−1 | MSTR=SSTRk−1 | Fdata=MSTRMSE |
| Error | SSE | df1=nt−k | MSE=SSEnt−k | |
| Total | SST |
EXAMPLE 3 Constructing the ANOVA table
Use the summary statistics in Table 4 for the sample GPAs for Dorms A, B, and C to construct the ANOVA table.
| Dorm A | Dorm B | Dorm C | |
|---|---|---|---|
| Mean | ˉxA=2.2 | ˉxB=2.5 | ˉxC=2.8 |
| Standard deviation | sA≈1.133460777 | sB≈1.030857248 | sC≈09370284 |
| Sample size | n1=10 | n2=10 | n3=10 |
Solution
We have k=3 dormitories, and total sample size nt=10+10+10=30. Thus,
- SSTR=∑ni(ˉxi−ˉˉx)2=10(2.2−2.5)2+10(2.5−2.5)2+10(2.8−2.5)2=10[(−0.3)2+(0)2+(0.3)2]=1.8
- SSE≈(10−1)(1.33460777)2+(10−1)(1.030857248)2+(10−1)(0.9370284)2≈29.0288
- SST=SSTR+SSE=1.8+29.0288=30.8288
- MSTR=SSTRk−1=1.83−1=0.9
- MSE=SSEnt−k=29.028830−3=1.0781407407
- Fdata=MSTRMSE=0.91.0751407407=0.8370997079≈0.84
We summarize these calculations in the following ANOVA table, with the results rounded for clarity.
| Source of variation | Sum of squares | Degrees of freedom | Mean square | F-test statistic |
|---|---|---|---|---|
| Treatment | SSTR = 1.8 | df1=3−1=2 | MSTR=1.82=0.9 | Fdata=0.91.075≈0.84 |
| Error | SSE = 29.0288 | df2=30−3=27 | MSE=29.028827≈1.075 | |
| Total | SST = 30.8288 |
NOW YOU CAN DO
Exercises 15–22.
2 Performing One-way ANOVA
Now that we know how it works, we next learn how to perform ANOVA.
Remember: Ha is not stating that the population means are all different.
One-way Analysis of Variance
We have taken random samples from each of k populations and want to test whether the population means of the k populations are all equal.
Required conditions:
- Each of the k populations is normally distributed.
- The variances (σ2) of the populations are all equal.
- The samples are independently drawn.
Step 1 State the hypotheses, and state the rejection rule.
H0:μ1=μ2=⋯=μkversusHa:not all the population means are equal
where the µ represent the population mean from each population. The rejection rule is Reject if the .
Step 2 Calculate .
where
follows an distribution with and if the required conditions are satisfied, where represents the total sample size.
- Step 3 Find the -value. Use technology to find the , as shown in Figure 6.
- Step 4 State the conclusion and the interpretation. Compare the -value with .FIGURE 6 -Value for the one-way ANOVA test.
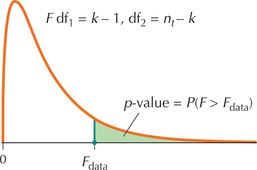
EXAMPLE 4 Performing one-way ANOVA using the -value method
Test, using level of significance , whether the population mean GPAs from Example 1 differ among the students in Dormitories A, B, and C.
What Result Might We Expect?
Recall that the comparison dotplot in Figure 1 (page 667) showed a large amount of overlap in the GPAs among dormitories A, B, and C. The large ranges illustrate the large within-dormitory spread of the GPAs for these dorms. When compared against this large within-sample variability, the variability in sample means may not seem large. Therefore, we might expect that the null hypothesis of no difference will not be rejected.
Solution
We already verified the requirements for performing the analysis of variance in Example 1.
Step 1 State the hypotheses, and state the rejection rule. Define the .
where represents the population mean GPA of students from dormitory . The rejection rule is Reject if the .
Step 2 Calculate . From Example 3, we have MSTR = 0.9, MSE = 1.0751407407, and
follows an distribution with and .
- Step 3 Find the -value. We use the instructions provided in the Step-by-Step Technology Guide at the end of this section (page 679). From Figures 7 and 8, we have
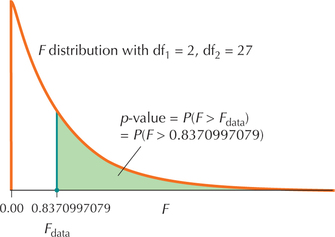 FIGURE 7 .
FIGURE 7 .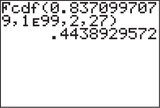 FIGURE 8 TI-83/84 -value.
FIGURE 8 TI-83/84 -value. - Step 4 State the conclusion and the interpretation. Compare the -value with . The -value of 0.4439 is not , so we do not reject . As expected, there is not enough evidence to conclude at level of significance that not all population mean GPAs are equal.
 When calculating the -value for analysis of variance, always retain as many decimal places in the value of as you can. This will make the -value as accurate as possible. Rounding too much will make the -value less accurate.
When calculating the -value for analysis of variance, always retain as many decimal places in the value of as you can. This will make the -value as accurate as possible. Rounding too much will make the -value less accurate.
NOW YOU CAN DO
Exercises 23–28.
EXAMPLE 5 Performing one-way ANOVA using technology

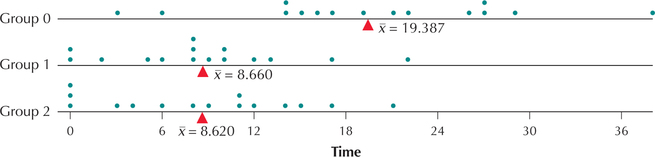
Researchers from the Institute for Behavioral Genetics at the University of Colorado investigated the effect that the enzyme protein kinase C (PKC) has on anxiety in mice. The genotype for a particular gene in a mouse (or a human) consists of two alleles (copies) of each chromosome, one each from the father and mother. The investigators in the study separated the mice into three groups. In Group 0, neither of the mice's alleles for PKC produced the enzyme. In Group 1, one of the two alleles for PKC produced the enzyme and the other did not. In Group 2, both PKC alleles produced the enzyme. To measure the anxiety in the mice, scientists measured the time (in seconds) the mice spent in the “open-ended” sections of an elevated maze. It was surmised that mice spending more time in open-ended sections exhibit decreased anxiety. The data are provided in Table 5. Use technology to test, at , whether the population mean time spent in the open-ended sections of the maze was the same for all three groups.
micemaze
| Group 0 | Group 1 | Group 2 | |||
|---|---|---|---|---|---|
| 15.8 | 14.4 | 5.2 | 7.6 | 10.6 | 9.2 |
| 16.5 | 25.7 | 8.7 | 10.4 | 6.4 | 14.5 |
| 37.7 | 26.9 | 0.0 | 7.7 | 2.7 | 11.1 |
| 28.7 | 21.7 | 22.2 | 13.4 | 11.8 | 3.5 |
| 5.8 | 15.2 | 5.5 | 2.2 | 0.4 | 8.0 |
| 13.7 | 26.5 | 8.4 | 9.5 | 13.9 | 20.7 |
| 19.2 | 20.5 | 17.2 | 0.0 | 0.0 | 0.0 |
| 2.5 | 11.9 | 16.5 | |||
What Result Might We Expect?
Figure 9 shows a plot of the time in open-ended sections for the mice in the three groups. Note that the Group 1 and Group 2 mice spent on average about the same amount of time in the open-ended sections but that Group 0 spent on average somewhat more time in the open-ended sections. This would tend to suggest that the null hypothesis that all three population means are equal should be rejected. Remember that to reject , it is sufficient for just one of the population means to be different.
Solution
We use the instructions provided in the Step-by-Step Technology Guide at the end of this section (page 679). We frst verify whether the requirements are met.
- The normal probability plots in Figure 10 indicate acceptable normality.
The group standard deviations are , , and . Thus, the largest standard deviation is not greater than twice the smaller, which verifies the equal variances requirement.
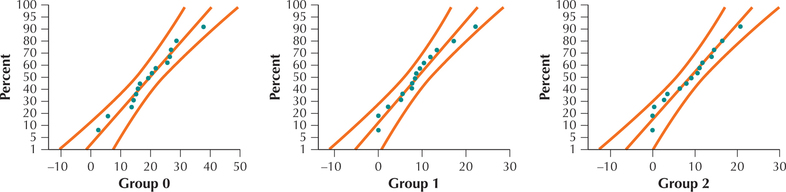 FIGURE 10 Normal probability plots.Page 676
FIGURE 10 Normal probability plots.Page 676- The selection of a mouse to a particular group did not affect the selection of mice to the other groups, so that the samples are independent.
Thus, we proceed with the one-way ANOVA.
where the represent the population mean time spent in the open-ended sections of the maze for each group.
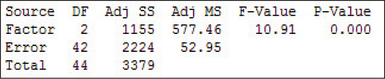
Figure 11 contains the results from the TI-83/84, showing where each statistic corresponds to the ANOVA table structure in Table 3. We have , with a -value of "1.5320224E4" = 0.00015320224. This -value is less than , so we reject . There is evidence at level of significance that the population mean times in the open-ended sections of the maze are not equal for all three groups.
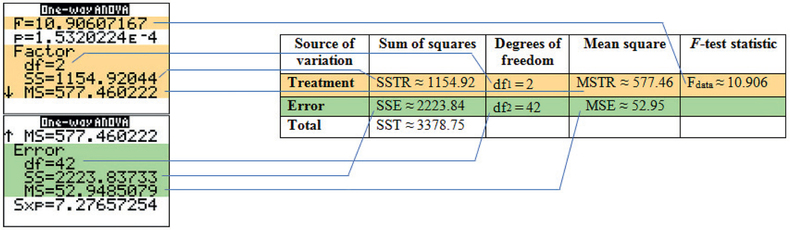
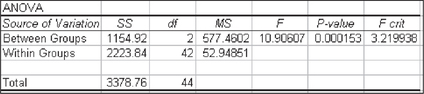
Figure 12 contains the Excel ANOVA results, Figure 13 contains the Minitab ANOVA results, and Figure 14 contains the JMP ANOVA results. Values differ slightly due to rounding.
One-way ANOVA may also be conducted using the critical-value method. The conditions are the same as for the -value method.
EXAMPLE 6 Performing one-way ANOVA using the critical-value method
micemaze
Use the data from Example 5 to test, using the critical-value method and level of significance , whether the population mean time spent in the open-ended sections of the maze was the same for all three groups.
Solution
The conditions for performing ANOVA were verified in Example 5.
Step 1 State the hypotheses.
where the represent the population mean time spent in the open-ended sections of the maze for each group.
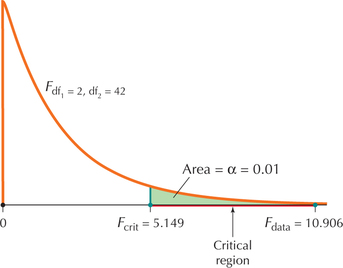
- Step 2 Find the critical value and state the rejection rule. The one-way ANOVA test is a right-tailed test, so the -critical value is the value of the distribution for and that has area to the right of it (see Figure 16). Here, and . To find , we may use the F tables or technology. To find our using Excel, enter = FINV(0.01,2,42) in cell A1, as shown in Figure 15. Thus, . ANOVA is a right-tailed test, so we will reject if .FIGURE 15 Using Excel to find the critical value.

- Step 3 Calculate . From Example 5, we have .
- Step 4 State the conclusion and interpretation. Because (Figure 16), we reject . There is evidence that not all population mean times spent in the open-ended sections of the maze are equal.FIGURE 16 has area of to the right of it.
NOW YOU CAN DO
Exercises 29–30.
Developing Your Statistical Sense
Do Not Draw the Wrong Conclusion
Note that we did not conclude that all three population means are different. As long as one mean is sufficiently different from the other two, we would reject . Our conclusion was simply that the population means were not all equal.
Also, we cannot yet formally conclude that Group 0 has a larger population mean time than the other groups, even though Figure 9 seems to indicate so. All we can formally conclude at this point is that not all the population means are equal. In Section 12.2, we will learn multiple comparisons, which is the type of analysis needed to test whether the mean of Group 0 is larger than the others.

 Professors on Facebook
Professors on Facebook
A recent study investigated whether the amount of information a professor posts about himself or herself (that is, self-disclosure) on the online social network Facebook is related to student motivation. A professor constructed three different Facebook sites, one offering low self-disclosure, one offering medium self-disclosure, and one offering high self-disclosure. For example, the low-disclosure site offered information only about her position at the university. The medium-disclosure site also showed the professor's favorite movies, books, and quotes. On the high-disclosure site, fictitious comments from “friends” were posted on “the Wall,” highlighting social gatherings.
Study participants (students not enrolled in the professor's courses) were then randomly assigned to access and browse one of the three Facebook sites, develop an impression of the professor, and complete the research questionnaire. Student motivation was measured using a set of 16 items, and the sum of the 16 items was calculated to form the total motivation score. The items measured student interest, involvement, stimulation, level of excitement, and whether the student was inspired or challenged. Use technology to test, at , whether the population mean motivation scores are equal for the three types of Facebook pages: low, medium, and high self-disclosure.
Solution
First, we verify whether the requirements are satisfied.
- The normal probability plots in Figure 17 indicate acceptable normality.
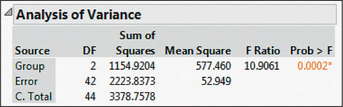
- The standard deviations are shown in blue in the Minitab output in Figure 18.
- The lamest, , is not larger than twice the smallest, . Thus, the equal-variance requirement is satisfied.
- The student participants were randomly selected for each level of self-disclosure, so the independence assumption is also validated.
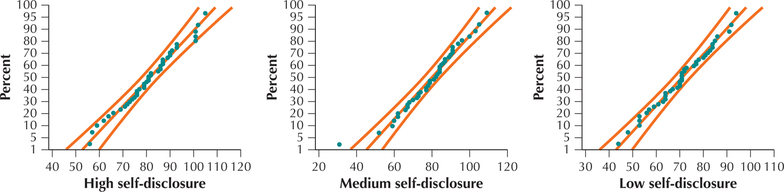 FIGURE 17 Normal probability plots.FIGURE 18 Minitab output for Facebook ANOVA.
FIGURE 17 Normal probability plots.FIGURE 18 Minitab output for Facebook ANOVA.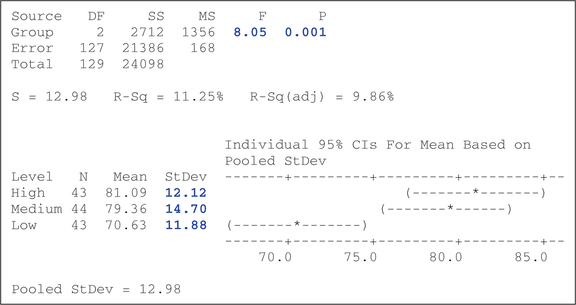
We therefore proceed with the ANOVA. The hypotheses are
where represents a population mean motivation score for each self-disclosure level. Reject if the -value is less than .
From Figure 18, we get , with an associated -value of approximately 0.001 (shown in blue). This -value is less than , so we reject . There is evidence that not all population mean motivation scores are equal across all levels of self-disclosure. Informally, we may observe that the mean motivation score for the Facebook Web site with low self-disclosure seems lower than the other groups. We test this formally in Section 2.
![]() The Analysis of Variance applet allows you to experiment with various values for the sample means and the sample variability in order to see how changes in these values affect and the -value.
The Analysis of Variance applet allows you to experiment with various values for the sample means and the sample variability in order to see how changes in these values affect and the -value.